CAS原子类:AtomicLongArray源码解析
AtomicLongArray内部维护了一个int类型的数组,需要先复习下数组对象的在内存中的结构,这对接下来对数组类型原子类的理解至关重要。
一、数组对象的内存结构
我们运行以下代码并将数组对象的内存结构通过JOL工具打印出来,关于这部分知识,参考之前的文章:深入理解Java对象结构
public class ArrayTest {
public static void main(String[] args) {
//打印虚拟机信息
System.out.println(VM.current().details());
//十个元素的int数组
int[] array = new int[]{0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
//打印内存结构
System.out.println(ClassLayout.parseInstance(array).toPrintable());
}
}
输出结果:
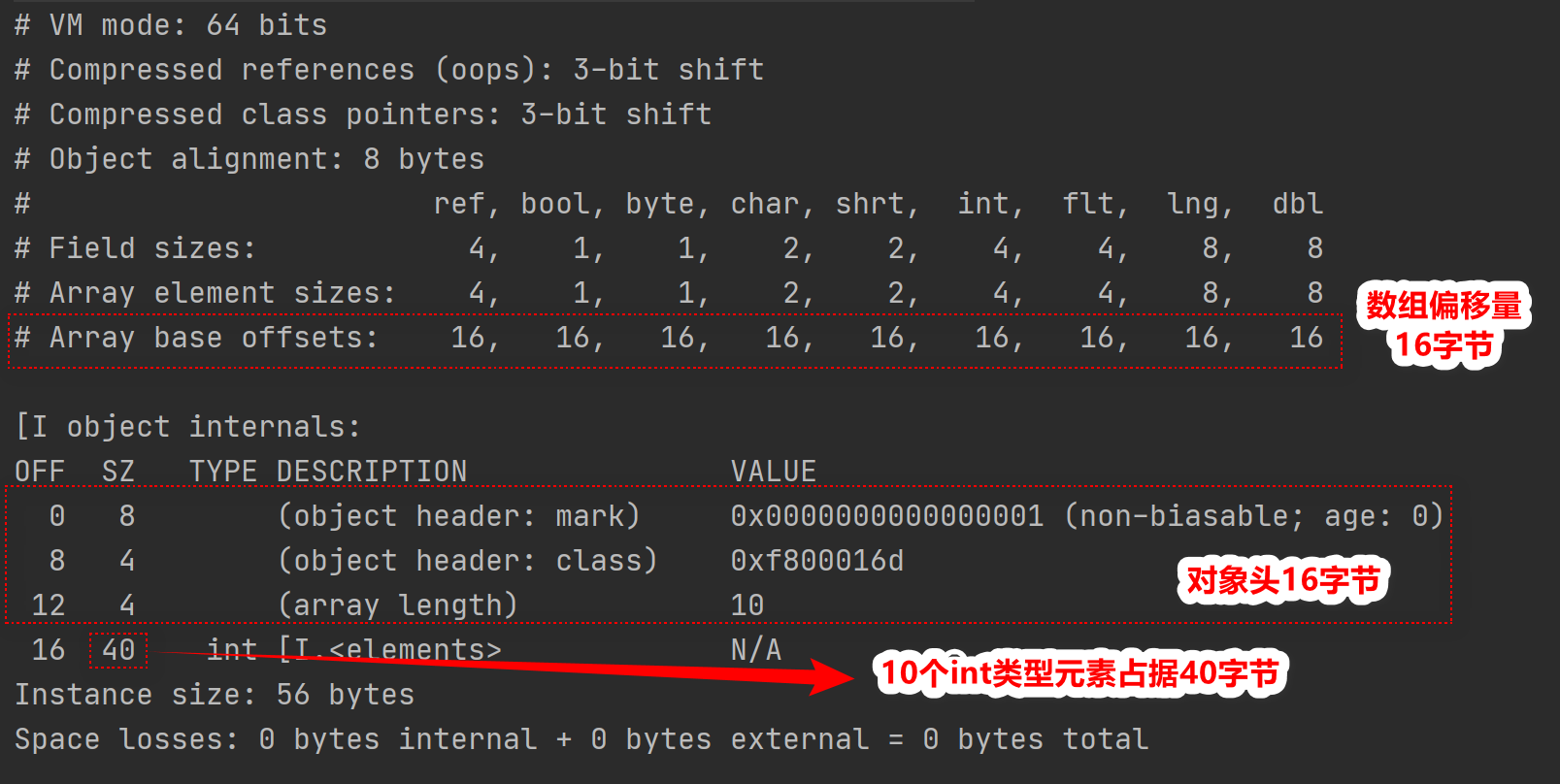
整个对象大小是16字节的对象头+40字节的对象体,一共56字节,由于正好是对齐字节数8的倍数,所以没有对齐字节。
问题来了,如果站在Unsafe类的角度上,如何实现快速访问数组中的某个元素?
