


java:LeakFilling(Other)
1.Java项目的API文档如何生成?请将步骤写出。
javadoc 源文件名.java;
2.增加package以后,我们在DOS下编译怎么做?
javac -d . Test.java
3.Javabean就是只包含属性和相关getter、setter方法,不包含业务逻辑处理的 类,这种说法对吗?
不对
Javabean既可以封装数据同时也可以封装业务逻辑
4.假如父类有main方法,子类能不能继承?
不能
5.多态的三个必要条件是什么?
继承
方法重写
父类引用指向子类对象
6.多态的常用使用场合有哪些?
使用父类做方法的形参,实参可以是该父类的任意子类类型
使用父类做方法的返回值类型,返回值可以改父类的任意子类对象
7.Java的方法绑定采用动态绑定还是静态绑定?
静态绑定:静态方法,构造器,private方法,用关键字super调用的方法是
动态绑定:通过对象调用的方法
8.接口描述了现实世界中什么逻辑?
接口描述了现实世界是“如果你是…则必须能..”的思想
如果你是天使,则必须能飞;如果你是汽车,则必须能跑
9.接口中有没有多继承?
接口中有多继承
10.二维数组求和:
public static void main(String[] args){ int sum=0; int [] [] arr={{3,2},{2}}; for (int i = 0; i < arr.length; i++) { for (int j = 0; j < arr[i].length; j++) { sum+=arr[i][j]; } } System.out.println(sum); }
11.为什么需要包装类?包装类的作用是?
因为java语言是面向对象的语言,但是java中的基本数据类型却不是面向对象的,而在实际的使用中经常需要将基本数据转化成对象,便于操作。比如说在集合中存储数据时,只能存储对象
作用:
[1]作为和基本数据类型对应的类类型存在,方便涉及到对象的操作
[2]包含每种基本数据类型相关的属性以及相关的操作方法
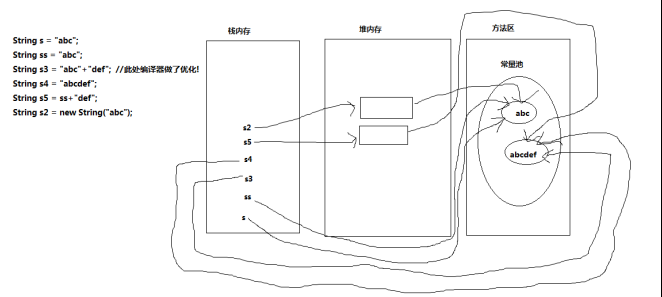
12.为什么String类被称为不可变字符序列?从String类的源代码分析,给出解释。
字符串是常量,它们的值在创建之后不能更改,String对象是不可变的,所以可以共享
String类的底层结构是char类型的数组value,而这个数组使用final进行修饰
13.String类的trim()方法是什么作用?
返回字符串的副本,去掉字符串前后的空格
14.
15.File类的方法mkdir跟mkdirs,有什么区别?
mkdir:只能在已经存的目录中创建文件夹
mkdirs:可以在不存的目录中创建文件夹
16.什么时候使用枚举? 枚举的定义是什么?
当需要定义一组常量时,使用枚举类型
枚举的定义:
只能够取特定值中的一个
使用enum关键字
所有的枚举类型隐性地继承自java.lang.Enum
17.想取两个容器中元素的交集,使用哪个方法?
retainAll(Collection c): 只保留当前集合(调用此方法的集合)与集合c(此方法的参数)中相同的元素。
18.equals返回true,hashcode一定相等吗?
是的。
19.资源文件有什么作用?
资源文件是用来配置信息的,如数据库信息,键值对信息等。程序里需要有个方法来读取资源文件中的配置信息。如果没有资源文件,配置信息就得写在代码里;需要修改信息时就不得不修改代码。有了资源文件之后,一旦信息需要改变,修改资源文件就可以,不用修改代码,更好的保证了代码的封装性。
20.Vector和ArrayList的区别和联系
实现原理相同,功能相同,都是长度可变的数组结构,很多情况下可以互用
两者的主要区别如下
1)Vector是早期JDK接口,ArrayList是替代Vector的新接口
2)Vector线程安全,ArrayList重速度轻安全,线程非安全
3)长度需增长时,Vector默认增长一倍,ArrayList增长50%
21.Hashtable和HashMap的区别联系
实现原理相同,功能相同,底层都是哈希表结构,查询速度快,在很多情况下可以互用
两者的主要区别如下
1)Hashtable是早期JDK提供的接口,HashMap是新版JDK提供的接口
2)Hashtable继承Dictionary类,HashMap实现Map接口
3)Hashtable线程安全,HashMap线程非安全
4)Hashtable不允许null值,HashMap允许null值
22.Java主要容器的选择依据和应用场合
(1) HashTable,Vector类是同步的,而HashMap,ArrayList不是同步的。 因此当在多线程的情况下,应使用 HashTable和 Vector,相反则应使用HashMap,ArrayList.
