Dubbo 源码分析
1、源码下载和编译
源码下载、编译和导入步骤如下:
- dubbo的项目在github中的地址为: https://github.com/apache/dubbo
- 进入需要进行下载的地址,执行git clone https://github.com/apache/dubbo.git
- 为了防止master中代码不稳定,进入dubbo项目,cd dubbo 可以切入到最近的release分支,git checkout 2.7.6-release
- 进行本地编译,进入dubbo项目 cd dubbo , 进行编译操作 mvn clean install -DskipTests
- 使用IDE引入项目。
2、架构整体设计
2.1 整体设计
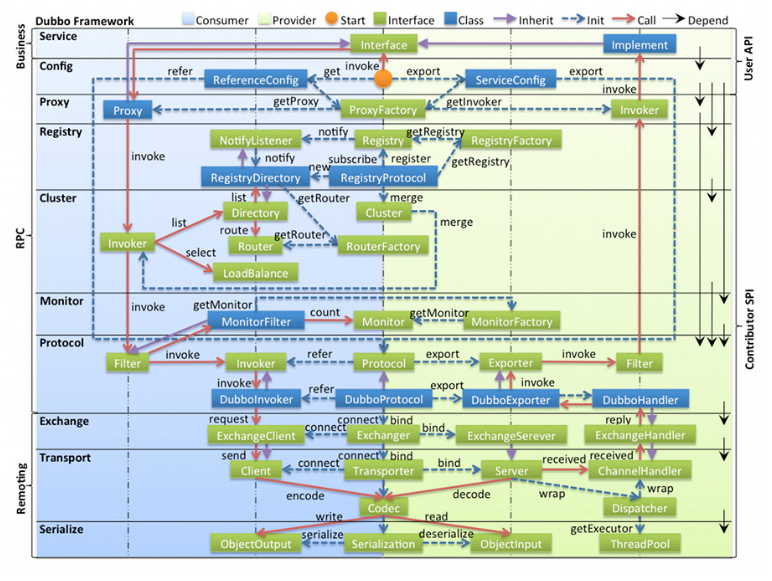
图例说明:
- 图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
- 图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
- 图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类。
- 图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法。
2.2 各层说明
- config 配置层:对外配置接口,以
ServiceConfig,ReferenceConfig为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类 - proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以
ServiceProxy为中心,扩展接口为ProxyFactory - registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为
RegistryFactory,Registry,RegistryService - cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以
Invoker为中心,扩展接口为Cluster,Directory,Router,LoadBalance - monitor 监控层:RPC 调用次数和调用时间监控,以
Statistics为中心,扩展接口为MonitorFactory,Monitor,MonitorService - protocol 远程调用层:封装 RPC 调用,以
Invocation,Result为中心,扩展接口为Protocol,Invoker,Exporter - exchange 信息交换层:封装请求响应模式,同步转异步,以
Request,Response为中心,扩展接口为Exchanger,ExchangeChannel,ExchangeClient,ExchangeServer - transport 网络传输层:抽象 mina 和 netty 为统一接口,以
Message为中心,扩展接口为Channel,Transporter,Client,Server,Codec - serialize 数据序列化层:可复用的一些工具,扩展接口为
Serialization,ObjectInput,ObjectOutput,ThreadPool
2.3 关系说明
- 在 RPC 中,Protocol 是核心层,也就是只要有 Protocol + Invoker + Exporter 就可以完成非透明的 RPC 调用,然后在 Invoker 的主过程上 Filter 拦截点。
- 图中的 Consumer 和 Provider 是抽象概念,只是想让看图者更直观的了解哪些类分属于客户端与服务器端,不用 Client 和 Server 的原因是 Dubbo 在很多场景下都使用 Provider, Consumer, Registry, Monitor 划分逻辑拓普节点,保持统一概念。
