分布式任务调度系统:xxl-job
任务调度,通俗来说实际上就是“定时任务”,分布式任务调度系统,翻译一下就是“分布式环境下定时任务系统”。
xxl-job一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
gitee地址:https://gitee.com/xuxueli0323/xxl-job
中文文档地址:https://www.xuxueli.com/xxl-job/
文档就已经说得足够详细,接下来就我的使用体验上来说说使用方法和出现的问题(本篇文章基于2.2.0版本讲解,2.2.0和最新的2.3.0版本使用上有些差异,可以参考源代码中的example项目进行修改)。
一、为何选用xxl-job
需求:服务有两个实例,要求做一个定时任务,每隔一个小时更新一批数据。听起来挺简单的一个需求,但是要考虑的事情挺多
- 如何保证两个服务同时间只有一个实例在运行跑批程序
- 如果程序一个小时未执行完任务,那到了下一次跑批的时间,改如何处理下一次跑批请求
- 每次跑批是否需要随机选择一个实例运行跑批程序
- 如果任务失败了,该如何处理
- ......
如果我们自己来做这个事情,可能需要redis或者数据库锁以保证同时间只有一个实例运行跑批程序;同时,如果锁未释放,表示跑批程序未执行完毕,如果这时候又来了一个跑批请求,可以选择丢弃掉,也可以选择将其放入跑批队列,这时候可能需要一个消息队列,可以选择数据库或者redis作为存储;如果没有服务端协调处理跑批,那么每次跑批如何选择实例做跑批任务是比较困难的;如果跑批失败,可以选择重试或者不重试直接发送失败邮件通知,或者两者兼而有之。
上述解决方案是比较常用的第一时间能想到的解决方案,可以看到还是要做挺多开发任务的。现在有了xxl-job,这些工作都被它做掉了,使用者只需要关心跑批的业务逻辑即可。
二、运行xxl-job-admin
在当前时间2021-04-21时间点上,最新版本的xxl-job版本号是2.3.0,而公司使用的版本是2.2.0,所以这里我使用2.2.0为例进行说明。
首先下载完xxl-job的源代码,可以看到该项目是maven项目
├── doc
│ ├── db
│ ├── images
│ ├── XXL-JOB官方文档.md
│ ├── XXL-JOB架构图.pptx
