变截距面板数据模型
变截距面板数据模型理论介绍
混合效应模型
背景思想
回归公式可以忽略个体与时间变化的差异,因此所有的数据特征可以通过一个公式进行刻画。进行数据的大杂烩、乱炖。为什么采取这么直接粗暴的方式呢?因为每个品种的菜(个体与时间维度)都很少,每一个品种的菜都不能够做出完整一盘菜,只能将所有的菜杂七杂八的混合起来乱炖。乱炖虽说精度不高,可是总比没法处理要好很多。
模型假定
1.E(εit)=0;
2.var(ε)=σε为常数;
3. εit与Xit不相关;
公式:
Yit=α+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| α |
截距项 |
| εit |
随机扰动项 |
估计方法展示
数据结构展示:
估计方法:
这个模型是将所有的数据(y,x1,x2,x3,x4),直接导入公式Yit=α+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T进行回归,只能求出一组(β1,β2,..,βk)′,意味着β在不同个体、不同时点上都是同一组,它不会因为时间或个体而发生变动。
固定效应模型
背景思想
当你拥有蔬菜的品种足够多,你就可以依据他们的味道单独做一些小炒菜。有一些影响因素A随着一些条件的改变而改变,但是这个因素A并未通过X观测变量纳入模型,比如说我们研究消费函数,C=α+βY+ε, 这里的α叫做自发消费,这个自发性消费是可能和个人特征、所处的社会文化、教育等未观测变量有关,换句话说,截距项 α 和个体某些未观测到的特质有关,而不和Y有关。α和ε都是代表了不可观测因素的影响,前者的影响因素是有趋势的(常数也是一种趋势),后者的影响因素是无趋势的。更简单的理解就是,α存在的意义就是为了使ε拥有零均值。
- 当这个截距项与个体特征相关时,我们称为个体固定效应模型。
- 当这个截距项与时间特征有关时,我们称为时间固定效应模型。
- 同理,和A潜在变量有关,我们就可以称它为A的固定效应模型。
- 当这个截距项与个体特征和时间特征都相关时,我们称为双固定效应模型。
- 同理,也可以同时依据三种或三种以上的变量进行分类,回归得出它们影响的截距项的估计值。
个体固定效应模型
模型假设
1.E(εit)=0;
2.var(ε)=σε为常数;
3 εit与Xit不相关;
4. αi与Xit相关
5. E(αi)=0
模型公式
Yit=α0+αi+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| α0 |
常数项 |
| αi |
个体效应 |
| α0+αi |
截距项 |
| εit |
随机扰动项 |
| 补充:也写为 |
|
| Yit=ui+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T |
|
| ui=α0+αi,E(ui)=α0,E(αi)=0 |
|
估计方法展示
数据结构如下:
1.组内(within)估计(离差估计)
离差估计就是剔除常数项,然后进行估计,首先明白我们的目标:分别计算a,b,c,d,e组内的截距和各自的组内β .其实,不需要离差就可以回归。将a,b,c,d,e组的数据分别带入Yit=α0+αi+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T,就可以得到结果。
-
离差方差推导
原方程:
Yit=α0+αi+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
求均值方程:
¯Yi=α0+αi+¯X′iβ+¯εi,i=1,2,3,...,N;t=1,2,3,...,T
离差变换(原方程减均值方程):
Yit−¯Yi=α0+αi−(α0+αi)+X′itβ−¯X′iβ+εit−¯εi=X′itβ−¯X′iβ+εit−¯εi,i=1,2,3,...,N;t=1,2,3,...,T
¯Yi=1TT∑t=1(Yit)
¯Xi=1TT∑t=1(Xit)
-
带入离差数据求解,文字描述
通过(y,x1,x2,x3,x4)计算组内时间上的均值¯(y,x1,x2,x3,x4),然后计算离差(y,x1,x2,x3,x4)−¯(y,x1,x2,x3,x4),带入离差方程Yit−¯Yi=X′itβ−¯X′iβ+εit−¯εi,i=1,2,3,...,N;t=1,2,3,...,T进行估计。