- 而 Cluster 是外围概念,所以 Cluster 的目的是将多个 Invoker 伪装成一个 Invoker,这样其它人只要关注 Protocol 层 Invoker 即可,加上 Cluster 或者去掉 Cluster 对其它层都不会造成影响,因为只有一个提供者时,是不需要 Cluster 的。
- Proxy 层封装了所有接口的透明化代理,而在其它层都以 Invoker 为中心,只有到了暴露给用户使用时,才用 Proxy 将 Invoker 转成接口,或将接口实现转成 Invoker,也就是去掉 Proxy 层 RPC 是可以 Run 的,只是不那么透明,不那么看起来像调本地服务一样调远程服务。
- 而 Remoting 实现是 Dubbo 协议的实现,如果你选择 RMI 协议,整个 Remoting 都不会用上,Remoting 内部再划为 Transport 传输层和 Exchange 信息交换层,Transport 层只负责单向消息传输,是对 Mina, Netty, Grizzly 的抽象,它也可以扩展 UDP 传输,而 Exchange 层是在传输层之上封装了 Request-Response 语义。
- Registry 和 Monitor 实际上不算一层,而是一个独立的节点,只是为了全局概览,用层的方式画在一起。
2.4 模块分包
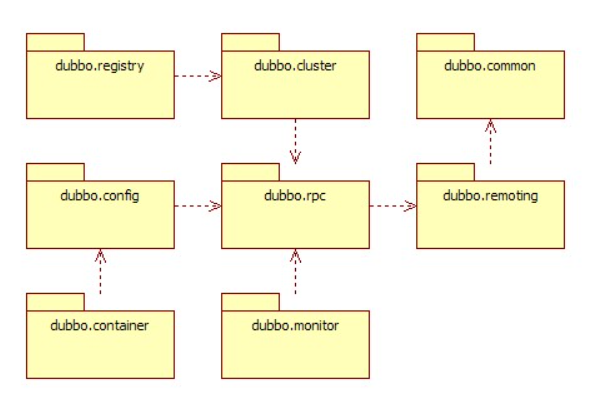
模块说明:
- dubbo-common 公共逻辑模块:包括 Util 类和通用模型。
- dubbo-remoting 远程通讯模块:相当于 Dubbo 协议的实现,如果 RPC 用 RMI 协议则不需要使用此包。
- dubbo-rpc 远程调用模块:抽象各种协议,以及动态代理,只包含一对一的调用,不关心集群的管理。
- dubbo-cluster 集群模块:将多个服务提供方伪装为一个提供方,包括:负载均衡, 容错,路由等,集群的地址列表可以是静态配置的,也可以是由注册中心下发。
- dubbo-registry 注册中心模块:基于注册中心下发地址的集群方式,以及对各种注册中心的抽象。
- dubbo-monitor 监控模块:统计服务调用次数,调用时间的,调用链跟踪的服务。
- dubbo-config 配置模块:是 Dubbo 对外的 API,用户通过 Config 使用Dubbo,隐藏 Dubbo 所有细节。
- dubbo-container 容器模块:是一个 Standlone 的容器,以简单的 Main 加载 Spring 启动,因为服务通常不需要 Tomcat/JBoss 等 Web 容器的特性,没必要用 Web 容器去加载服务。
整体上按照分层结构进行分包,与分层的不同点在于:
- container 为服务容器,用于部署运行服务,没有在层中画出。
- protocol 层和 proxy 层都放在 rpc 模块中,这两层是 rpc 的核心,在不需要集群也就是只有一个提供者时,可以只使用这两层完成 rpc 调用。
- transport 层和 exchange 层都放在 remoting 模块中,为 rpc 调用的通讯基础。
- serialize 层放在 common 模块中,以便更大程度复用。
2.5 依赖关系
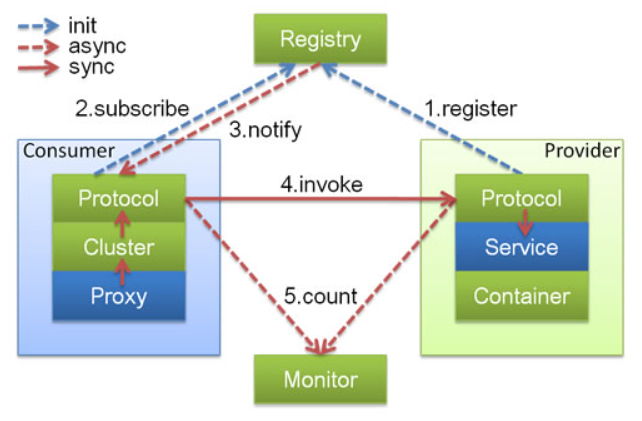
图例说明:
- 图中小方块 Protocol, Cluster, Proxy, Service, Container, Registry, Monitor 代表层或模块,蓝色的表示与业务有交互,绿色的表示只对 Dubbo 内部交互。
- 图中背景方块 Consumer, Provider, Registry, Monitor 代表部署逻辑拓扑节点。
- 图中蓝色虚线为初始化时调用,红色虚线为运行时异步调用,红色实线为运行时同步调用。
- 图中只包含 RPC 的层,不包含 Remoting 的层,Remoting 整体都隐含在 Protocol 中。
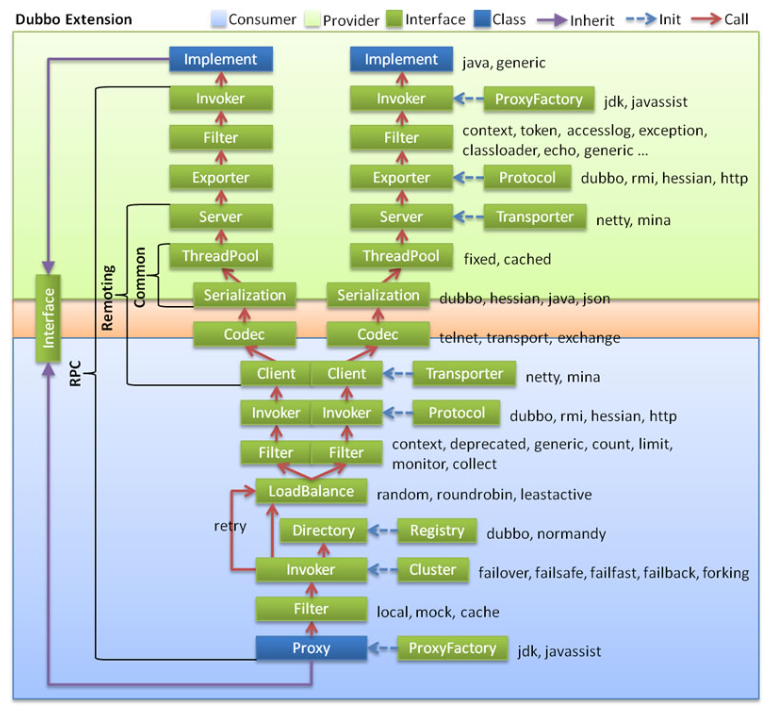
2.6 调用链
展开总设计图的红色调用链,如下:
2.7 暴露服务时序