│ └── XXL-JOB-English-Documentation.md
├── LICENSE
├── NOTICE
├── pom.xml
├── README.md
├── xxl-job-admin
│ ├── Dockerfile
│ ├── Dockerfile1
│ ├── pom.xml
│ ├── src
│ └── target
├── xxl-job-core
│ ├── pom.xml
│ ├── src
│ └── target
└── xxl-job-executor-samples
├── pom.xml
├── xxl-job-executor-sample-frameless
├── xxl-job-executor-sample-jboot
├── xxl-job-executor-sample-jfinal
├── xxl-job-executor-sample-nutz
├── xxl-job-executor-sample-spring
└── xxl-job-executor-sample-springboot
包含着三个模块
- xxl-job-admin:xxl-job服务端
- xxl-job-core:xxl-job客户端依赖
- xxl-job-executor-samples:提供了一些使用样例
xxl-job-admin的安装很简单,推荐使用docker安装的方式
0.运行数据库脚本
xxl-job-admin运行依赖于数据库,先运行xxl-job/xxl-job/doc/db/tables_xxl_job.sql脚本,这个脚本创建了xxl_job数据库以及一些表,这是xxl-job-admin运行的基础。
1.下载docker镜像并运行
https://www.xuxueli.com/xxl-job/#其他:Docker 镜像方式搭建调度中心:
下载镜像
docker pull xuxueli/xxl-job-admin:2.2.0
创建容器并运行
docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:{指定版本}
/**
* 如需自定义 mysql 等配置,可通过 "-e PARAMS" 指定,参数格式 PARAMS="--key=value --key2=value2" ;
