
numpy学习(一)
numpy数据类型
# numpy创建对象,numpy创建的对象是n阶矩阵,类似python中列表的嵌套
nd = np.array([[1,2,3,4,5],[2,3,4,6,5]])
nd
结果:
array([[1, 2, 3, 4, 5],
[2, 3, 4, 6, 5]])
ndarray的切片操作
格式:nd[start:end:step]
nd1 =[1,2,3,4,5,6,7,8,9,90]
#每隔三个取一个
nd1[::3]
#结果:[1, 4, 7, 90]
对三维数组进行切片
import matplotlib.pyplot as plt
data = Image.open("./timg.jpg")
plt.imshow(data)

data = np.array(data)
#第一维是行,第二维是列,第三维是像素
#颠倒第二维的顺序
data1 = data[::,::-1,:]
plt.imshow(data1)
如:

#查看数组的格式:shape
data1.shape
结果:(140, 121, 3)
对于数组中的值可以进行赋值
nd1 =[1,2,3,4,5,6,7,8,9,90]
nd1[3] = 10000
nd1
输出结果:
[1, 2, 3, 10000, 5, 6, 7, 8, 9, 90]
注意:numpy默认ndarray的所有元素的类型是相同的
如果传进来的列表中包含不同的类型,则统一为统一类型,优先级:str>float>int
使用np的routines常规函数创建
1.onces()和zeros()
np.ones(shape = (4,5)))
#创建数值为1的四行五列的数组
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
nd0 = np.zeros(shape =(4,5,6))
创建数值为0的四行五列,六个元素的三维数组
2.np.full(shape,fill_value,dtype = None,order = "C") #自定义数组
np.full(shape = (4,5),fill_value = 3.14)
array([[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14]])
3.np.eye(N,M = None,k = 0,dtype = float)
对角线为1,其他位置为0 的二维数组,若M为None,则默认M=N。
如:
e = np.eye(5)
e
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
4.将一维或是二维数组转换成为矩阵使用matrix()
注意:只能是一维或是二维数组进行转化
m = np.matrix(e)
m
matrix([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
#矩阵
type(m)
结果显示:
numpy.matrixlib.defmatrix.matrix
5.在指定的间隔没返回一个均匀间隔的数(生成等差数列)
np.arrange(start,spot,endpoint = Ture,retstep = False,dtype = None)
如:
np.linspace(0,99,num = 100) #在0~99之间生成100个数字的数组,相当于公差 为1的等差数列
array([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12.,
13., 14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25.,
26., 27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38.,
39., 40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50., 51.,
52., 53., 54., 55., 56., 57., 58., 59., 60., 61., 62., 63., 64.,
65., 66., 67., 68., 69., 70., 71., 72., 73., 74., 75., 76., 77.,
78., 79., 80., 81., 82., 83., 84., 85., 86., 87., 88., 89., 90.,
91., 92., 93., 94., 95., 96., 97., 98., 99.])
np.arange(start,stop,step,dtype) #在给定范围内生成等差数列、
如:np.arange(0,99,3)
array([ 0, 3, 6, 9, 12, 15, 18, 21, 24, 27, 30, 33, 36, 39, 42, 45, 48,
51, 54, 57, 60, 63, 66, 69, 72, 75, 78, 81, 84, 87, 90, 93, 96])
np.random.randint(low,high = None,size =None,dtype ="l" )
如:
np.random.randint(0,150,size = (4,5)) # 在0~150之间随机生成4行5列的二维数组
array([[ 49, 149, 26, 140, 18],
[ 18, 91, 97, 32, 34],
[108, 101, 55, 48, 94],
[ 34, 117, 113, 78, 67]])
生成一个标准的n维正态分布 即(生成的平均值为0,标准差为1的正态分布的数值)
np.random.randn(d0,d1,d2....dn)
如:
np.random.randn(10)
array([-0.11345673, -1.11331963, -0.96848249, -1.56695811, 0.81071585,
0.46713518, 0.72475584, -0.35389568, 1.22464807, -0.30686513])
ndarray的属性
4个必须记住的参数:ndim:维度,shape:形状(各维度的长度),size:总长度
dtype:元素类型
如:data.shape
#查看数据的数据类型:dtype
data.dtype
结果:
dtype('uint8')
int8和uint8的区别:
int8即指:2**8,范围是:-128~127
uint8指:256个数,范围是:~256
ndarray的基本操作
1.索引
一维列表完全一致,多维时同理
df = np.random.randint(0,100,size = [3,3,3])
df
输出结果:
array([[[91, 31, 3],
array([[[91, 31, 3],
[65, 65, 30],
[33, 56, 91]],
[[50, 5, 69],
[30, 67, 57],
[53, 13, 97]],
[[24, 9, 7],
[60, 59, 9],
[96, 58, 23]]])
切片:df[0,0,2]
索引到第三维,索引三次
输出结果:80
#拿到第三位数据
df[0,0]
#索引到第二维,索引两次
输出结果:
array([91, 31, 3])
#拿到第二维数据
分析:先看是几维数组,然后想要所以到第几维就索引到第几维就行了
2.变形
使用reshape函数,注意参数是一个tuple!
如:
nd = np.random.randint(0,100,size = 10)
nd
输出结果:
array([28, 79, 17, 2, 68, 3, 92, 2, 35, 16])
nd.reshape(5,2)
输出结果:
array([[39, 0],
[21, 26],
[33, 29],
[72, 23],
[34, 77]])
nd.reshape(2,5)
输出结果:
array([[39, 0, 21, 26, 33],
[29, 72, 23, 34, 77]])
注意:变形时是在数据够用的情况下进行变形
转置
在矩阵中,行变列,列变行
如:
data1 = Image.open("./wuxuanyi.jpg")
data

