【JAVA使用XPath、DOM4J解析XML文件,实现对XML文件的CRUD操作】
一、简介
1、使用XPath可以快速精确定位指定的节点,以实现对XML文件的CRUD操作。
2、去网上下载一个“XPath帮助文档”,以便于查看语法等详细信息,最好是那种有很多实例的那种。
3、学习XPath语法。
二、XPath语法
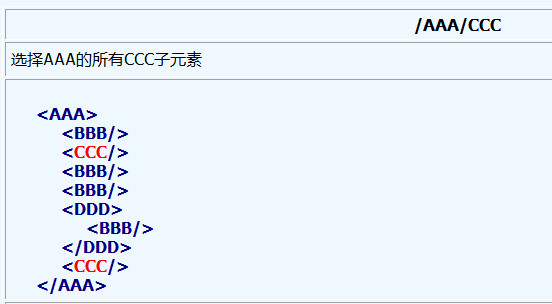
1、基本的XPath语法类似于在一个文件系统中定位文件,如果路径以斜线 / 开始, 那么该路径就表示到一个元素的绝对路径。
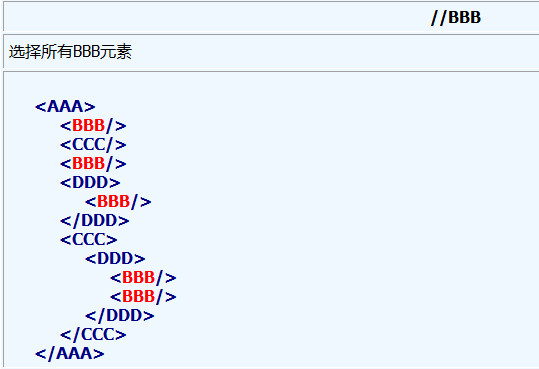
2、如果路径以双斜线 // 开头, 则表示选择文档中所有满足双斜线//之后规则的元素(无论层级关系)
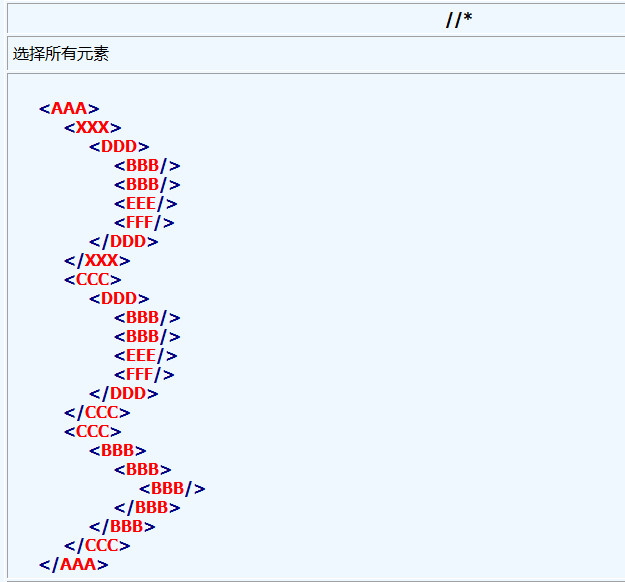
3、星号 * 表示选择所有由星号之前的路径所定位的元素
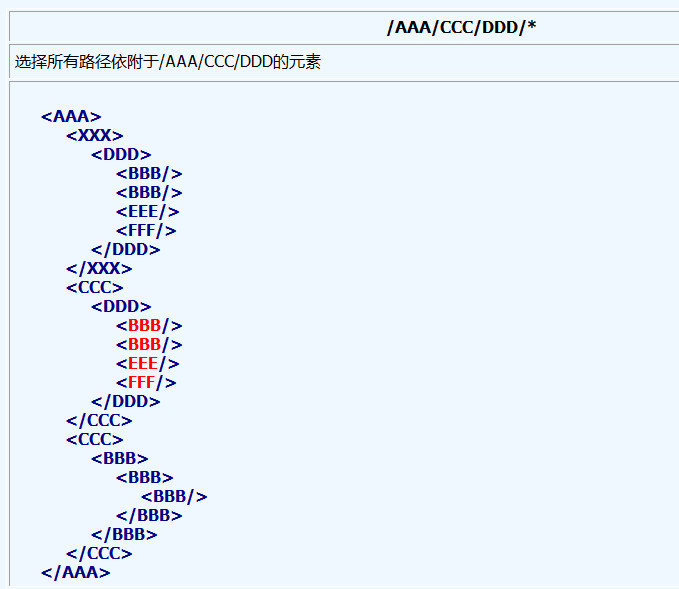