* 配置项参考文件:/xxl-job/xxl-job-admin/src/main/resources/application.properties
* 如需自定义 JVM内存参数 等配置,可通过 "-e JAVA_OPTS" 指定,参数格式 JAVA_OPTS="-Xmx512m" ;
*/
docker run -e PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai" -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xuxueli/xxl-job-admin:2.2.0
2.自己打包docker镜像
下载完xxl-job-admin源代码后,切换到2.2.0 的tag
git checkout 2.2.0
然后切换到xxl-job-admin根目录,执行打包命令
mvn clean package
修改xxl-job-admin目录下的Dockerfile文件,添加PARAMS参数
ENV PARAMS="--spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai --spring.datasource.username=root --spring.datasource.password=passwod"
在Dockerfile所在目录执行以下打镜像命令
docker build . -t xxl-job-admin:v1
这样就打包好了镜像,创建容器的命令也很简单
docker run -p 8080:8080 -v /tmp:/data/applogs --name xxl-job-admin -d xxl-job-admin:v1
运行成功后,浏览器输入http://127.0.0.1:8080/xxl-job-admin/ 链接,进入登录页,使用admin/123456账号密码即可登录成功。
三、xxl-job的基本概念
运行xxl-job之后,打开 http://127.0.0.1:8080/xxl-job-admin/ 链接,可以进入登录页,输入admin/123456登录成功后看到以下页面
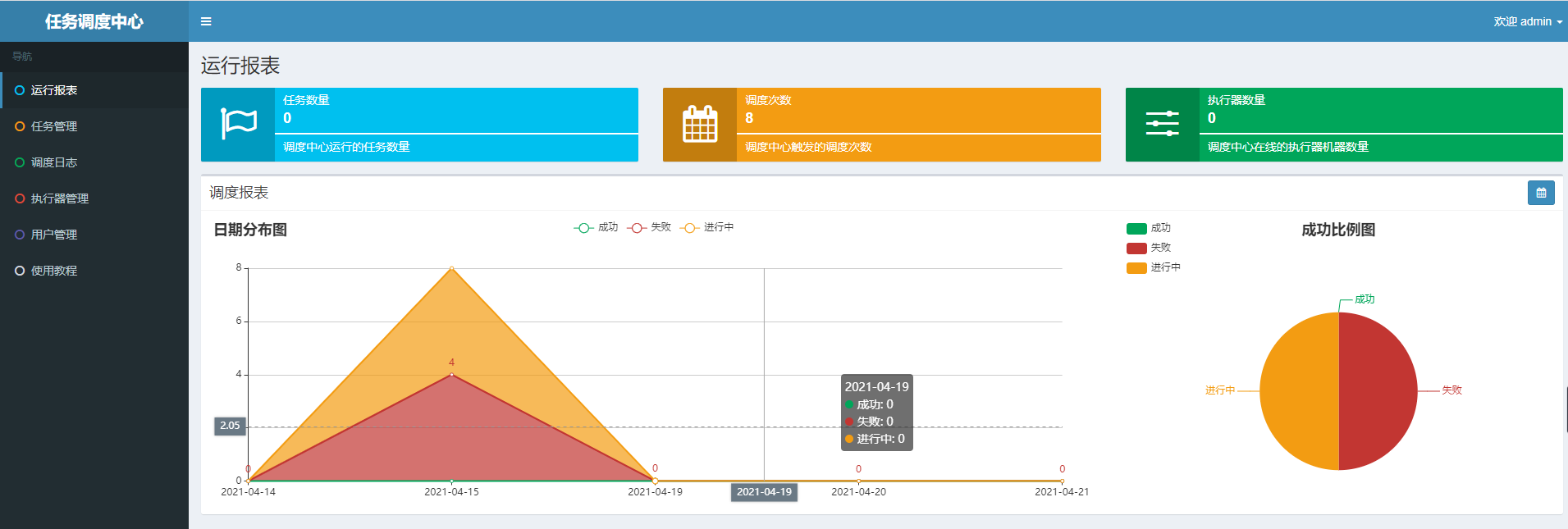