-
利用估计出的β带入均值方程¯Yi=α0+αi+¯X′iβ+¯εi,i=1,2,3,...,N;t=1,2,3,...,T,求解组内的(α0+αi)
-
通过上一步N个组的(α0+αi),求解α0=1NN∑t=1(α0+αi),依据假设5:E(αi)=0
-
再求解αi=(α0+αi)−α0
2.一阶差分估计
原理: 因为α0+αi是不受时间影响的,所以我们可以使用差分方法消去常数项
- 差分方程推导
原方程:
Yit=α0+αi+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
上一期方程:
Yi,t−1=α0+αi+X′i,t−1β+εi,t−1,i=1,2,3,...,N;t=1,2,3,...,T
原方程减上一期方程:
Yit−Yi,t−1=α0+αi+X′itβ+εit−α0−αi−X′i,t−1β−εi.t−1=X′itβ−X′i,t−1β+εit−εi,t−1
- 数据代入求解即可。
- 此方法无法求解截距项。
3.LSDV(最小二乘虚拟变量法)
学过计量的小伙伴们应该熟悉虚拟变量法,将个体差异以截距项形式的虚拟变量加入。
估计方程形式:
Y=Dα+Xβ+ε
D=(D1D2D3...DN)
其中:
DN={1if 为N组0if 不为N组
时点固定效应模型
模型假设
1.E(εit)=0;
2.var(ε)=σε为常数
3 εit与Xit不相关;
4. λt与Xit相关;
模型公式
Yit=λ0+λt+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| λ0 |
常数项 |
| λt |
时间效应 |
| λ0+λt |
截距项 |
| εit |
随机扰动项 |
估计方法展示
数据结构如下:
LSDV(最小二乘虚拟变量法)
学过计量的小伙伴们应该熟悉虚拟变量法,将时间段以截距项形式的虚拟变量加入。
估计方程形式:
Y=Dλ+Xβ+ε
D=(D1D2D3...DT)
其中:
DT={1if 为T时期0if 不为T时期
个体时点固定效应模型
模型假设
1 E(εit)=0;
2 var(ε)=σε为常数
3 εit与Xit不相关;
4 λt与Xit相关;
5 αi与Xit相关;
6 E(αi)=0;
7 E(λt)=0;
这里我们设定:
~αi=α0+αi;~λt=λ0+λt;
8 E(~αi)=α0;
9 E(~λt)=λ0;
模型公式
Yit=(α0+λ0)+αi+λt+X′itβ+εit
=α0+αi+λ0+λt+X′itβ+εit
=~αi+~λt+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| λ0 |
时间效应的常数项 |
| λt |
时间效应 |
| α0 |
个体特征的常数项 |
| αi |
个体效应 |
| α0+αi+λ0+λt |
截距项 |
| εit |
随机扰动项 |
估计方法
数据结构展示:

LSDV(最小二乘虚拟变量法)
学过计量的小伙伴们应该熟悉虚拟变量法,将时间段以截距项形式的虚拟变量加入。
-
估计方程形式:
Y=Dλλ+Dαα+Xβ+ε
Dλ=(D1D2D3...DT)
其中:
DT={1if 为T时期0if 不为T时期
Dα=(D1D2D3...DN)
其中:
DN={1if 为N组0if 不为N组
-
也可以将时间与个体效应混合
Y=Dh+Xβ+ε
D=(D1D2D3...DN∗T)
其中:
D={1if 为第N个体的T时期0if 不为第N个体的T时期
个体时点双固定效应,控制区域、行业等模型
模型假设
1 E(εit)=0;
2 var(ε)=σε为常数
3 εit与Xit不相关;
4 λt与Xit相关;
5 αi与Xit相关;
6 E(αi)=0;
7 E(λt)=0;
这里我们设定:
~αi=α0+αi;~λt=λ0+λt;
8 E(~αi)=α0;
9 E(~λt)=λ0;
模型公式
Yit=~αi+~λt+Dtypeγ+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
这个方程为了方便理解而设定,其中~αi与Dtype存在共线性问题,毕竟类型属性也是个体特征的一部分嘛!