(2) 除需要排序时使用TreeSet,TreeMap外,都应使用HashSet,HashMap,因为他们 的效率更高。
(3) ArrayList 由数组构建, LinkList由双向链表构建,因此在程序要经常添加,删除元素时速度要快些,最好使用LinkList,而其他情况下最好使用ArrayList.因 为他提供了更快的随机访问元素的方法。
23.字节流和字符流有什么区别?输入流和输出流有什么区别?
字符流和字节流是流的一种划分,按照处理流的数据单位进行的划分。两类都分为输入和输出操作。在字节流中输出数据主要是使用OutputStream完成,输入使用的是InputStream,在字符流中输出主要是使用Writer类完成,输入流主要使用Reader类完成。这四个都是抽象类。字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。字节流是最基本的,所有的InputStrem和OutputStream的子类都是字节流,主要用在处理二进制数据,它是按字节来处理的。但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的编码来处理,也就是要进行字符集的转化,这两个之间通过 InputStreamReader,OutputStreamWriter(转换流)来关联,实际上是通过byte[]和String来关联的。
流就像管道一样,在程序和文件之间,输入输出的方向是针对程序而言,向程序中读入东西,就是输入流,从程序中向外读东西,就是输出流。输入流是得到数据,输出流是输出数据。
24.节点流和处理流有什么区别?
节点流和处理流是流的另一种划分,按照功能不同进行的划分。节点流,可以从或向一个特定的地方(节点)读写数据。处理流是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如BufferedReader。处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
25.word文档能使用字符流操作吗?为什么?
不能。因为word文档不是纯文本文件,除了文字还包含很多格式信息。不能用字符流操作。可以用字节流操作。
26.InputStream和OutputStream基本特点是?
二者都是【字节】输入输出流的抽象父类。以字节为单位处理数据,每次读取/写入一个字节。适合处理二进制文件,如音频、视频、图片等。实现类有FileInputStream和FileOutputStream等。
27.Reader和Writer的基本特点是?
二者都是【字符】输入输出流的抽象父类。以字符为单位处理数据,每次读取/写入一个字符。适合处理文本文件。实现类有FileReader和FileWriter等。
28.PrintStream打印流经常用于什么情况? System.out 是不是打印流?
PrintStream:字节打印流,是OutputStream的实现类。提供了多个重载的print,println等方法,可以方便地向文本文件中写入数据。
System.out是字节打印流(PrintStream的对象),它被称作标准的输出流,输出的目的地是标准的输出设备,即显示器。所以,当我们使用System.out.print或System.out.println时会向屏幕(显示器)输出数据。

29.DataInputStream和DataOutputStream的特点是?
二者都是处理流,要以一个节点流为参数;二者被称为数据流,是用来操作基本数据类型的。用DataInputStream写入一个类型的数据,用DataOutputStream读出数据时可以保持类型不变。如用DataInputStream写入一个int类型的数据,用DataOutputStream读出来的还是一个int数据,即可以直接当作int类型的数据来进行操作,不用做任何转换。
数据流特点:
(1)写入是什么类型的数据,读出是相应类型的数据;
(2)要先写后读;用DataOutputStream流写,用DataInputStream流读;
(3)读写顺序要一致,否则会报EOF异常;EOF:end of file;
(4)数据流可以跨平台写入和读出,适合网路应用。
30.说说sierializable接口的特点。
1. 需要被序列化的对象的类必须实现Serializable接口。
2. 给类加个序列化编号,即给类定义一个标记,如:
public static final long serialVersionUID=1L;
新的修改后的类还可以操作曾经序列化的对象。
3、静态是不能被序列化的,
序列化只能对堆中的对象进行序列化 ,不能对”方法区”中的对象进行序列化。
4、不需要序列化的字段前加 transient,如:
private transient String password;
31.程序、进程、线程的区别是什么? 举个现实的例子说明。
程序(Program):是一个指令的集合。程序不能独立执行,只有被加载到内存中,系统为它分配资源后才能执行。
进程(Process):如上所述,一个执行中的程序称为进程。
进程是系统分配资源的独立单位,每个进程占有特定的地址空间。
程序是进程的静态文本描述,进程是程序在系统内顺序执行的动态活动。
线程(Thread):是进程的“单一的连续控制流程“。
线程是CPU调度和分配的基本单位,是比进程更小的能独立运行的基本单位,也被称为轻量级的进程。
线程不能独立存在,必须依附于某个进程。一个进程可以包括多个并行的线程,一个线程肯定属于一个进程。Java虚拟机允许应用程序并发地执行多个线程。
举例:如一个车间是一个程序,一个正在进行生产任务的车间是一个进程,车间内每个从事不同工作的工人是一个线程。
32.Thread类有没有实现Runnable接口?
