【JAVA与DOM4J实现对XML文档的CRUD操作】
一、简介
1.网上下载DOM4J 1.6.1压缩包,解压开之后,发现几个目录和一个jar文件,jar文件是必须的文件其它目录:
docs目录:帮助文档的目录,单击index.html:
Quick start是快速入门超链接,主要参考这里的代码完成对dom4j的认识,并完成CRUD的操作。
Javdoc(1.6.1)是dom4j的帮助文档,需要查找相关信息的时候主要参考这里。
lib目录:该目录下有相关若干jar包,他们是dom4j-1.6.1.jar的依赖文件,当使用XPath解析XML文档提示错误信息的时候,应当将该文件夹下面的相关jar文件加入路径。
src目录:该目录存放源文件,可以压缩该目录以便于查找源代码。
2.使用dom4j的好处。
最大的好处就是能够大大简化对XML文档的操作。
但应当注意,导包的时候应当导入的包是dom4j的包,而不是原来的包了,比如:Document对象应当导入的包名为:org.dom4j.Document。
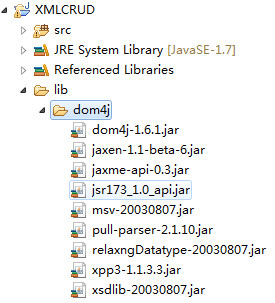
3.准备工作:对项目名称右键单击,新建目录lib,对着该目录右键单击,新建目录dom4j,将相关的jar文件复制到该目录中,选中所有的jar文件,右键build path->addtobuildpath,效果图:
另外Books类:


1 package p00.domain; 2 3 public class Book { 4 public String title; 5 public double price; 6 public String id; 7 public String getId() 8 { 9 return id; 10 } 11 public void setId(String id) 12 { 13 this.id=id; 14 } 15 public String getTitle() 16 { 17 return title; 18 } 19 public double getPrice() 20 { 21 return price; 22 } 23 public void setTitle(String title) 24 { 25 this.title=title; 26 } 27 public void setPrice(double price) 28 { 29 this.price=price; 30 } 31 public String toString() 32 { 33 return "图书ISBN为:"+id+" 书名为:"+title+" 价格为:"+price; 34 } 35 36 }
books.xml文档:
1 <?xml version="1.0" encoding="UTF-8"?> 2 <books> 3 <book id="book1"> 4 <title>JAVA编程思想</title> 5 <price>80.00</price> 6 </book> 7 <book id="book2"> 8 <title>JAVA核心技术</title> 9 <price>100.00</price> 10 </book> 11 </books>
持久化保存到xml文档的方法。
使用第一种方法:
1 private static void writeToNewXMLDocument(Document document) throws Exception { 2 FileWriter fw=new FileWriter("xmldata/newbooks.xml"); 3 OutputFormat of=OutputFormat.createPrettyPrint(); 4 of.setEncoding("gbk");//如果改为utf-8则出现乱码。 5 XMLWriter writer=new XMLWriter(fw,of); 6 writer.write(document); 7 writer.close();//注意不要忘记关流。 8 }
使用该方法出现了中文乱码问题,原因是文件编码为gbk,二文件内容编码为utf-8,产生原因不明。因此改用另外一种方法,该方法使用OutputStreamWriter类实现特定编码方式的写入,解决了中文乱码问题。
1 /** 2 * 通过document对象将内存中的dom树保存到新的xml文档,使用特定的编码方式:utf-8。 3 * @param document 4 * @throws Exception 5 */ 6 private static void writeToNewXMLDocument(Document document) throws Exception { 7 FileOutputStream fos=new FileOutputStream(new File("xmldata/newbooks.xml")); 8 OutputStreamWriter osw=new OutputStreamWriter(fos,"utf-8"); 9 /** 10 *使用这种写法才不会产生乱码 11 */ 12 XMLWriter writer=new XMLWriter(osw); 13 writer.write(document); 14 writer.close(); 15 }
二、CRUD操作。
1、读取(R)
1 private static List<Book> readAllElementsFromXMLDocument(Document document) { 2 List<Book>books=new ArrayList<Book>(); 3 Element root=document.getRootElement(); 4 List list=root.elements(); 5 for(int i=0;i<list.size();i++) 6 { 7 Element book=(Element) list.get(i); 8 Book b=new Book(); 9 String id=book.attributeValue("id"); 10 List ll=book.elements(); 11 b.setId(id); 12 System.out.println(id); 13 for(int j=0;j<ll.size();j++) 14 { 15 Element element=(Element) ll.get(j); 16 if("title".equals(element.getName())) 17 { 18 String title=element.getText(); 19 b.setTitle(title); 20 System.out.println(title); 21 } 22 if("price".equals(element.getName())) 23 { 24 String price=element.getText(); 25 double p=Double.parseDouble(price); 26 b.setPrice(p); 27 System.out.println(price); 28 } 29 } 30 books.add(b); 31 } 32 return books; 33 }
效果图:

2、修改(U)