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| λ0 |
时间效应的常数项 |
| λt |
时间效应 |
| α0 |
个体特征的常数项 |
| αi |
个体效应 |
| α0+αi+λ0+λt |
截距项 |
| εit |
随机扰动项 |
| Dtype |
类型的虚拟变量 |
估计方法展示
数据展示
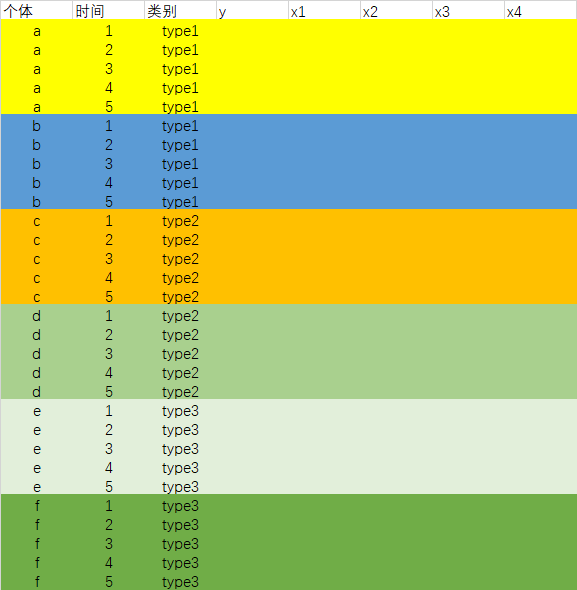
估计方法:同上,将类型变量按照虚拟变量加入方程即可。
随机效应模型
背景思想:每组估计值的截距项的变动不与X的特征有关。
个体随机效应
模型假设
1.E(εit)=0;
2.var(σε)为常数;
3 εit与Xit不相关;
4. αi与Xit,εit不相关;
5. αi∼i.i.d(0,σ2α);
公式:
Yit=α0+αi+X′itβ+εit,i=1,2,3,...,N;t=1,2,3,...,T
=α0+X′itβ+(αi+εit),i=1,2,3,...,N;t=1,2,3,...,T
=α0+X′itβ+vit,vit=αi+εit,i=1,2,3,...,N;t=1,2,3,...,T
| 项目 |
含义 |
| i |
个体标志序数 |
| t |
时间序数 |
| Xit |
观测变量,K∗1向量,(X1it,,X2it,..,Xkit)′ |
| β |
参数,K∗1向量, (β1,β2,..,βk)′ |
| α0 |
常数项 |
| αi |
随机效应 |
| α0+αi |
截距项 |
| εit |
随机扰动项 |
| vit=αi+εit |
新的随机扰动项 |
根据vit=αi+εit;αi∼i.i.d(0,σ2α);αi与Xit,εit不相关;var(ε)=σε为常数
推导:
cov(vit,vis)=cov(αi+εit,αi+εis)=cov(αi,αi+εis)+cov(εit,αi+εis)=cov(αi,αi)+cov(αi,εis)+cov(εit,αi)+cov(εit, εis)={σ2αif t≠sσ2α+σεif t=s
所以不满足古典假定,存在异方差与自相关问题。
估计方法展示
模型设定检验
F检验(chow's test)
原假设:混合回归模型
备择假设:其他模型
以个体固定效应模型为例:Yit=ui+X′itβ+εit
原假设:u1=u2=...=uN (存在约束,截距不会变)
Yit=ui+X′itβ+εit
计算回归的RSSr
备择假设:u1,u2,...,uN不全相等 (无约束,截距会变)
Yit=ui+X′itβ+εit
计算回归的RSSu
F统计量构造:
F=(RSSr−RSSu)/[(NT−k−1)−(NT−k−N)]RSSu/(NT−k−N)∼F(N−1,NT−k−N)
| 项目 |
含义 |
| RSSr |
有约束模型的残差平方和(混合模型,有约束) |
| RSSu |
无约束模型的残差平方和(变截距模型) |
| k |
解释变量个数 |
LR检验
原假设:混合回归模型
备择假设:其他模型
以个体固定效应模型为例:Yit=ui+X′itβ+εit
原假设:u1=u2=...=uN (存在约束,截距不会变)
Yit=ui+X′itβ+εit
计算回归的最大似然函数值的对数ln(Lr)
备择假设:u1,u2,...,uN不全相等 (无约束,截距会变)
Yit=ui+X′itβ+εit
计算回归的最大似然函数值的对数ln(Lu)
LR统计量构造:
LR=−2(lnLr−lnLu)渐近服从χ2(约束条件的个数:N−1)
豪斯曼检验(Hauseman's test)
原假设:个体随机效应模型(个体效应与回归变量无关)
备择假设:个体固定效应模型(个体效应与回归变量有关)
检验的原理:
利用组内估计(within),无论是随机效应模型的参数估计值还是固定效应模型的参数估计值,估计参数值都是一致的
利用广义最小二乘法,对随机效应模型的参数估计值是一致的,对于随机效应模型的参数估计值是不一致的
| 真实模型 |
组内估计^βw |
广义最小二乘法~βre |
| 随机效应模型 |
一致估计量 |
非一致估计量 |
| 固定效应模型 |
一致估计量 |
一致估计量 |
检验逻辑图:
变截距面板数据模型建模步骤





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!