1.用户管理
可以创建修改、删除用户并且可以授权可以管理哪些执行器
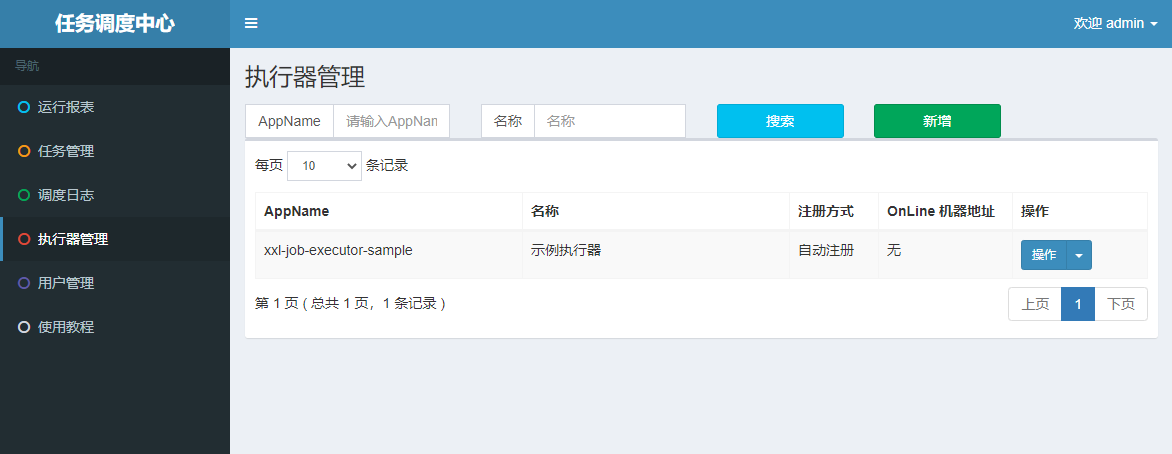
2.执行器管理
所谓的执行器,就是客户端,任务调度要执行器也就是客户端去执行具体的任务,执行器可以通过自动注册和手动注册两种方式注册到xxl-job-admin
3.任务管理
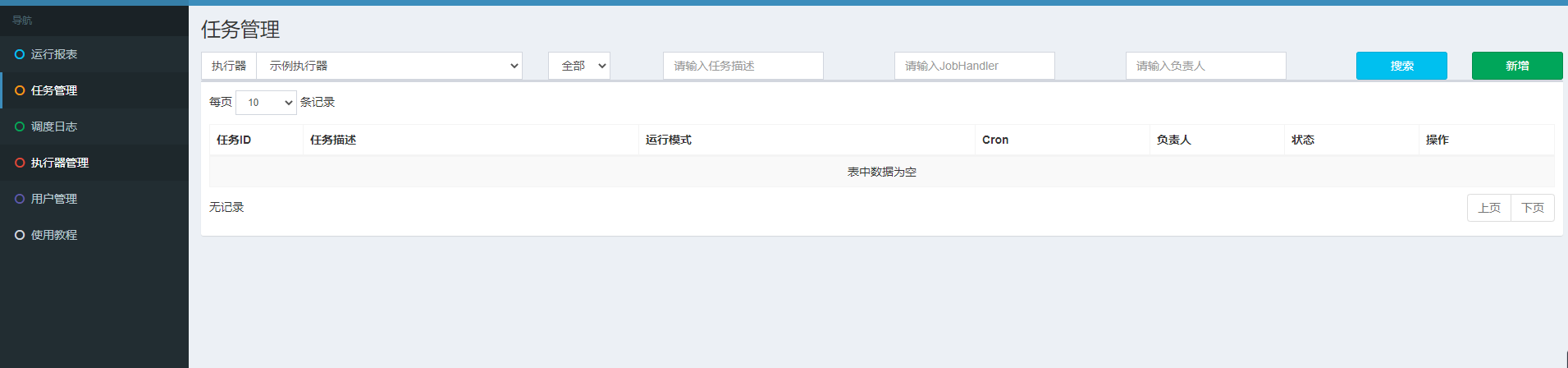
任务管理页面管理着所有调度任务,每个任务都属于某个执行器,在这里可以对任务进行CRUD操作,接下来单独说下新建任务页面
四、新建任务
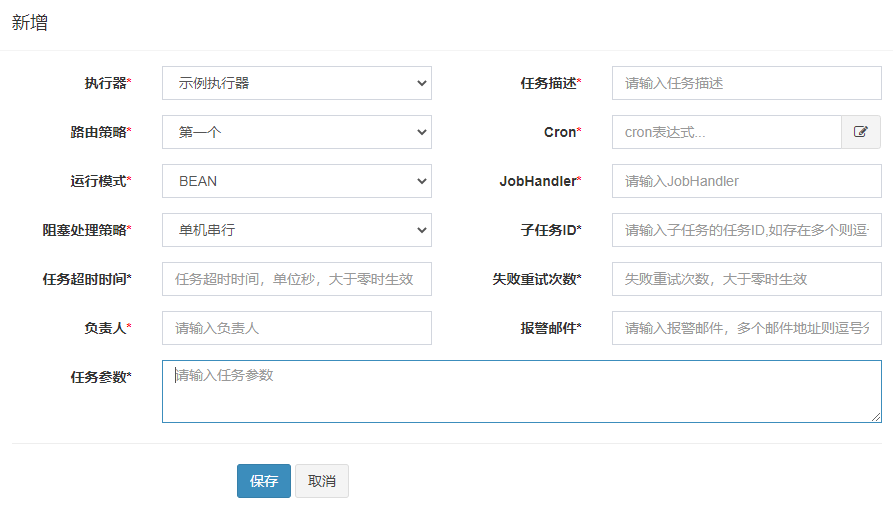
在任务管理页面点击新建会跳出该页面。
1.执行器
该任务属于哪个执行器,在新建任务前就要存在。
2.任务描述
略
3.路由策略
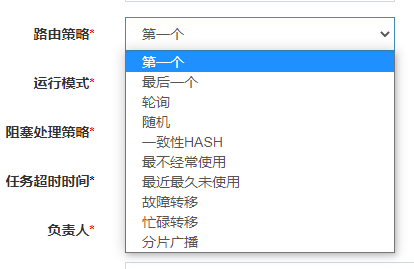
路由策略有很多,最经常使用的是第一个、轮询、随机策略
4.阻塞处理策略
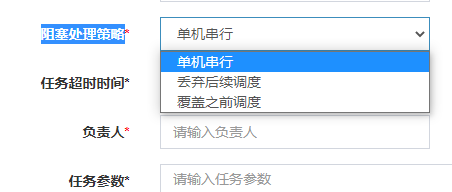
单击串行表示队列阻塞,前一个未完成则先放到队列中;丢弃后续调度表示前一个任务未完成,如果新的调度任务又开启了,则丢弃新的任务调度。
我最经常使用的是丢弃后续调度这个阻塞处理策略,一般跑批都没有严格的实时性要求,多一次少一次都无妨。
5.Cron
参考linux下crontab的写法。
6.JobHandler
执行器执行的handler,需要和java客户端的jobName保持一致。
7.运行模式
这里有很多中运行模式,但是最经常使用的是BEAN模式,这种模式下可以指定JobHandler,其它模式下均不可以。
五、实战
需求:每隔一个小时执行一次任务,更新所有用户的信息
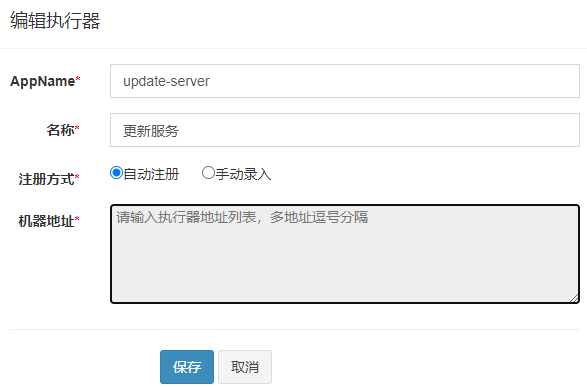
1.创建执行器
执行器也就是客户端,这里假设有个服务update-server作为执行器
则appName使用update-server,名称则使用更新服务,注册方式使用自动注册
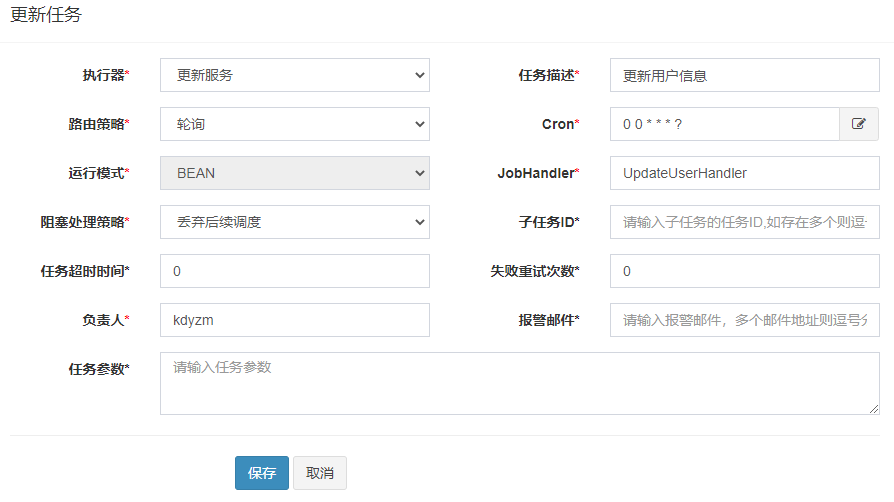
2.新建任务
Cron,每个小时的零分零秒执行任务:0 0 * * * ?