有实现。
33.mybatis实现mapper四个必要:
1.mapper.java的方面名要和mapper.xml一致
2.参数一直
3.参数类型。
4.返回值一致。
5.mapper.java文件名和mapper.xml文件名保持一致
34.controller中返回string和list的区别:
35.mvc原理:
请求被UrlRoutingModule部件拦截
封装请求上下文HttpContext,成为HttpContextWrapper对象。
根据当前的HttpContext,从Routes集合中得到与当前请求URL相符合的RouteData对象。
将RouteData与HttpContext请求封装成一个RequestContext对象。
根据RequestContext对象,从RouteData的RouteHandler中获取IHttpHandler(MVC里面会有一个IHttpHandler的实现类MvcHandler)。
执行IHttpHandler(MvcHandler),然后就是通过反射激活具体的controller,执行具体的action。
36.数据库定义存储过程和函数的区别:
存储过程:
存储过程可以使得对数据库的管理、以及显示关于数据库及其用户信息的工作容易得多。存储过程是 SQL 语句和可选控制流语句的预编译集合,以一个名称存储并作为一个单元处理。存储过程存储在数据库内,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其它强大的编程功能。
存储过程可包含程序流、逻辑以及对数据库的查询。它们可以接受参数、输出参数、返回单个或多个结果集以及返回值。
可以出于任何使用 SQL 语句的目的来使用存储过程,它具有以下优点:
1、可以在单个存储过程中执行一系列 SQL 语句。
2、可以从自己的存储过程内引用其它存储过程,这可以简化一系列复杂语句。
3、存储过程在创建时即在服务器上进行编译,所以执行起来比单个 SQL 语句快。
用户定义函数:
Microsoft SQL Server 2000 允许创建用户定义函数。与任何函数一样,用户定义函数是可返回值的例程。根据所返回值的类型,每个用户定义函数可分成以下三个类别:
1、返回可更新数据表的函数
如果用户定义函数包含单个 SELECT 语句且该语句可更新,则该函数返回的表格格式结果也可以更新。
2、返回不可更新数据表的函数
如果用户定义函数包含不止一个 SELECT 语句,或包含一个不可更新的 SELECT 语句,则该函数返回的表格格式结果也不可更新。
3、返回标量值的函数
用户定义函数可以返回标量值。
区别:
1.一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2.对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
3.存储过程一般是作为一个独立的部分来执行,而函数可以作为查询语句的一个部分来调用,由于函数可以返回一个表对象,因此它可以在查询语句中位于FROM关键字的后面。
4.当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存储过程和函数进行编译。
37.JAVA WEB后台、IOS、Android之间的通讯解决方案:
1. soap协议
2. 纯http协议,以请求参数的键值形式发送请求参数,以json响应
3. 纯http协议,请求响应参数都是json
4. RESTful,请求响应参数可以参考2、3
5. 还有一种方式自己基于http协议定义传输方案,用的应该不多。如果你要用可以考虑使用MessagePack作为数据序列化/反序列化方案
7. 连http也不用了,基于socket实现传输方案,估计除了公司内部通讯应该不会有人采用
个人认为第一种过于沉重,随着功能越来越复杂,传输的报文会越来越大。xml本身就是一个沉重的东西。
第二种比较容易,对于服务器来说最简单,不过客户端要自己拼请求参数,不是很方便
第三种比第二种稍微复杂的在于,每次请求都要指定Content-Type:text/json。否则服务器会收不到请求参数或出错。
第四种,网上有很多文章也很推崇。但是由于跟传统的mvc方式差异巨大,没有了解过的人理解比较困难。曾经跟同事讲过这种模式,所有人都一脸茫然。
第五种,可以基于http协议+MessagePack传输二进制数据,这是前面五种方式效率最高,传输字节数最少的方式。不过由于MessagePack本身的限制,传输对象时可能不够灵活,一个对象的全部属性都要被序列化,而不能选择序列化。如果要定制传输的数据,就要调用它的底层api,比较麻烦。
使用第二、第五种方式,还可以实现只需要开放一个uri,就能实现全部客户端与服务器的交互。只需要根据参数值决定具体要访问哪个模块和模块里的哪个操作。如果设计的好,可以做到很灵活,而且也能达到理想的低耦合高内聚。
