pandas的数据联级
一.索引的堆(stack)
1.行列的转化:
Stack():列转行
Unstack():行转列
Stack对应行,
使用小技巧:使用stack()的时候,level等于哪一个,哪一个就消失,出现在行里。
使用UNstack的时候,level等于哪一个,哪一个就消失,出现在列里。
如:
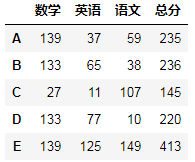
原来:A:
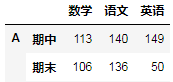
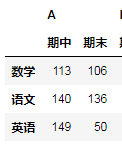
现在:A.stack(level=0).unstack(level=0).unstack(level=0)执行后
二.多层索引的聚合操作
所谓的操作是指:平均数mean()、方差std()、最大数max()、最小值min()等.....
注意:需要指定axis
小技巧:和unstack()相反,聚合操作的时候,axis等于哪一个,哪一个就保留
求平均值:
重点是axis和level的组合
A.mean(axis=0,level=1)
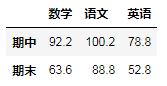
求方差:
df.std(asis=x,level=y)
方差是衡量随随机变量或一组数据时离散程度的度量。
A.std(axis=0,level=0)

Pandas的拼接操作
1.联级:pd.concal,pd.append
(1)使用pd.concat()级联
Pandas使用pd.concat()函数,与np.concatenate函数类似,只是多了一些参数
dp.concat(['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True'])
Concat()此方法默认增加行数,即样本。通过设置axis进行行方向或是列方向的级联。
如:
行方向级联:
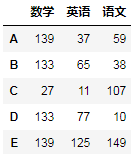
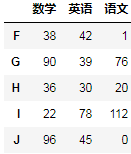
pd.concat([df1,df2],axis=0)
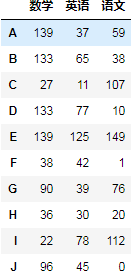
进行列方向级联
df3: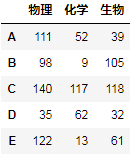
pd.concat([df1,df3],axis=1)
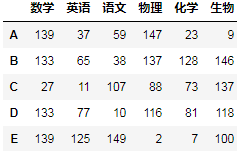
Pandas中的参数:
['objs', 'axis=0', "join='outer'", 'join_axes=None', 'ignore_index=False', 'keys=None', 'levels=None', 'names=None', 'verify_integrity=False', 'sort=None', 'copy=True']
Jgnore_index:
默认:False
如果为T,忽视给定的索引值,用1,2,3,4,.....代替,当然在操作时,以前给定的索引值失效。
如:pd.concat([df1,df2],ignore_index=True)
Keys:
序列,默认没有
如果传递了多个级别,则应该包含元组。构造使用传递的键作为最外层的分层索引
如:pd.concat([df1,df1],keys=["期中","期末"])
Join:
默认join=”outer”
Outer指合并除了公有列还合并非共有列
Inner指只合公有列
如:
pd.concat([df1,df5],join="outer")
pd.concat([df1,df5],join="inner")
Join_axes
当两张表中数据有部分列不同时,可以设置join_axes根据那个表中的列进行合并
如:pd.concat([df1,df5],join_axes=[df5.columns])
(2)使用append()追加
如:df1.append(df2)
- 合并:pd.merge,pd.join
(1)Merge:融合
A.参数:
['right', "how='inner'", 'on=None', 'left_on=None', 'right_on=None', 'left_index=False', 'right_index=False', 'sort=False', "suffixes=('_x', '_y')", 'copy=True', 'indicator=False', 'validate=None']
根据表中的属性值相同进行融合
Merge与concat的区别
merge需要依据某一共同的行或者列进行合并,使用pd.merge()合并时,会自动根据两者形同的column名称的那一列,作为key来进行合并。注意每一列元素的顺序不要求一致。
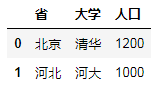
B.一对一合并
如:
df6 = DataFrame({"省":["北京","山东","河北"],"大学":["清华","山大","河大"],"人口":[1200,200,1000]})
df7 = DataFrame({"省":["北京","上海","河北"],"大学":["清华","复旦","河大"],"人口":[1200,1220,1000]})
df6.merge(df7)
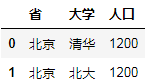
C.多对一合并
Df8 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
Df9 = DataFrame({"省":["北京","上海","河北"],"人口":[1200,1220,1000]})
Df8.merge(df9)
D.多对多合并
df6 = DataFrame({"省":["北京","山东","北京"],"大学":["清华","山大","北大"]})
df7 = DataFrame({"省":["北京","上海","北京"],"人口":[1200,1220,1000]})
df6.merge(df7)

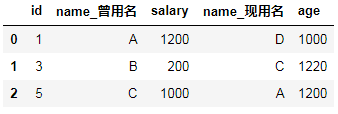
E.Key的规范化
使用on=显示指定那一列为key,当有多个key相同时使用
如:
df6 = DataFrame({"id":[1,3,5],"name":["A","B","C"],"salary":[1200,200,1000]})
df7 = DataFrame({"id":[5,3,1],"name":["A","C","D"],"age":[1200,1220,1000]})
df6.merge(df7,on="id",suffixes=["_曾用名","_现用名"]) #指定根据id进行合并
使用left_on和right_on指定左右两边的列作为key,当左右两边的key都不相等时使用
如:
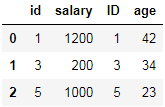
df6 = DataFrame({"id":[1,3,5],"salary":[1200,200,1000]})
df7 = DataFrame({"ID":[5,3,1],"age":[23,34,42]})
df6.merge(df7,left_on = "id",right_on = "ID")
内合并与外合并
内合并:只保留两者都有的key(默认模式)
How = “inner”
外合并:how = “outer”,补nan
左合并,右合并:how=”left”,how=”right”
G.列冲突的解决
当列冲突时,即有多个列名称相同时,需要使用on=来指定哪一个作为key,配合suffixes指定冲突列名,可以使用suffixes=自己指定的列名
Left_index=,right_index=,是否使用索引
如:将总分列添加到总表中
s = df1.sum(axis=1)
df0 = DataFrame(s,columns=["总分"])
df1.merge(df0,left_index=True,right_index=True)