展开总设计图左边服务提供方暴露服务的蓝色初始化链,时序图如下:
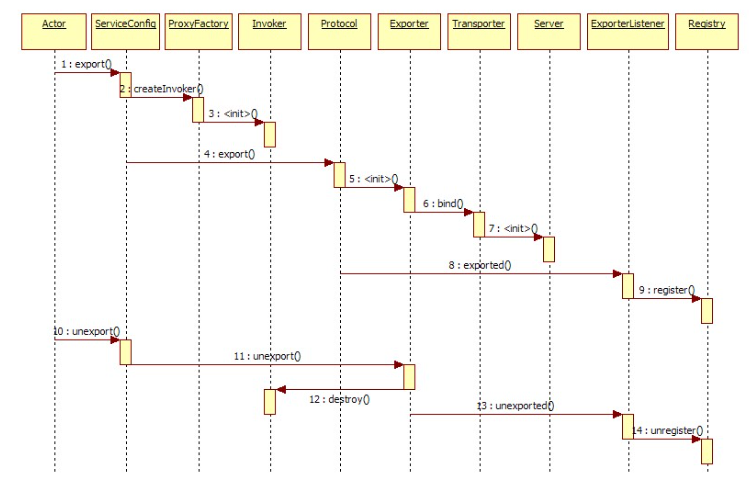
2.8 引用服务时序
展开总设计图右边服务消费方引用服务的蓝色初始化链,时序图如下:
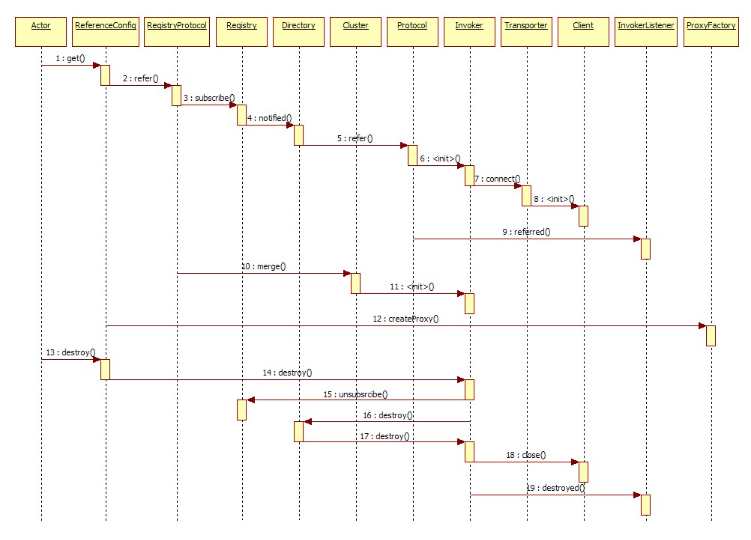
2.9 领域模型
在 Dubbo 的核心领域模型中:
- Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。
- Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
- Invocation 是会话域,它持有调用过程中的变量,比如方法名,参数等。
3、服务注册与消费源码剖析
3.1 注册中心Zookeeper剖析
注册中心是Dubbo的重要组成部分,主要用于服务的注册与发现,我们可以选择Redis、Nacos、Zookeeper作为Dubbo的注册中心,Dubbo推荐用户使用Zookeeper作为注册中心。
注册中心Zookeeper目录结构
我们使用一个最基本的服务的注册与消费的Demo来进行说明。
例如:只有一个提供者和消费者。com.lagou.service.HelloService 为我们所提供的服务。
public interface HelloService {
String sayHello(String name);
}
则Zookeeper的目录结构如下:
+- dubbo
| +- com.lagou.service.HelloService
| | +- consumers
| | | +- consumer://192.168.1.102/com.lagou.service.HelloService?application=dubbo-demo-annotationconsumer&category=consumers&check=false&dubbo=2.0.2&init=false&interface=com.lagou.service.HelloService&methods=sayHello,sayHelloWithPrint,sayHelloWithTransmission,sayHelloWithException&pid=25923&release=2.7.5&side=consumer&sticky=false×tamp=1583896043650
| | +- providers
| | | +- dubbo://192.168.1.102:20880/com.lagou.service.HelloService?anyhost=true&application=dubbo-demo-annotationprovider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.lagou.service.HelloService&methods=sayHello,sayHelloWithPrint,sayHelloWithTransmission,sayHelloWithException&pid=25917&release=2.7.5&side=provider&telnet=clear,exit,help,status,log,ls,ps,cd,pwd,invoke,trace,count,select,shutdown×tamp=1583896023597
| | +- configuration
| | +- routers
可以在这里看到所有的都是在dubbo层级下的 ,dubbo 根节点下面是当前所拥有的接口名称,如果有多个接口,则会以多个子节点的形式展开每个服务,下面又分别有四个配置项
- consumers: 当前服务下面所有的消费者列表(URL)
- providers: 当前服务下面所有的提供者列表(URL)
- configuration: 当前服务下面的配置信息信息,provider或者consumer会通过读取这里的配置信息来获取配置