Unsafe可以基于偏移量的快速访问,也就是说只要告诉Unsafe前边有多少个字节数,它就可以直接定位到需要访问的元素。如果我想访问第1个元素,那前边就只有对象头,那就是16字节;如果我想访问第二个元素,那就是16字节的对象头+4字节的第一个元素,就是20字节;如果我想访问呢第三个元素,那就是16字节的对象头+8字节的两个元素,就是24个字节。。。如果我想访问下标为i的元素,那就是(16+ix4)个字节。
我们知道位移运算要比乘法运算效率高的多,为了效率最大化,可以使用位移运算替代乘法运算,4正好是22满足位移计算替换的要求(热知识:将一个数i向左位移N位,实际上等效于ix2N,所以必须保证第二个乘数是2的幂次方),所以16+ix4可以替换为16+i<<2,没错,在数组类型原子类中,正是使用这种位移的方式快速定位元素的。
二、get方法源码解析
由于源代码比较长,分开一点一点来看,先看get方法:public final int get(int i),说起来你肯定不信,这个方法是这个类最复杂的方法了
public class AtomicIntegerArray {
//Unsafe类初始化
private static final Unsafe unsafe = Unsafe.getUnsafe();
//数组元素的内存偏移量
private static final int base = unsafe.arrayBaseOffset(int[].class);
//位移次数
private static final int shift;
//通过final保证可见性
private final int[] array;
static {
//确定数组中每个元素的大小,单位字节
int scale = unsafe.arrayIndexScale(int[].class);
//确定scale大小是2的幂次方
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
//确定位移次数,用于后续计算元素的内存偏移量
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
private long checkedByteOffset(int i) {
if (i < 0 || i >= array.length)
throw new IndexOutOfBoundsException("index " + i);
return byteOffset(i);
}
//根据数组坐标查询内存偏移量
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}
//获取某个元素的值
public final int get(int i) {
return getRaw(checkedByteOffset(i));
}
//调用unsafe方法根据偏移量获取某个方法的值
private int getRaw(long offset) {
return unsafe.getIntVolatile(array, offset);
}
}
上面的整个源代码都是public final int get(int i)方法相关的函数和变量。接下来逐步看下每段代码的意思。
静态代码块
static {
//确定数组中每个元素的大小,单位字节
int scale = unsafe.arrayIndexScale(int[].class);
//确定scale大小是2的幂次方
if ((scale & (scale - 1)) != 0)
throw new Error("data type scale not a power of two");
//确定位移次数,用于后续计算元素的内存偏移量
shift = 31 - Integer.numberOfLeadingZeros(scale);
}
相关的注释在代码中,不再赘述,主要解答下几个疑问
- 为什么要验证scale大小是2的幂次方
- Integer.numberOfLeadingZeros(scale)的函数作用是什么
- 为什么要用31减去Integer.numberOfLeadingZeros(scale)
- 最终计算出来的shift值是干什么用的
相信第一次见这段代码的人都和我一样,对这段静态代码块中的每一行代码都有疑问😓,要解答这个问题,先去上面一章节复习下数组对象的内存结构。
第一个问题:为什么要验证scale大小是2的幂次方?