运行模式:BEAN
JobHandler:UpdateUserHandler
阻塞处理策略:丢弃后续调度
3.客户端配置
也就是执行器的配置了
客户端一般是java客户端,如何使用呢,在 源代码中有个sample模块,可以参考里面的使用方法,比如我在springboot中的使用,就可以参考xxl-job-executor-sample-springboot 模块。
3.1 配置文件配置xxl-job-admin
配置文件格式如下:
xxl:
job:
admin:
addresses: http://127.0.0.1:8080/xxl-job-admin
accessToken:
executor:
appname: update-server
logpath: ./logs
logretentiondays: 30
如何读取配置文件可以参考我的另外一篇文章:SpringBoot自定义配置以及IDEA配置提示
3.2添加maven依赖
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-commons</artifactId>
<version>2.1.2.RELEASE</version>
</dependency>
3.3创建XxlJobSpringExecutor单例对象
@Configuration
@Slf4j
@AllArgsConstructor
public class XxlJobConfiguration {
private InetUtils inetUtils;
private Environment environment;
private static final String PROFILE_DEV = "dev";
@Bean
public XxlJobSpringExecutor myXxlJobExecutor(XxlJobProperty xxlJobProperty) {
log.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(xxlJobProperty.getAdmin().getAddresses());
xxlJobSpringExecutor.setAppname(xxlJobProperty.getExecutor().getAppname());
xxlJobSpringExecutor.setAccessToken(xxlJobProperty.getAccessToken());
xxlJobSpringExecutor.setLogPath(xxlJobProperty.getExecutor().getLogpath());