- routers: 当消费者在进行获取提供者的时,会通过这里配置好的路由来进行适配匹配规则。可以看到,dubbo基本上很多时候都是通过URL的形式来进行交互获取数据的,在URL中也会保存很多的信息。后面也会对URL的规则做详细介绍。
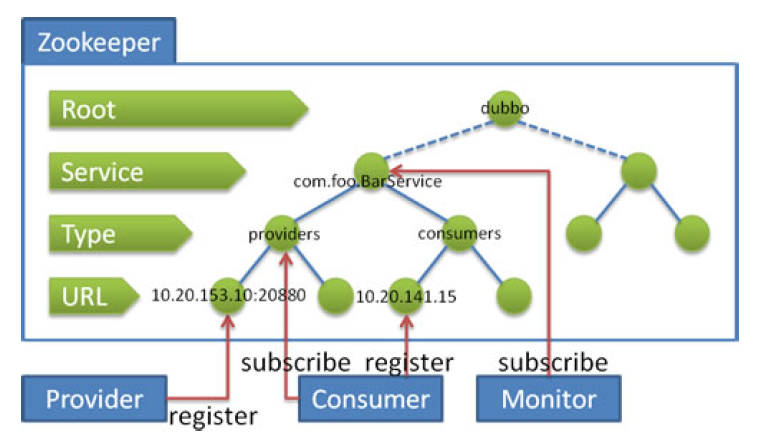
通过这张图我们可以了解到如下信息:
- 提供者会在providers 目录下进行自身的进行注册。
- 消费者会在consumers 目录下进行自身注册,并且监听provider 目录,以此通过监听提供者增加或者减少,实现服务发现。
- Monitor模块会对整个服务级别做监听,用来得知整体的服务情况。以此就能更多的对整体情况做监控。
3.2 服务的注册过程分析
服务注册(暴露)过程:
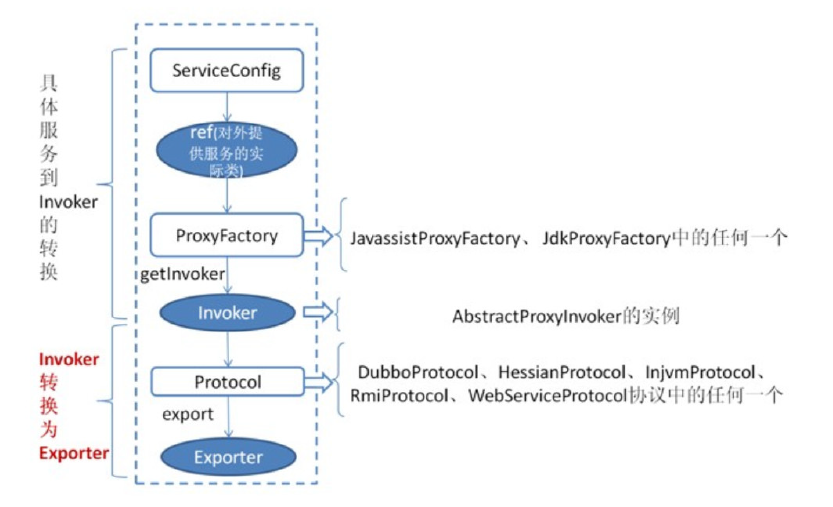
首先 ServiceConfig 类拿到对外提供服务的实际类 ref(如:HelloServiceImpl),然后通过 ProxyFactory 接口实现类中的 getInvoker 方法使用 ref 生成一个 AbstractProxyInvoker 实例,到这一步就完成具体服务到 Invoker 的转化。接下来就是 Invoker 转换到 Exporter 的过程。
Dubbo 处理服务暴露的关键就在 Invoker 转换到 Exporter 的过程,上图中的红色部分。下面我们以Dubbo 和 RMI 这两种典型协议的实现来进行说明:
Dubbo 的实现:
- Dubbo 协议的
Invoker转为Exporter发生在DubboProtocol类的export方法,它主要是打开 socket 侦听服务,并接收客户端发来的各种请求,通讯细节由 Dubbo 自己实现。
RMI 的实现:
- RMI 协议的
Invoker转为Exporter发生在RmiProtocol类的export方法,它通过 Spring 或 Dubbo 或 JDK 来实现 RMI 服务,通讯细节这一块由 JDK 底层来实现,这就省了不少工作量。
3.3 服务消费过程分析
服务消费流程:
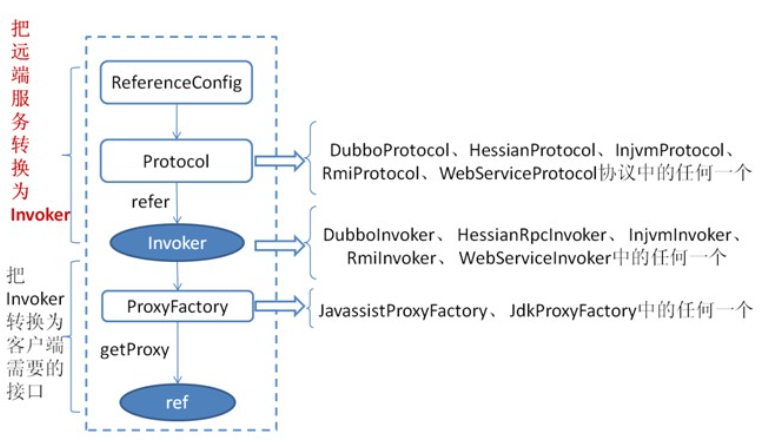
首先 ReferenceConfig 类的 init 方法调用 Protocol 的 refer 方法生成 Invoker 实例(如上图中的红色部分),这是服务消费的关键。接下来把 Invoker 转换为客户端需要的接口(如:HelloWorld)。
关于每种协议如 RMI/Dubbo/Web service 等它们在调用 refer 方法生成 Invoker 实例的细节和上一章节所描述的类似。
3.4 URL 规则详解和服务本地缓存
URL规则详解
URL地址如下:
protocol://host:port/path?key=value&key=value
// 示例
provider://192.168.20.1:20883/com.lagou.service.HelloService?anyhost=true&application=serviceprovider2&bind.ip=192.168.20.1&bind.port=20883&category=configurators&check=false&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.lagou.service
URL主要有以下几部分组成:
- protocol: 协议,一般像我们的 provider 或者 consumer 在这里都认为是具体的协议
- host: 当前 provider 或者其他协议所具体针对的地址,比较特殊的像 override 协议所指定的 host就是0.0.0.0 代表所有的机器都生效
- port: 和上面相同,代表所处理的端口号
- path: 服务路径,在provider 或者 consumer 等其他中代表着我们真实的业务接口
- key=value: 这些则代表具体的参数,这里我们可以理解为对这个地址的配置。比如我们 provider 中需要具体机器的服务应用名,就可以是一个配置的方式设置上去。
