
RPC 中为啥需要健康检测
因为有了集群,每次发送请求前,RPC 框架会根据路由和负载均衡算法选择一个具体的 IP 地址。为了保证请求成功,就需要确保每次选择出来的 IP 对应的连接是健康的。
但是调用方各个服务集群节点之间的网络状态是瞬息万变的,两者之间可能会出现闪断或者网络设备损坏等情况,那么怎么保证连接一定是可用的呢?
终极的解决方案是让调用方实时感知到节点的状态变化,这样他们才能做出正确的选择。那么在 ROC 框架里面,怎么设计这台机制呢?
健康检测的逻辑
当服务方下线,正常情况下我们会收到连接断开的通知事件,在这个事件里面直接加处理逻辑不就可以了?但是不行,因为应用健康状态不仅包括 TCP 连接状态,还包括应用本身是否存活,很多情况下 TCP 连接没有断开,但是应用可能已经僵死了。
所以,业内常用的检测方式就是用心跳检测机制。心跳机制说起来也不复杂,其实就是服务调用方每隔一段时间就问一下服务提供方,“兄弟,你还好吧”,然后服务方很诚实地告诉调用方它目前的状态。
一般,服务方会有三种情况:
- 健康状态:建立连接成功,并且心跳探活也一直成功
- 亚健康状态:连接连接成功,但是心跳请求连接失败
- 死亡状态:建立连接失败
节点的状态并不是固定不变的,他会根据心跳或重连的结果来动态变化,具体状态间转换图如下:
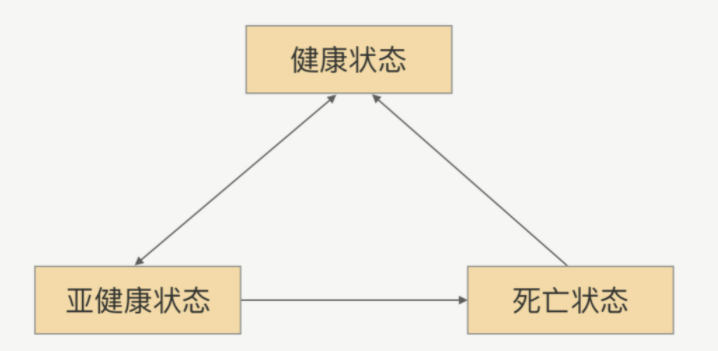
首先,一开始初始化的时候,如果连接建立成功,那就是健康状态,否则就是死亡状态。这里没有亚健康这样的中间态。如果健康状态的节点连续出现几次不能响应心跳请求的情况,那么就会被标记为亚健康状态,也就是说,服务调用方会觉得它“生病了”。
处于亚健康状态,如果连续几次都能正常响应心跳请求,那就可以转回健康状态,证明病好了。如果病一直好不了,那么就会被断定是死亡节点,死亡之后还需要善后,比如关闭连接。
当然,死亡并不是正真死亡,他还有复活机会。如果某个时间点里,死亡的节点能够重连成功,那它就可以重新被标记为健康状态。
当服务方通过心跳机制理解了节点的状态之后,每次发送请求的时候,就可以优先从健康列表里面选择一个节点,当然,如果健康列表为空,为了提高可用性,可以尝试从亚健康列表里面选择一个,这就是具体的策略了。
具体的解决方案
一个节点从健康状态过渡到亚健康状态的前提是“连续”心跳失败次数必须达到某一个阈值,比如3次,看你具体的配置。
而在我们的场景里,节点的心跳日志只是间歇性失败,也就是时好时坏,这样,失败次数根本没到阈值,调用方只是会觉得它“生病”了,并且很快就好了,那怎么解决呢?
你可能会想,那调低阈值呗,这样虽然可以解决,但是治标不治本,会导致调用方很快接触连续心跳失败而造成断开连接。
问题的核心是服务节点网络有问题,心跳间歇性失败,我们现在判断节点状态只有一个维度,那就是心跳检测,那是不是可以再加上业务请求的维度呢?
但是这样就没有问题了吗?
- 调用方每个接口的调用频次不一样,有的接口可能1秒内调用上百次,有的接口可能半个小时才会调用一次,所以我们不能把简单的总失败的次数当做判断条件。
- 服务的接口响应时间也是不一样的,有的接口可能1ms,有的接口可能是10s,所以我们也不能把 TPS 当做判断条件。
我们可以使用可用率,可用率的计算方式是某一个时间窗口内接口的调用成功次数的百分比(成功次数/总调用次数)。这样既考虑了高低频的调用接口,也兼顾了接口响应时间不同的问题。
巨人的肩膀:
https://time.geekbang.org/column/intro/100046201?tab=comment

 浙公网安备 33010602011771号
浙公网安备 33010602011771号