xxlJobSpringExecutor.setLogRetentionDays(xxlJobProperty.getExecutor().getLogretentiondays());
if(isDevEnv()){
String ipAddress = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
xxlJobSpringExecutor.setIp(ipAddress);
if(Objects.nonNull(xxlJobProperty.getExecutor().getPort())){
xxlJobSpringExecutor.setPort(xxlJobProperty.getExecutor().getPort());
}else{
xxlJobSpringExecutor.setPort(9999);
}
}
return xxlJobSpringExecutor;
}
private boolean isDevEnv() {
String[] activeProfiles = environment.getActiveProfiles();
return Arrays.asList(activeProfiles).contains(PROFILE_DEV);
}
}
3.4 创建任务
这里的XxlJob注解中的value值要和xxl-job-admin中创建的Job名字保持一致
@Component
@Slf4j
public class CronTest {
@XxlJob("UpdateUserHandler")
public ReturnT<String> test(String param) throws Exception {
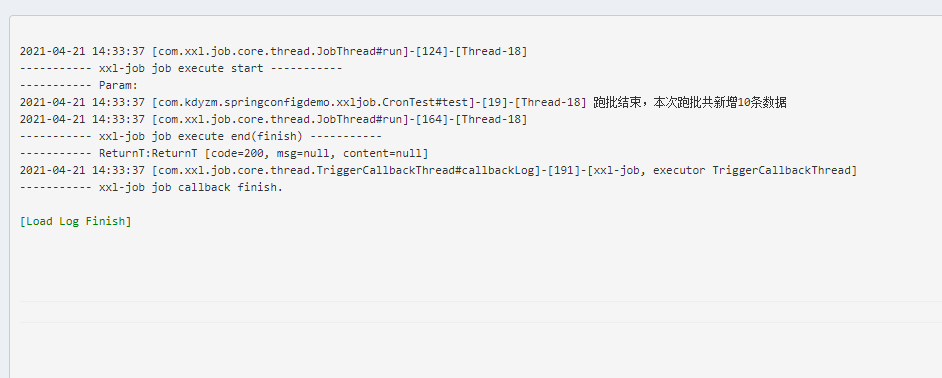
log.info("Hlelo,world");
XxlJobLogger.log("跑批结束,本次跑批共新增10条数据");
return ReturnT.SUCCESS;
}
}
4.测试
完成上述操作之后启动服务,如果没有报错信息,则到xxl-job-admin查看执行器注册情况
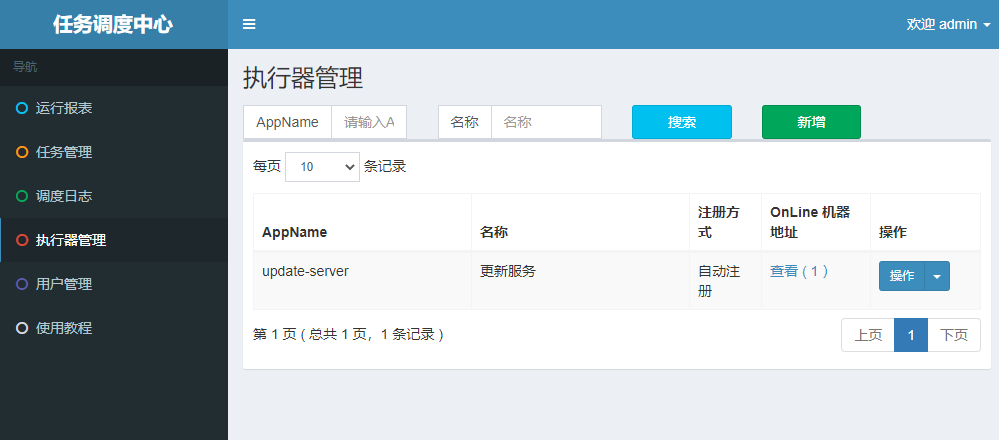
可以看到已经注册成功
在任务管理中执行一次任务调度
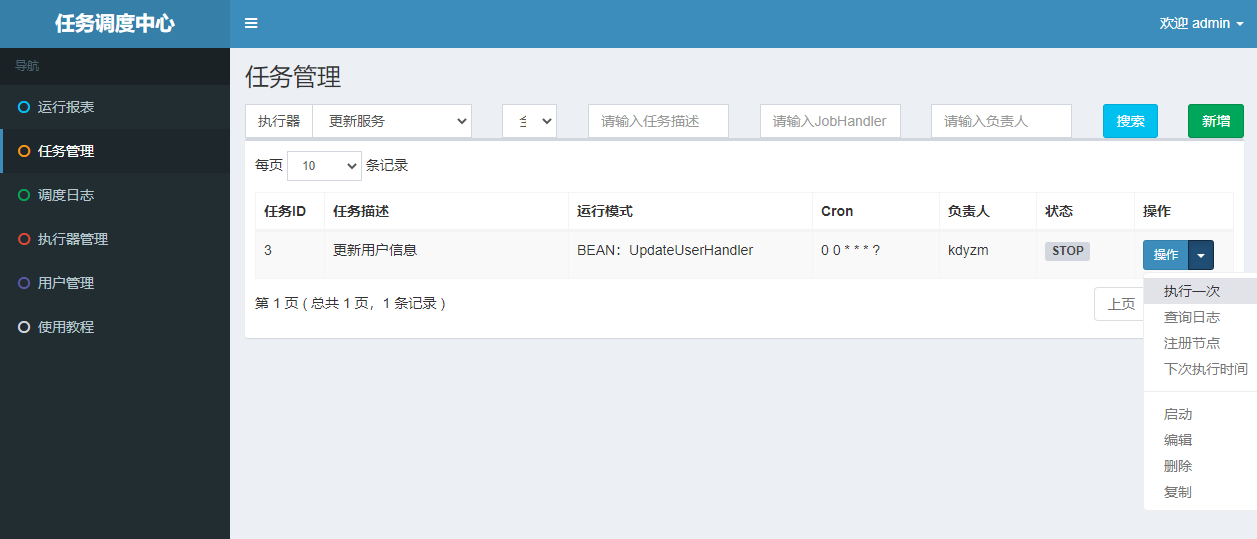
在客户端可以看到执行日志

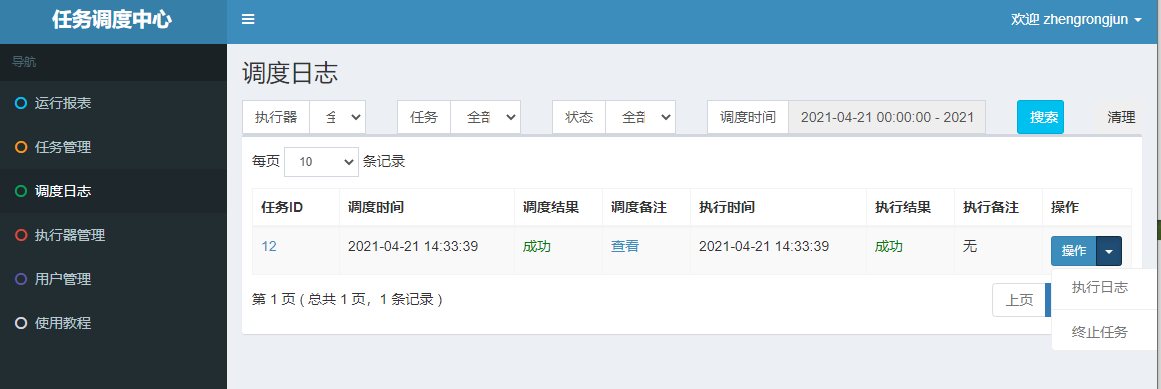
