
一文详解 RPC 之负载均衡
为什么需要负载均衡
假设有一次流量高峰,突然发现线上服务的可用率降低了,经过排查发现是有几台机器比较旧了,当流量达到高峰时,这几台机器由于负载太高,就扛不住压力,那怎么解决这种问题呢?
首先我们可能会想到,在治理平台上调低这几台机器的权重,这样的话,流量自然就减少了。
但是这样会导致服务可用率降低,业务请求受到影响,那 RPC 框架有没有什么智能负载的机制?能及时地控制服务节点接收到的访问量?
什么是负载均衡
当一个服务节点无法支撑现有的访问量时,会部署多个节点,组成一个集群,然后通过负载均衡,将请求分发给这个集群下的每个服务节点,从而达到多个服务节点共同分担请求的压力的目的。
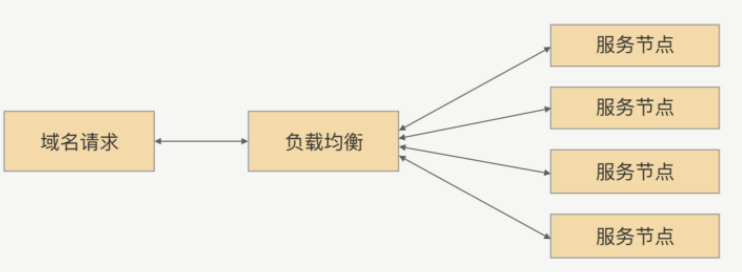
负载均衡只要分为软负载和硬负载,软负载就是在一台或多台服务器上安装负载均衡的软件,如LVS,Nginx等。硬负载就是通过硬件设备来实现的负载均衡,如 F5 服务器等。负载均衡的主要算法有随机法,轮询法,最小连接法等。
RPC 框架中的负载均衡
那 RPC 框架中的负载均衡和上面的负载均衡是一样的吗?为什么不添加负载均衡设备或者 TCP/IP 四层代理,域名绑定负载均衡设备的 IP 或者四层代理 IP 的方式。
因为可能会遇到下面的这样几个问题:
- 搭建负载均衡设备或 TCP/IP 四层代理,需要额外成本
- 请求流量都经过负载均衡设备,多经过一次网络传输,会额外浪费一些性能
- 负载均衡添加节点和摘除节点,一般都要手动添加,当大批量扩容或下线时,会有大量的人工操作,“服务发现”在操作上是个问题
- 在服务治理的时候,针对不同的接口服务、服务的不同分组,我们的负载均衡策略时需要可配的,如果大家都经过一个负载均衡设备,就不容易根据不用的场景来配置不同的负载均衡策略了。
RPC 的负载均衡完全由 RPC 框架自身实现,RPC 的服务调用者会与“注册中心“下发的所有服务节点建立长连接,在每次发起RPC调用时,服务调用者都会通过配置的负载均衡插件,自主选择一个服务节点,发起 RPC 请求调用。
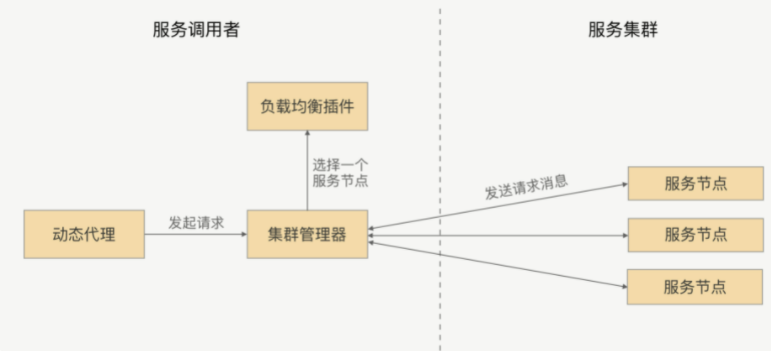
RPC 负载均衡策略一般包括随机权重,Hash、轮询。这主要还是看RPC框架自身的实现。还可以通过控制节点权重的方式,来进行流量控制。
如何设计自适应的负载均衡
RPC 的负载均衡完全由 RPC 框架自身实现,服务调用者发起请求的时候,会通过配置的负载均衡插件,自主的选择服务节点,那是不是只要调用者知道每个服务节点处理请求的能力,再根据服务处理节点处理请求的能力来判断要打给他多少流量就可以了?当一个服务节点负载过高或响应过慢时,就少给他发送请求,反之则多个它发送请求。
那服务节点又该如何判定一个服务节点的处理能力呢?
我们可以采用一种打分的策略,服务调用者收集与之建立长连接的每个服务节点的指标数据,如服务节点的负载指标,如服务节点指标、CPU核数、内存大小、请求处理的指标(如请求平均耗时、TP99、TP999)、服务节点的状态指标(如正常、亚健康)。通过这些指标根据计算策略计算出一个分数。我们可以为上面的指标都设置一个指标权重占比,然后再根据这些指标数据,计算分数。
服务调用者给每个服务节点都打完分之后,会发送请求,那这时候我们又该如何根据分数去控制给每个服务节点发送多少流量呢?
可与配置随机权重的负载均衡策略去控制,通过最终的指标分数修改服务节点最终的权重。服务调用者发送请求的时,会通过随机权重的策略来选择服务节点,那么这个节点收到的流量就是其他正常节点的权重比。
示意图如下:
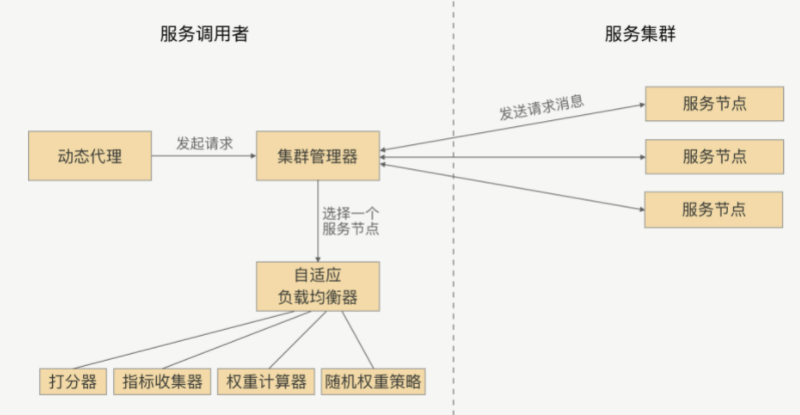
关键步骤:
- 添加服务指标收集器,并将其作为插件,默认有运行时状态指标收集器、请求耗时指标收集器。
- 运行时状态指标收集器收集服务节点 CPU 核数、CPU负载以及内存等指标,在服务调用者与服务提供者的心跳数据中获取。
- 请求耗时指示收集器收集请求时的数据,如平均耗时、TP99、 TP999等
- 可以配置开启哪些指示收集器,并设置这些参考指标的指标权重、再根据指标数据和指标权重来综合打分
- 通过服务节点的综合打分与节点的权重,最总计算出节点的最终权重,之后服务调用者会根据随机权重的策略,来选择服务节点。
巨人的肩膀:
https://time.geekbang.org/column/intro/100046201?tab=comment