因为之后要用到位移的方式快速计算元素偏移地址,如果不是2的幂次方,通过位移计算的元素偏移地址就会出错。另外(scale & (scale - 1)) != 0这个代码用于快速校验是否是2的幂次方,这个技巧基于以下原理:如果一个数是2的幂次方,那么它的二进制表示中只有最高位一个1,其余位都是0。如果 scale 是2的幂次方,那么 scale - 1 的二进制表示中,除了最高位变成0外,其余所有位都是1。假设 scale 是8,即 scale 的二进制表示是 1000,scale - 1 是7,即 scale - 1 的二进制表示是 0111,当进行按位与操作 (8 & 7),结果就是是0。
第二个问题:Integer.numberOfLeadingZeros(scale)的函数作用是什么
该方法用于计算整数值转换为二进制格式后,前导零的个数(即从最高位开始连续的0的个数)。这个方法可以帮助确定一个整数在二进制表示中最高位1之前有多少个0。
第三个问题:shift值的作用是什么
shift值实际上就是之前说的位移位数,16+i<<2 ,它就是这个公式中的2。31减去4的二进制(100)的前导零的个数29(32-3=29),正好是2,因为位移运算计算的是次数,不包含4所在的二进制位置,所以要用31减,实际上算出来的就是4的二进制100中1后面的0的个数,这也侧面解释了为什么scale必须是2的幂次方。
byteOffset方法
搞清楚了静态代码块,接下来看看计算偏移量byteOffset方法的实现。byteOffset方法是根据数组坐标查询内存偏移量的方法。
//根据数组坐标查询内存偏移量
private static long byteOffset(int i) {
return ((long) i << shift) + base;
}
在上一个章节中,最后推导出来一个结论:对于一个int类型的数组,比如int[] array,使用偏移量寻址的方式,可以使用i<<2 + 16的方式计算元素的偏移量,这里的代码逻辑和我们之前的推导完全一致,因为以上的推导就是根据这个方法反推的😀。
get方法
最后看看get方法(OMG终于到了最终方法)
//调用unsafe方法根据偏移量获取某个方法的值
private int getRaw(long offset) {
return unsafe.getIntVolatile(array, offset);
}
前边一长串都在计算offset偏移量的值,现在到了真正取值的地方了我反而有个疑惑:为什么要大费周章的这么取值,不能直接array+下标直接取吗?
//通过final保证可见性
private final int[] array;
array变量被final修饰,具备了不可变性,同时也具备了可见性,所以unsafe类为什么要getIntVolatile方法获取元素值呢?从方法名字上来看该方法似乎有volatile关键字的语义,在这里是用于保证可见性的。我觉得这个问题的原因在于使用 final 修饰数组确实可以保证数组引用的不可变性,即数组引用不能被重新赋值,但是 final 修饰的数组引用并不能保证数组元素的不可变性,也不能保证数组元素的可见性。
即使数组被声明为 final,在多线程环境下,如果一个线程修改了数组中的元素,其他线程不一定能立即看到这个变化,这可能会导致线程之间的数据不一致性。
所以才要用unsafe类的getIntVolatile方法保证可见性(volatile关键字可不能加到数组元素上)。
三、其它方法
public final long getAndSet(int i, long newValue);
public final boolean compareAndSet(int i, long expect, long update);
public final long getAndIncrement(int i);
public final long getAndDecrement(int i);
public final long getAndAdd(int i, long delta);
public final long incrementAndGet(int i);
public final long decrementAndGet(int i);
......
可以看到,这些方法和AtomicInteger基本上一模一样,只是每个方法都多了一个i参数。
以上方法大同小异,底层都调用了getAndAdd方法
public final long getAndAdd(int i, long delta) {
return unsafe.getAndAddLong(array, checkedByteOffset(i), delta);
}
可以看到,i就是数组坐标,最终用checkedByteOffset方法计算了偏移量。本质上和AtomicInteger是一模一样的,详情可参考:《CAS原子类:AtomicInteger源码解析》。
四、我的疑惑
AtomicLongArray类中有两个方法
public final boolean compareAndSet(int i, long expect, long update) {
return compareAndSetRaw(checkedByteOffset(i), expect, update);
}
public final boolean weakCompareAndSet(int i, long expect, long update) {
return compareAndSet(i, expect, update);
}
这俩方法不是一模一样的吗,为啥AtomicInteger有的问题,在AtomicLongArray类中也有。。。
都看到这里了,欢迎关注我的博客呀(〃∀〃): https://blog.kdyzm.cn,欢迎到我的博客留言:https://blog.kdyzm.cn/messageBoard
END.