同时,在xxl-job-admin端也能看到执行结果日志
六、xxl-job的不足之处
xxl-job在客户端会单独开一个接口给xxl-job-admin使用,默认是9999端口号,如果9999端口号被占用,端口号会依次+1重试。我认为这里单独开一个端口号是完全没有必要的,浪费执行器资源先不谈,开两个端口号感觉就挺扯,像是swagger ui集成到spring-boot程序中也没有单独开一个端口号啊。。
最重要的是多开一个端口号没问题,问题是这个端口号都是9999,这里假设几个场景,看看怎么做
- 所有服务都使用了xxl-job,部署在同一个ECS机器上。每个服务都想占用默认的9999端口号,第一个占用成功了,第二个端口号10000,第三个依次增加1。。。。在这个场景下没问题,每个java程序共享ECS资源,可以探知端口号占用情况,无端口号冲突。
- 所有服务都使用了xxl-job,都使用docker部署,部署在同一个ECS机器上。这时候就不好办了,运行在docker中的java程序无法知道其他docker中的java程序运行情况,因为docker把环境隔离了,只能由docker开放指定端口号和容器内运行的java程序端口号映射。这就极大增加了运维成本。
我认为正确的做法就是复用原来的端口号,这样一个端口号就能解决问题。
实际上已经有人提了PR:改造在SpringBoot环境下,直接使用SpringBoot端口 但是迟迟没有被合并,实际上这个开源项目下的issue已经多达五百多个,PR数量也已经近四十个,其实这个项目还是有人继续维护的,最近的2.3.0版本release在两个月以前,但是这么多issue和pr都没人管,说明作者实际上不关心使用者的感受,只能这么认为了。
如果想定制化某些功能,那就去修改源代码吧,God bless you~



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 一个费力不讨好的项目,让我损失了近一半的绩效!
· .NET Core 托管堆内存泄露/CPU异常的常见思路
· PostgreSQL 和 SQL Server 在统计信息维护中的关键差异
· C++代码改造为UTF-8编码问题的总结
· DeepSeek 解答了困扰我五年的技术问题
· 清华大学推出第四讲使用 DeepSeek + DeepResearch 让科研像聊天一样简单!
· 推荐几款开源且免费的 .NET MAUI 组件库
· 实操Deepseek接入个人知识库
· 易语言 —— 开山篇
· 【全网最全教程】使用最强DeepSeekR1+联网的火山引擎,没有生成长度限制,DeepSeek本体