
scrapy采集—爬取中文乱码,gb2312转为utf-8
有段时间没怎么使用scrapy了,最近采集一个网页,发现网页编码是gb2312,
一开始就取搜索了下,发现各种操作都有,有在settings中设置
# FEED_EXPORT_ENCODING = 'utf-8'
FEED_EXPORT_ENCODING = 'GB2312'
有在spider中设置response.body的encoding的,而我用的是response.xpath,到这里发现问题也还是不能够解决,
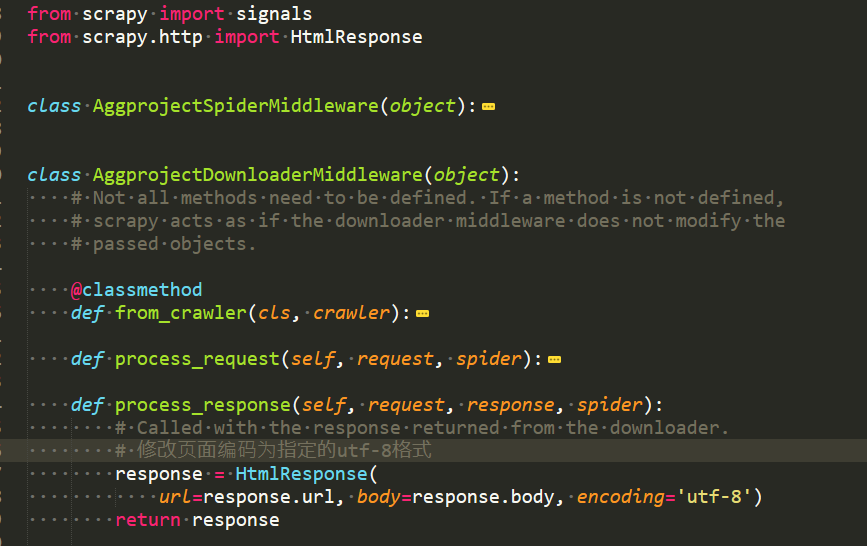
最后发现 在Download MinddleWares中有个process_response方法,在下载器中间件中将返回的请求数据修改编码即可完成
response = HtmlResponse(url=response.url, body=response.body, encoding='utf-8')
return response

 浙公网安备 33010602011771号
浙公网安备 33010602011771号