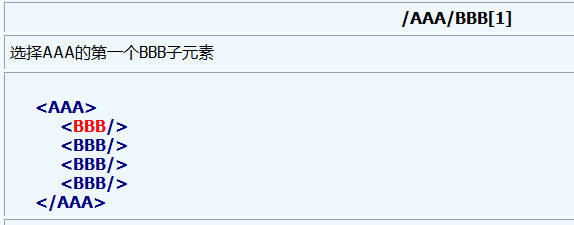
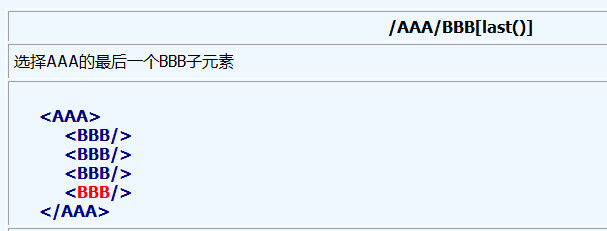
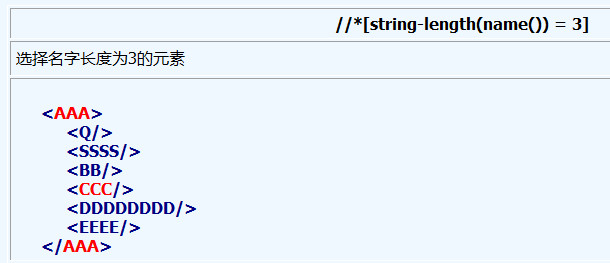
4、方块号里的表达式可以进一步的指定元素, 其中数字表示元素在选择集里的位置, 而last()函数则表示选择集中的最后一个元素.
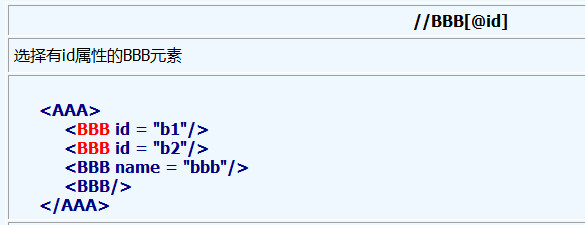
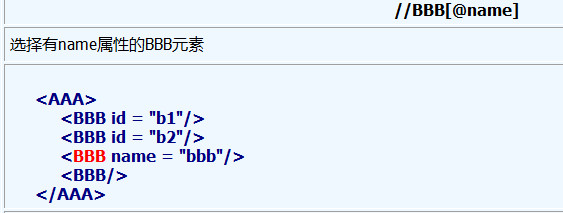
5、@符号用于选择属性

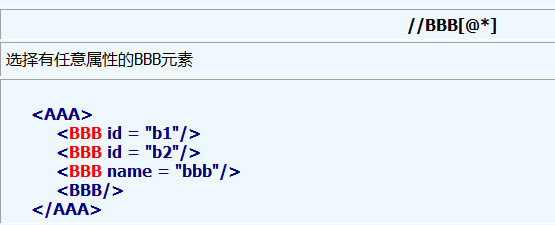
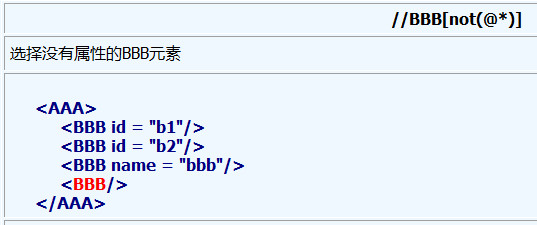
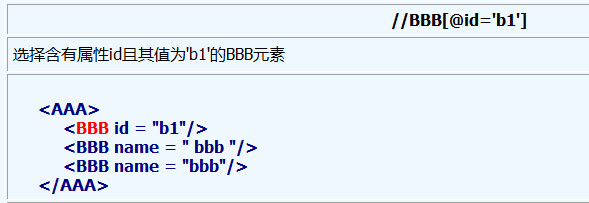
6、属性的值可以被用来作为选择的准则, normalize-space函数删除了前部和尾部的空格, 并且把连续的空格串替换为一个单一的空格

