
pandas中数据聚合【重点】
数据聚合
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
1.数据分类处理的核心: groupby()函数
导入模块:
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
生成假数据
df = DataFrame({"sailer":np.random.randint(0,3,size=50),
"item":np.random.randint(0,3,size=50),
"price":np.random.randint(1,15,size = 50),
"weight":np.random.randint(50,150,size=50)})
df["sailer"] = df["sailer"].map({0:"李大妈",1:"王大爷",2:"宋大妈"})
df["item"] = df["item"].map({0:"白菜",1:"萝卜",2:"青椒"})
def convert(x):
return x-x%10
df["weight"] = df["weight"].map(convert)
df
如:

对数据进行分组,聚合操作
根据item进行分组,然后求出各个菜品的平均价格
g = df.groupby(by=["item"])["price"]
g.median()

表现形式如上边,数据格式为series
然后在根据sailer和item进行分类。
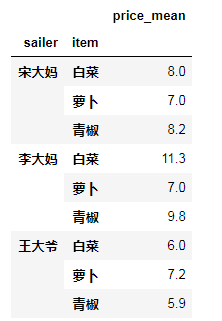
ret = df.groupby(by = ["sailer","item"])[["price"]].mean() #price值变成dataframe二维数如下图:
ret.add_suffix("_mean") #给列添加后缀 add_prefix()添加前缀
根据条件进行分组,然后自定义方法展示数据:如下
ret2 = df.groupby(by = ["sailer","item"])
def count(x):
return (np.round(x.mean(),1),x.min(),x.max()) #numpy中有round()方法是将小数四舍五入到给定的小数位数
ret2.agg(count)
aggregate()或agg()是指在指定轴上使用一个或多个操作进行聚合。

分组后对几个列添加不同的聚合映射关系
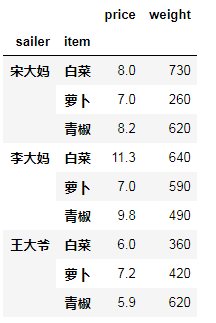
如下:对price求平均值,对重量求和
ret2 = df.groupby(by = ["sailer","item"])
ret2.agg({"price":"mean","weight":"sum"})
分组后使用透视表对数据进行聚合操作
pd.pivot_table(df,values=["sailer","weight"],index = ["sailer","item"],aggfunc ={"price":"mean","weight":"max"})
如下:对price、weight分别进行求平均值和最大值操作。

高级数据聚合
调用transform和apply实现上变相同的功能
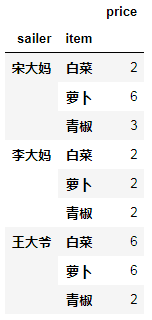
df.groupby(["sailer","item"])[["price"]].apply(np.min)
#因为min,mean,median等聚合函数在numpy定义了,所以,调用聚合函数得去numpy中调用
# transform原来的数据有多长,现在的数据就有多长
# 有利于对和原来的数据进行合并。
使用transform对数据进行分组聚合操作
df1 = df.groupby(["sailer","item"])[["price"]].transform(np.mean)
df1.tail()