注意:Dubbo 中的 URL 与 java 中的 URL 是有一些区别的,如下:这里提供了针对于参数的 parameter 的增加和减少(支持动态更改),提供缓存功能,对一些基础的数据做缓存。
本地服务缓存
在上面我们有讲到 dubbo 有对路径进行本地缓存操作,这里我们就对本地缓存进行讲解。
dubbo 调用者需要通过注册中心(例如:ZK)注册信息,获取提供者,但是如果频繁往从 ZK 获取信息,肯定会存在单点故障问题,所以 dubbo 提供了将提供者信息缓存在本地的方法。
dubbo 在订阅注册中心的回调处理逻辑当中会保存服务提供者信息到本地缓存文件当中(同步/异步两种方式),以 URL 为度进行全量保存。
dubbo 在服务引用过程中会创建 registry 对象并加载本地缓存文件,会优先订阅注册中心,订阅注册中心失败后会访问本地缓存文件内容获取服务提供信息。
3.5 满眼都是 Invoker
由于 Invoker 是 Dubbo 领域模型中非常重要的一个概念,很多设计思路都是向它靠拢。这就使得 Invoker 渗透在整个实现代码里,对于刚开始接触 Dubbo 的人,确实容易给搞混了。 下面我们用一个精简的图来说明最重要的两种 Invoker:服务提供 Invoker 和服务消费 Invoker:
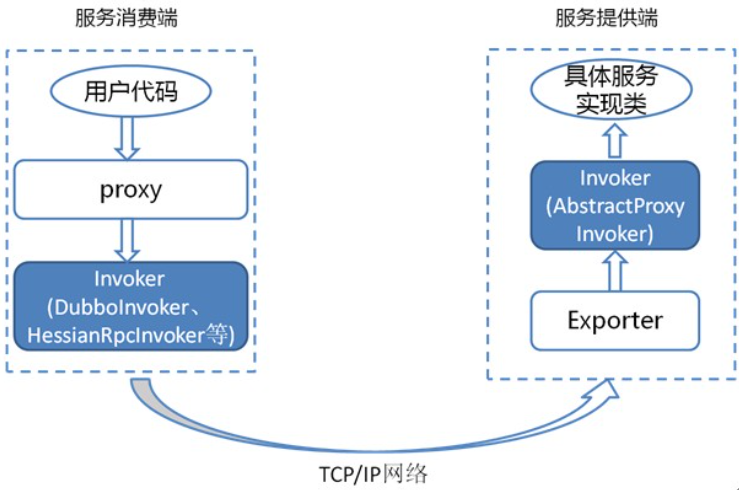
为了更好的解释上面这张图,我们结合服务消费和提供者的代码示例来进行说明:
服务消费者代码:
public class DemoClientAction {
private DemoService demoService;
public void setDemoService(DemoService demoService) {
this.demoService = demoService;
}
public void start() {
String hello = demoService.sayHello("world");
}
}
上面代码中的 DemoService 就是上图中服务消费端的 proxy,用户代码通过这个 proxy 调用其对应的 Invoker ,而该 Invoker 实现了真正的远程服务调用。
服务提供者代码:
public class DemoServiceImpl implements DemoService {
public String sayHello(String name) throws RemoteException {
return "Hello " + name;
}
}
上面这个类会被封装成为一个 AbstractProxyInvoker 实例,并新生成一个 Exporter 实例。这样当网络通讯层收到一个请求后,会找到对应的 Exporter 实例,并调用它所对应的 AbstractProxyInvoker 实例,从而真正调用了服务提供者的代码。Dubbo 里还有一些其他的 Invoker 类,但上面两种是最重要的。
4、Dubbo扩展SPI源码剖析
SPI 全称为 Service Provider Interface,是一种服务发现机制。SPI 的本质是将接口实现类的全限定名配置在文件中,并由服务加载器读取配置文件,加载实现类。这样可以在运行时,动态为接口替换实现类。正因此特性,我们可以很容易的通过 SPI 机制为我们的程序提供拓展功能。
SPI 机制在第三方框架中也有所应用,比如 Dubbo 就是通过 SPI 机制加载所有的组件。不过,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。如果大家想要学习 Dubbo 的源码,SPI 机制务必弄懂。(我们在dubbo快速入门中讲过)
5、服务目录源码剖析
5.1 概要
服务目录中存储了一些和服务提供者有关的信息,通过服务目录,服务消费者可获取到服务提供者的信息,比如 ip、端口、服务协议等。通过这些信息,服务消费者就可通过 Netty 等客户端进行远程调用。