7.count()函数可以计数所选元素的个数

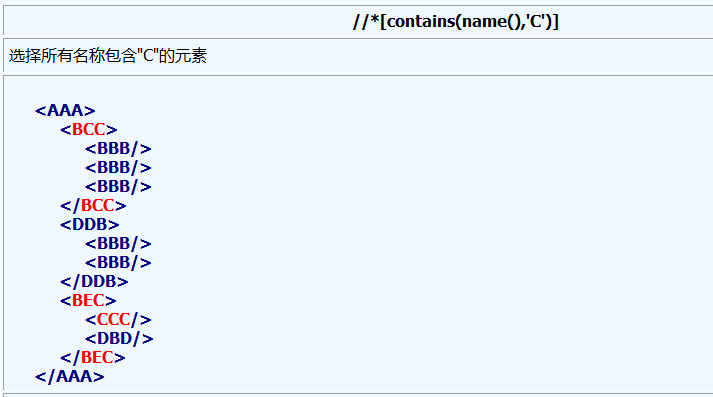
8.name()函数返回元素的名称, start-with()函数在该函数的第一个参数字符串是以第二个参数字符开始的情况返回true, contains()函数当其第一个字符串参数包含有第二个字符串参数时返回true.
方法:name()函数返回元素的名称, start-with()函数在该函数的第一个参数字符串是以第二个参数字符开始的情况返回true, contains()函数当其第一个字符串参数包含有第二个字符串参数时返回true.





1 package p00.domain; 2 3 public class Book { 4 public String title; 5 public double price; 6 public String id; 7 public String getId() 8 { 9 return id; 10 } 11 public void setId(String id) 12 { 13 this.id=id; 14 } 15 public String getTitle() 16 { 17 return title; 18 } 19 public double getPrice() 20 { 21 return price; 22 } 23 public void setTitle(String title) 24 { 25 this.title=title; 26 } 27 public void setPrice(double price) 28 { 29 this.price=price; 30 } 31 public String toString() 32 { 33 return "图书ISBN为:"+id+" 书名为:"+title+" 价格为:"+price; 34 } 35 36 }
写入新文档的公共方法:
1 /** 2 * 将得到的xml文档写入新的xml文档 3 * @param document 4 * @throws Exception 5 */ 6 private static void writeToXMLDocument(Document document) throws Exception { 7 FileOutputStream fos=new FileOutputStream(new File("xmldata/newbooks.xml")); 8 OutputStreamWriter osw=new OutputStreamWriter(fos,"utf-8"); 9 /** 10 *使用这种写法才不会产生乱码 11 */ 12 XMLWriter writer=new XMLWriter(osw); 13 writer.write(document); 14 writer.close(); 15 }
books.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book1"> <title>JAVA编程思想</title> <price>80.00</price> </book> <book id="book2"> <title>JAVA核心技术</title> <price>100.00</price> </book> </books>
2、查询
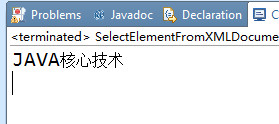
功能:查找id为book2的元素的title子元素并将其值显示出来
1 /** 2 * 显示指定的子元素值 3 * @param document 4 */ 5 private static void showDesignatedElementValue(Document document) { 6 String pattern="//book[@id='book2']/title"; 7 Node node=document.selectSingleNode(pattern); 8 String title=node.getText(); 9 System.out.println(title); 10 }
运行效果:
3、修改。
功能:修改id为book2的元素的子元素title使其为JAVA Core。
1 /** 2 * 完成修改功能。 3 * @param document 4 */ 5 private static void updateDesignatedElementValue(Document document) { 6 String pattern="//book[@id='book2']/title"; 7 Node node=document.selectSingleNode(pattern); 8 node.setText("JAVA Core"); 9 }
运行效果:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book1"> <title>JAVA编程思想</title> <price>80.00</price> </book> <book id="book2"> <title>JAVA Core</title> <price>100.00</price> </book> </books>
4、删除
功能:删除id为book2的元素
1 /** 2 * 完成删除功能 3 * @param document 4 */ 5 private static void deleteDesignatedElement(Document document) { 6 String pattern="//book[@id='book2']"; 7 Node book=document.selectSingleNode(pattern); 8 Element parrent=book.getParent(); 9 parrent.remove(book); 10 }
效果图:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book1"> <title>JAVA编程思想</title> <price>80.00</price> </book> </books>
四、总结
很明显,代码量又大大减少了,使用XPath解析XML文件比起单纯使用dom4j解析XML文件效率更高,实用性很强,应当重点注意,尽量使用该方法解析XML文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号