data2 = np.array(data1)
#将图片数据变成数组格式
wuxuanyi = data2.transpose([1,0,2])
#将行和列互换,使用函数transpose()
plt.imshow(wuxuanyi)

3.联级
np.concatenate()联级
需要注意的点
1.联级的参数是列表;一定需要加中括号,或是小括号
2.维度必须相同
3.形状相符
4.【重点】联级的方向默认位shape这个tuple的第一个值所代表的维度方向
5.可通过axis参数改变联级的方向
如:
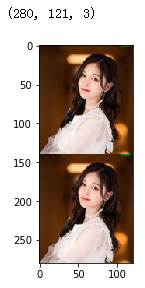
data3 = np.concatenate((data2,data2),axis = 1)
plt.imshow(data3)
输出结果:

np.hstack与np.vstack
水平级联和竖直级联,处理自己,进行维度的变更
data4 = np.vstack((data2,data2))
plt.imshow(data4)
data4.shape
4切片
切片与级联类似,三个函数完成切分工作
np.split:对数组进行切片(自定义切片方向)
np.vsplit:水平进行切片
np.hsplit:垂直进行切片
如:
a1,a2,a3 = np.split(a,indices_or_sections=(2,3),axis = 0)
display(a1,a2,a3)
indics_or_sections属性若给定的是一个整数N,则会沿着指定的轴将数据分隔成为等份的N个数组
若给定的是一个索引的元祖或是列表,切片函数会根据索引进行切片,
如:给定的如给定的缩影是(2,3),就是在index = 2,和index=3位置进行切割,在切时不包括当前索引的值
输出结果:
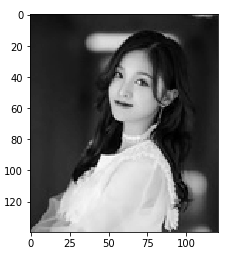
q1,q2,q3 = np.split(data2,indices_or_sections=3,axis = 2)
#将数据沿着第三个轴进行切片,切成等份的三组数据
#上边切割是按照图片的三原色进行切割的
q2.shape
#(140, 121, 1)
q2 = q2.reshape(140,-1)
#将一维的数据进行转换成为二维的数组,列和行是表示图片的宽和高
plt.imshow(q2,cmap = plt.cm.gray)
# 显示切割完后的图片,并给她附加灰色
a数组:
array([[1, 5, 7, 7, 2],
[2, 5, 7, 8, 0],
[3, 6, 8, 0, 4],
[1, 3, 5, 3, 4]])
np.vsplit(a,indices_or_sections=4)
显示结果:
[array([[1, 5, 7, 7, 2]]), array([[2, 5, 7, 8, 0]]), array([[3, 6, 8, 0, 4]]), array([[1, 3, 5, 3, 4]])]
#在竖直方向上将原数组平均切割成为4等份
#水平方向同理
5.副本
可使用copy对数组创建副本
b = a.copy
display(id(a),id(b))
显示结果:两个数组的内存地址不一样,相当于python中的深拷贝