在一个服务集群中,服务提供者数量并不是一成不变的,如果集群中新增了一台机器,相应地在服务目录中就要新增一条服务提供者记录。或者,如果服务提供者的配置修改了,服务目录中的记录也要做相应的更新。如果这样说,服务目录和注册中心的功能不就雷同了吗?确实如此,这里这么说是为了方便大家理解。实际上服务目录在获取注册中心的服务配置信息后,会为每条配置信息生成一个 Invoker 对象,并把这个 Invoker 对象存储起来,这个 Invoker 才是服务目录最终持有的对象。
Invoker 有什么用呢?看名字就知道了,这是一个具有远程调用功能的对象。讲到这大家应该知道了什么是服务目录了,它可以看做是 Invoker 集合,且这个集合中的元素会随注册中心的变化而进行动态调整。
关于服务目录这里就先介绍这些,大家先有个大致印象。接下来我们通过继承体系图来了解一下服务目录的家族成员都有哪些。
5.2 继承体系
服务目录目前内置的实现有两个,分别为 StaticDirectory 和 RegistryDirectory,它们均是 AbstractDirectory 的子类。AbstractDirectory 实现了 Directory 接口,这个接口包含了一个重要的方法定义,即 list(Invocation),用于列举 Invoker。下面我们来看一下他们的继承体系图。
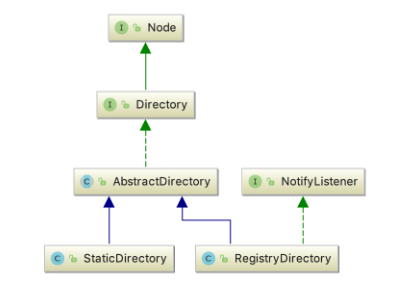
如上,Directory 继承自 Node 接口,Node 这个接口继承者比较多,像 Registry、Monitor、Invoker 等均继承了这个接口。这个接口包含了一个获取配置信息的方法 getUrl,实现该接口的类可以向外提供配置信息。另外,大家注意看 RegistryDirectory 实现了 NotifyListener 接口,当注册中心节点信息发生变化后,RegistryDirectory 可以通过此接口方法得到变更信息,并根据变更信息动态调整内部 Invoker 列表。
6、集群源码剖析
6.1 概要
为了避免单点故障,现在的应用通常至少会部署在两台服务器上。对于一些负载比较高的服务,会部署更多的服务器。这样,在同一环境下的服务提供者数量会大于1。
对于服务消费者来说,同一环境下出现了多个服务提供者。这时会出现一个问题,服务消费者需要决定选择哪个服务提供者进行调用。另外服务调用失败时的处理措施也是需要考虑的,是重试呢,还是抛出异常,亦或是只打印异常等。
为了处理这些问题,Dubbo 定义了集群接口 Cluster 以及 Cluster Invoker。集群 Cluster 用途是将多个服务提供者合并为一个 Cluster Invoker,并将这个 Invoker 暴露给服务消费者。这样一来,服务消费者只需通过这个 Invoker 进行远程调用即可,至于具体调用哪个服务提供者,以及调用失败后如何处理等问题,现在都交给集群模块去处理。
集群模块是服务提供者和服务消费者的中间层,为服务消费者屏蔽了服务提供者的情况,这样服务消费者就可以专心处理远程调用相关事宜。比如发请求,接受服务提供者返回的数据等。这就是集群的作用。
Dubbo 提供了多种集群实现,包含但不限于 Failover Cluster、Failfast Cluster 和 Failsafe Cluster 等。每种集群实现类的用途不同,接下来会一一进行分析。
6.2 集群容错
在对集群相关代码进行分析之前,这里有必要先来介绍一下集群容错的所有组件。包含 Cluster、Cluster Invoker、Directory、Router 和 LoadBalance 等。
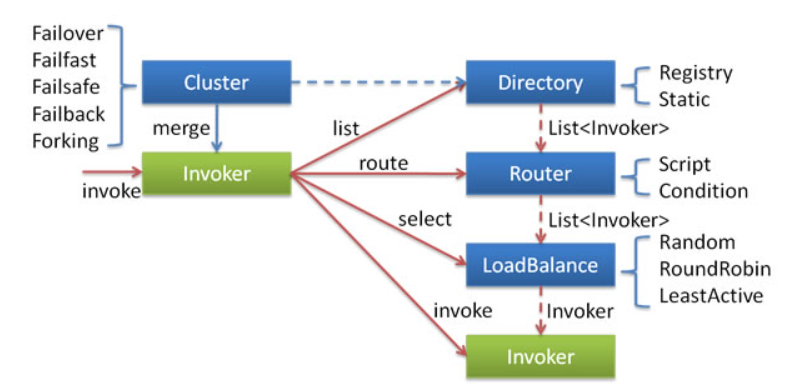
集群工作过程可分为两个阶段:
- 第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。
- 第二个阶段是在服务消费者进行远程调用时。以 FailoverClusterInvoker 为例,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。当 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表后,它会通过 LoadBalance 从 Invoker 列表中选择一个 Invoker。最后 FailoverClusterInvoker 会将参数传给 LoadBalance 选择出的 Invoker 实例的 invoke 方法,进行真正的远程调用。
