pandas实践——美国人口分析
1.导入文件,并查看数据样本
abbr = pd.read_csv("./state-abbrevs.csv")
areas =pd.read_csv("./state-areas.csv")
pop = pd.read_csv("./state-population.csv")
display(abbr.head(),areas.head(),pop.head())
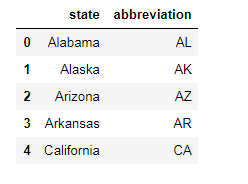
abbr:
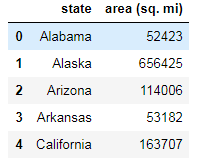
areas:
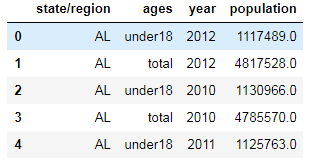
pop
2.合并数据,并对数据进行处理。
合并pop和abbr,两个dataframe,并删除合并后的abbreviation列
pop2 = pop.merge(abbr,how="outer",left_on="state/region",right_on="abbreviation") #设置how,合并后保留全部的数据
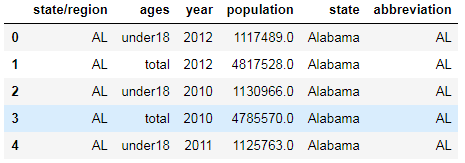
pop2.head() #展示前五条数据
pop2:
pop2.drop(labels="abbreviation",axis=1,inplace=True) #删除abbreviation的列
判断合并后有空数据
pop2.isnull().any(axis=0)
结果:

可以看到population列和state列中有空数据。
找到‘state’列中那些数据为空,并作为条件。
cond = pop2["state"].isnull()
根据条件判断出那个州有数据为空
cond = pop2["state"].isnull()
结果:array(['PR', 'USA'], dtype=object)
3.对空数据进行填充。
先添加填充条件
cond1 =pop2["state/region"]=="USA"
cond2 = pop2["state/region"]=="PR"
根据条件对为NaN的数数据进行补全
pop2["state"][cond2]="Puerto Rico"
pop2["state"][cond1]="United states"
正之前查询到的空数据的列还有population,对这些空数据进行删除。
cond3 = pop2["population"].isnull()
pop2[cond3].dropna(inplace=True)
pop2.notnull().all() #然后再对空数据进行查询
结果:
可以看到就没有空数据的列了
对areas表中数据添加到pop2中
pop3 = pop2.merge(areas,how="outer")
pop3.isnull().any() #判断融合后是否有空数据
结果:
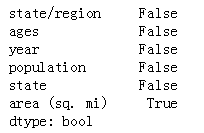 #可以看到area列含有空数据
#可以看到area列含有空数据
将有空数据的列作为条件
cond4 = pop3["area (sq. mi)"].isnull()
pop3[cond4]
结果:
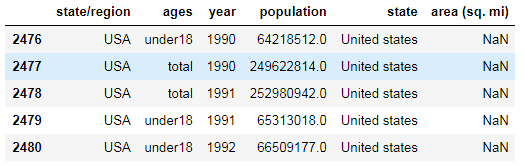 #可以看到美国国土总面积数据为空
#可以看到美国国土总面积数据为空
求出美国国土总面积。并将数据填充到pop3表中
a = areas["area (sq. mi)"].sum ()
pop3.fillna(a,inplace=True)
pop3.isnull().any()
结果:
 #可以看到pop3中都没有空数据了
#可以看到pop3中都没有空数据了
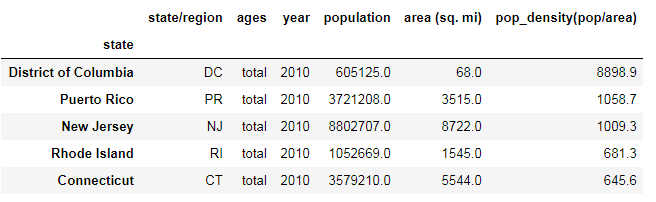
4.求出2010年美国各个州的人口密度
查询2010年各州的人口数据
pop4 = pop3.query("year==2010 and ages =='total'")
pop4.set_index(keys="state",inplace=True) #给查询出来的数据添加索引,并以州名作为索引。
pop4.tail()

pd.set_option("display.float_format",lambda x:"%0.1f"%(x))
pop_density = pop4["population"]/pop4["area (sq. mi)"]
pop_density1 = DataFrame(pop_density,columns=["pop_density(pop/area)"])
pop_density1.tail()
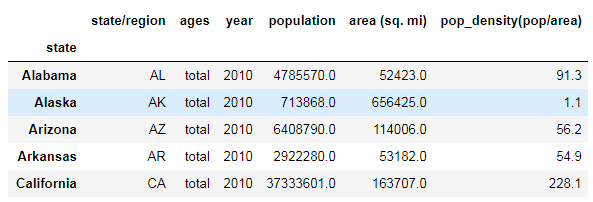
pop5 = pop4.merge(pop_density1,on="state")
pop5.head()
# 排序找到人口密度最高的五个州
pop6 = pop5.sort_values(by="pop_density(pop/area)",ascending=False)
pop6.head()