1 /** 2 * 该方法的作用是修改document中的内容 3 * 将id为b002的元素的title改为Java Core,Price改为100.01 4 * @param document 5 */ 6 private static void ModifyInformationOfXMLDocument(Document document) { 7 Element root=document.getRootElement(); 8 List books=root.elements(); 9 for(int i=0;i<books.size();i++) 10 { 11 12 Element book=(Element) books.get(i); 13 if("book2".equals(book.attributeValue("id"))) 14 { 15 for(Iterator it=book.elementIterator();it.hasNext();) 16 { 17 Element node=(Element) it.next(); 18 String type=node.getName(); 19 if("title".equals(type)) 20 { 21 node.setText("JAVA Core"); 22 } 23 if("price".equals(type)) 24 { 25 node.setText("100.01"); 26 } 27 } 28 } 29 } 30 }
效果图:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book1"> <title>JAVA编程思想</title> <price>80.00</price> </book> <book id="book2"> <title>JAVA Core</title> <price>100.01</price> </book> </books>
3、删除(D)
1 /** 2 * 该方法实现了使用dom4j的删除元素的功能 3 * @param document 4 */ 5 private static void deleteInformationOfXMLDocument(Document document) { 6 Element root=document.getRootElement(); 7 for(Iterator it=root.elementIterator();it.hasNext();) 8 { 9 Element book=(Element) it.next(); 10 String id=book.attributeValue("id"); 11 if("book1".equals(id)) 12 { 13 Element parent=book.getParent(); 14 parent.remove(book); 15 } 16 } 17 }
效果图:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book2"> <title>JAVA核心技术</title> <price>100.00</price> </book> </books>
4、添加(C)
1 /** 2 * 实现了添加新节点:book的功能 3 * @param document 4 */ 5 private static void addNewBookToXMLDocument(Document document) { 6 Element root=document.getRootElement(); 7 Element newBook=root.addElement("book"); 8 newBook.addAttribute("id", "book3"); 9 Element title=newBook.addElement("title"); 10 title.setText("凤姐玉照"); 11 Element price=newBook.addElement("price"); 12 price.setText("10000.01"); 13 }
效果图:
<?xml version="1.0" encoding="UTF-8"?> <books> <book id="book1"> <title>JAVA编程思想</title> <price>80.00</price> </book> <book id="book2"> <title>JAVA核心技术</title> <price>100.00</price> </book> <book id="book3"><title>凤姐玉照</title><price>10000.01</price></book></books>
5.完整代码
1 package p03.CRUDToXMLDocumentByDom4j; 2 3 4 import java.io.File; 5 import java.io.FileOutputStream; 6 import java.io.FileWriter; 7 import java.io.OutputStreamWriter; 8 import java.util.ArrayList; 9 import java.util.Iterator; 10 import java.util.List; 11 12 import org.dom4j.Document; 13 import org.dom4j.Element; 14 import org.dom4j.io.OutputFormat; 15 import org.dom4j.io.SAXReader; 16 import org.dom4j.io.XMLWriter; 17 18 import p00.domain.Book; 19 20 /** 21 * 该类通过dom4j技术实现了对xml文档的增删改查。 22 * @author kdyzm 23 * 24 */ 25 public class SetAllElementsByDom4j { 26 public static void main(String args[]) throws Exception 27 { 28 /** 29 * 第一步,得到document对象。 30 */ 31 Document document=getDocument(); 32 33 /** 34 * 第二步,修改得到的document对象 35 */ 36 37 /** 38 * 首先,读取功能 39 */ 40 // List<Book>books=readAllElementsFromXMLDocument(document); 41 // traverseBooks(books); 42 43 /** 44 * 其次,修改功能 45 * 修改内容:将id为b002的元素的title改为Java Core,Price改为100.01 46 */ 47 // ModifyInformationOfXMLDocument(document); 48 49 /** 50 * 再者:实现删除功能 51 * 删除内容:删除掉id为book1的元素内容。 