Directory 的用途是保存 Invoker,可简单类比为 List
以上就是集群工作的整个流程,这里并没介绍集群是如何容错的。Dubbo 主要提供了这样几种容错方式:
- Failover Cluster - 失败自动切换
- Failfast Cluster - 快速失败
- Failsafe Cluster - 失败安全
- Failback Cluster - 失败自动恢复
- Forking Cluster - 并行调用多个服务提供者
7、服务路由源码分析
概要
服务目录在刷新 Invoker 列表的过程中,会通过 Router 进行服务路由,筛选出符合路由规则的服务提供者。
在详细分析服务路由的源码之前,先来介绍一下服务路由是什么。服务路由包含一条路由规则,路由规则决定了服务消费者的调用目标,即规定了服务消费者可调用哪些服务提供者。
Dubbo 目前提供了三种服务路由实现,分别为条件路由 ConditionRouter、脚本路由 ScriptRouter 和标签路由 TagRouter。其中条件路由是我们最常使用的,标签路由是一个新的实现,暂时还未发布,该实现预计会在 2.7.x 版本中发布。本篇文章将分析条件路由相关源码,脚本路由和标签路由这里就不分析了。
8、负载均衡源码分析
概要
LoadBalance 中文意思为负载均衡,它的职责是将网络请求,或者其他形式的负载“均摊”到不同的机器上。避免集群中部分服务器压力过大,而另一些服务器比较空闲的情况。
通过负载均衡,可以让每台服务器获取到适合自己处理能力的负载。在为高负载服务器分流的同时,还可以避免资源浪费,一举两得。
负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接触到硬件负载均衡。但软件负载均衡还是可以接触到的,比如 Nginx。
在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载过大。服务提供者负载过大,会导致部分请求超时。因此将负载均衡到每个服务提供者上,是非常必要的。
Dubbo 提供了4种负载均衡实现,分别是基于权重随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于 hash 一致性的 ConsistentHashLoadBalance,以及基于加权轮询算法的 RoundRobinLoadBalance。这几个负载均衡算法代码不是很长,但是想看懂也不是很容易,需要大家对这几个算法的原理有一定了解才行。如果不是很了解,也没不用太担心。我们会在分析每个算法的源码之前,对算法原理进行简单的讲解,帮助大家建立初步的印象。
9、网络通信原理剖析
主要讲解Dubbo在网络中如何进行通信的。由于请求都是基于TCP的,那么Dubbo中是如何处理粘包和拆包的问题,这里我们也会有讲解。
dubbo协议采用固定长度的消息头(16字节)和不定长度的消息体来进行数据传输,消息头定义了底层框架(netty)在IO线程处理时需要的信息。
9.1 数据包结构讲解
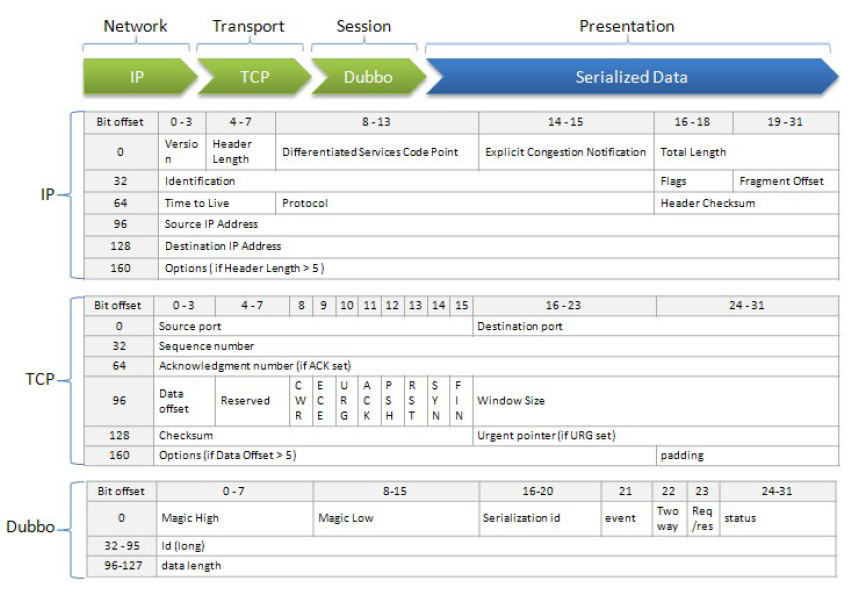
9.2 协议详情
-
Magic - Magic High & Magic Low (16 bits),标识协议版本号,Dubbo 协议:0xdabb
-
Serialization ID (5 bit),标识序列化类型:比如 fastjson 的值为6
-
Event (1 bit),标识是否是事件消息,例如,心跳事件。如果这是一个事件,则设置为1
-
2 Way (1 bit),仅在 Req/Res 为1(请求)时才有用,标记是否期望从服务器返回值。如果需要来自服务器的返回值,则设置为1
-
Req/Res (1 bit),标识是请求或响应。请求: 1; 响应: 0
-
Status (8 bits),仅在 Req/Res 为 0(响应)时有用,用于标识响应的状态
- 20 - OK
