
pandas处理大文本数据
当数据文件是百万级数据时,设置chunksize来分批次处理数据
案例:美国总统竞选时的数据分析
读取数据
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df1 = pd.read_csv("./usa_election.csv",low_memory=False)
df1.shape
结果:(536041, 16) #可以看到数据量为536041
将数据在此进行级联成更大的文本数据
df =pd.concat([df1,df1,df1,df1])
df.shape
结果:(2144164, 16)
%%time
ret = df.to_csv("./hehe.csv",index = False)
ret
将df数据读取到文件中,并计算写入时间
ret = pd.read_csv("./hehe.csv",low_memory = False,chunksize=500000)
#将写入的大数据文件读出来,low_memory = False表示是否在内部一块的形式处理文件,chunksize表示分批次处理文件,每次处理多少数据
ret
读取的文件格式是:<pandas.io.parsers.TextFileReader at 0x122f30f0>
添加循环,读出来数据
for x in ret:
print(type(x))
结果:
<class 'pandas.core.frame.DataFrame'> <class 'pandas.core.frame.DataFrame'> <class 'pandas.core.frame.DataFrame'> <class 'pandas.core.frame.DataFrame'> <class 'pandas.core.frame.DataFrame'>
然后分批次处理数据
# 将str类型的时间转化成为时间类型的
处理前:

处理后:
处理过程:
months = {"JAN":"1", "FEB":"2","MAR":"3","APR":"4","MAY":"5","JUN":"6","JUL":"7","AUG":"8","SEP":"9","OCT":"10","NOV":"11","DEC":"12"}
def conver(x):
day,month,year = x.split("-") #进行切片操作
datatime = "20"+year+"-"+str(months[month])+"-"+day
return datatime #对切片重新组合
df1["contb_receipt_dt"] = df1["contb_receipt_dt"].map(conver)
df1["contb_receipt_dt"] = pd.to_datetime(df1["contb_receipt_dt"]) #转化成时间格式
df1["contb_receipt_dt"]
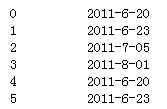
累加和的操作
# 累加和
a = np.arange(101) 随机一个数组数据
display(a)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,
13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25,
26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38,
39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51,
52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64,
65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77,
78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90,
91, 92, 93, 94, 95, 96, 97, 98, 99, 100])
b = a.cumsum() #求出该数据的累加和用函数cumsum()
ree=DataFrame(b,columns=["num"])
ree["num"].plot() #画出累加和的那列的图谱