52 */ 53 // deleteInformationOfXMLDocument(document); 54 55 /** 56 * 最后:实现添加i新元素功能 57 * 添加内容:id为book3,title内容为:凤姐玉照,price内容为10000.00 58 */ 59 // addNewBookToXMLDocument(document); 60 61 /** 62 * 第三步:将得到的document对象持久化保存到硬盘(XML) 63 */ 64 writeToNewXMLDocument(document); 65 } 66 /** 67 * 实现了添加新节点:book的功能 68 * @param document 69 */ 70 private static void addNewBookToXMLDocument(Document document) { 71 Element root=document.getRootElement(); 72 Element newBook=root.addElement("book"); 73 newBook.addAttribute("id", "book3"); 74 Element title=newBook.addElement("title"); 75 title.setText("凤姐玉照"); 76 Element price=newBook.addElement("price"); 77 price.setText("10000.01"); 78 } 79 80 /** 81 * 该方法实现了使用dom4j的删除元素的功能 82 * @param document 83 */ 84 private static void deleteInformationOfXMLDocument(Document document) { 85 Element root=document.getRootElement(); 86 for(Iterator it=root.elementIterator();it.hasNext();) 87 { 88 Element book=(Element) it.next(); 89 String id=book.attributeValue("id"); 90 if("book1".equals(id)) 91 { 92 Element parent=book.getParent(); 93 parent.remove(book); 94 } 95 } 96 } 97 98 /** 99 * 该方法的作用是修改document中的内容 100 * 将id为b002的元素的title改为Java Core,Price改为100.01 101 * @param document 102 */ 103 private static void ModifyInformationOfXMLDocument(Document document) { 104 Element root=document.getRootElement(); 105 List books=root.elements(); 106 for(int i=0;i<books.size();i++) 107 { 108 109 Element book=(Element) books.get(i); 110 if("book2".equals(book.attributeValue("id"))) 111 { 112 for(Iterator it=book.elementIterator();it.hasNext();) 113 { 114 Element node=(Element) it.next(); 115 String type=node.getName(); 116 if("title".equals(type)) 117 { 118 node.setText("JAVA Core"); 119 } 120 if("price".equals(type)) 121 { 122 node.setText("100.01"); 123 } 124 } 125 } 126 } 127 } 128 /** 129 * 遍历集合 130 * @param books 131 */ 132 private static void traverseBooks(List<Book> books) { 133 for(Iterator<Book>iterator=books.iterator();iterator.hasNext();) 134 { 135 Book book=iterator.next(); 136 System.out.println(book); 137 } 138 } 139 /** 140 * 该方法实现了对xml文档的读取功能 141 * @param document 142 * @return 143 */ 144 private static List<Book> readAllElementsFromXMLDocument(Document document) { 145 List<Book>books=new ArrayList<Book>(); 146 Element root=document.getRootElement(); 147 List list=root.elements(); 148 for(int i=0;i<list.size();i++) 149 { 150 Element book=(Element) list.get(i); 151 Book b=new Book(); 152 String id=book.attributeValue("id"); 153 List ll=book.elements(); 154 b.setId(id); 155 System.out.println(id); 156 for(int j=0;j<ll.size();j++) 157 { 158 Element element=(Element) ll.get(j); 159 if("title".equals(element.getName())) 160 { 161 String title=element.getText(); 162 b.setTitle(title); 163 System.out.println(title); 164 } 165 if("price".equals(element.getName())) 166 { 167 String price=element.getText(); 168 double p=Double.parseDouble(price); 169 b.setPrice(p); 170 System.out.println(price); 171 } 172 } 173 books.add(b); 174 } 175 return books; 176 } 177 /** 178 * 通过document对象将内存中的dom树保存到新的xml文档,使用特定的编码方式:utf-8。 179 * @param document 180 * @throws Exception 181 */ 182 private static void writeToNewXMLDocument(Document document) throws Exception { 183 FileOutputStream fos=new FileOutputStream(new File("xmldata/newbooks.xml")); 184 OutputStreamWriter osw=new OutputStreamWriter(fos,"utf-8"); 185 /** 186 *使用这种写法才不会产生乱码 187 */ 188 XMLWriter writer=new XMLWriter(osw); 189 writer.write(document); 190 writer.close(); 191 } 192 193 /** 194 * 该方法用于得到document对象。 195 * @return 196 * @throws Exception 197 */ 198 private static Document getDocument() throws Exception { 199 SAXReader sr=new SAXReader(); 200 Document document=sr.read("xmldata/books.xml"); 201 return document; 202 } 203 }
三、总结
使用dom4j大大减少了代码量,提供了编码效率,推荐使用该方法对XML文档进行解析。