- 30 - CLIENT_TIMEOUT
- 31 - SERVER_TIMEOUT
- 40 - BAD_REQUEST
- 50 - BAD_RESPONSE
- 60 - SERVICE_NOT_FOUND
- 70 - SERVICE_ERROR
- 80 - SERVER_ERROR
- 90 - CLIENT_ERROR
- 100 - SERVER_THREADPOOL_EXHAUSTED_ERROR
-
Request ID (64 bits),标识唯一请求。类型为 long
-
Data Length (32 bits),序列化后的内容长度(可变部分),按字节计数,int类型
-
Variable Part,被特定的序列化类型(由序列化 ID 标识)序列化后,每个部分都是一个 byte [] 或者 byte
- 如果是请求包 ( Req/Res = 1),则每个部分依次为:
- Dubbo version
- Service name
- Service version
- Method name
- Method parameter types
- Method arguments
- Attachments
- 如果是响应包(Req/Res = 0),则每个部分依次为:
- 返回值类型(byte),标识从服务器端返回的值类型
- 返回空值:RESPONSE_NULL_VALUE 2
- 正常响应值: RESPONSE_VALUE 1
- 异常:RESPONSE_WITH_EXCEPTION 0
- 返回值:从服务端返回的响应bytes
- 如果是请求包 ( Req/Res = 1),则每个部分依次为:
注意:对于(Variable Part)变长部分,当前版本的 Dubbo 框架使用json序列化时,在每部分内容间额外增加了换行符作为分隔,请在Variable Part的每个part后额外增加换行符, 如:
Dubbo version bytes (换行符) Service name bytes (换行符) ...
优点:
- 协议设计上很紧凑,能用 1 个 bit 表示的,不会用一个 byte 来表示,比如 boolean 类型的标识
- 请求、响应的 header 一致,通过序列化器对 content 组装特定的内容,代码实现起来简单
可以改进的点:
- 类似于 http 请求,通过 header 就可以确定要访问的资源,而 Dubbo 需要涉及到用特定序列化协议才可以将服务名、方法、方法签名解析出来,并且这些资源定位符是 string 类型或者 string数组,很容易转成 bytes,因此可以组装到 header 中。类似于 http2 的 header 压缩,对于 rpc 调用的资源也可以协商出来一个 int 来标识,从而提升性能,如果在header 上组装资源定位符的话,该功能则更易实现。
- 通过 req/res 是否是请求后,可以精细定制协议,去掉一些不需要的标识和添加一些特定的标识。比如status , twoWay 标识可以严格定制,去掉冗余标识。还有超时时间是作为 Dubbo 的attachment 进行传输的,理论上应该放到请求协议的header中,因为超时是网络请求中必不可少的。提到 attachment ,通过实现可以看到 attachment 中有一些是跟协议 content 中已有的字段是重复的,比如 path 和version 等字段,这些会增大协议尺寸。
- Dubbo 会将服务名 com.alibaba.middleware.hsf.guide.api.param.ModifyOrderPriceParam ,转换为Lcom/alibaba/middleware/hsf/guide/api/param/ModifyOrderPriceParam; ,理论上是不必要的,最后追加一个; 即可。
- Dubbo 协议没有预留扩展字段,没法新增标识,扩展性不太好,比如新增响应上下文的功能,只有改协议版本号的方式,但是这样要求客户端和服务端的版本都进行升级,对于分布式场景很不友好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号