

一、基本概念
进程是资源分配的基本单位,而线程则是CPU调度和分派的基本单位。系统需要执行创建进程、撤销进程和进程切换等任务,但创建进程开销大限制了并发的提高。因此,成百上千个进程会造成内存浪费,并且频繁切换导致每个进程执行(时间变短)效率降低。因此有了线程的概念。
引入进程的目的是为了使多个程序并发执行,以改善资源利用率、提高系统吞吐量;引入线程的目的则是为了减少程序并发执行时造成的时空开销。即线程既能降低系统资源频繁切换,又能满足进程这种多任务并发异步执行的功能。
线程和进程关系:
1.一个进程可以有多个线程,但至少要有一个线程;一个线程只能在一个进程的地址空间内活动。
2.资源分配给进程,同一进程的所有线程共享该进程内的所有资源。
3.处理机分配给线程,真正在处理机上运行的是线程。
4.线程在执行过程中需要协作同步。不同进程的线程要利用消息通信的办法实现同步。
5.由于线程拥有较少的资源,但又具有传统进程的许多特性,因此线程可被称为轻型进程(light weight process, LWP),传统进程相对称为重型进程(heavy weight process, HWP)。
6.一个线程可以创建和撤销另一个线程
线程优点:易于调度;提高并发量;开销少;能够充分发挥多处理器的功能。
线程模型:和进程一样,包括TCB(Thread Controller Block 线程控制块)、程序和数据。Thread结构包括线程标识符、调度状态信息、核心栈指针、用户栈指针及私有存储区等。
内核级线程和用户级线程:
- 内核级线程(Kernel Supported threads,KST):内核控制线程的创建、撤销和切换,并为每个内核级线程创建TCB,从而感知其存在。内核级线程的优点是:1.在多处理器上,内核可以调用同一进程中的多个线程同时工作;2.如果一个进程中的某个线程阻塞,其他线程仍然可以继续运行。其缺点是:由于线程由CPU调度和分派,用户态线程要经由操作系统进入内核,用户态不同进程的多个线程进行切换时,都要进入内核再进行切换,切换代价较大。
- 用户级线程(User Level Threads,ULT):开放给程序员的、可以通过线程库(如python的Threading.py)创建的线程。用户级线程只存在于用户空间,内核并不能看到用户线程,并且内核资源的分配仍然是按照进程进行分配的;各个用户线程只能在进程内进行资源竞争。用户级线程的优点是:1.同进程内线程切换不需要转换到内核空间,节省了内核空间;2.线程调度算法可以是进程内专用,由用户程序进行指定;3.用户级线程实现和操作系统无关。其缺点是:1.如果系统调用同一进程中某个线程时阻塞,整个进程阻塞;2.一个进程只能在一个cpu上获得执行。
- 用户级线程和内核级线程有着一对一、一对多和混合型的映射关系,具体映射关系由操作系统来决定。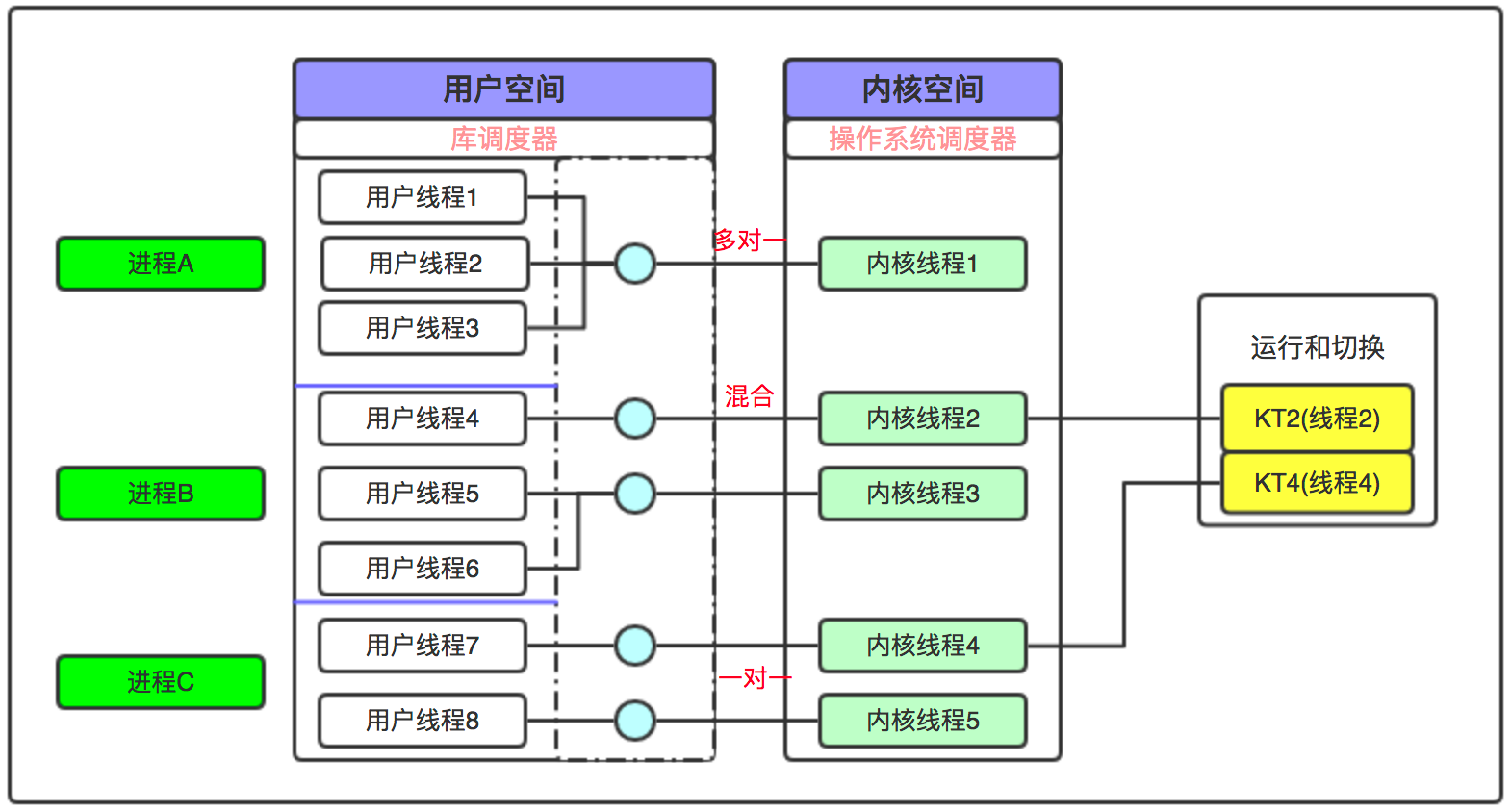
线程状态:线程的状态和进程类似。运行状态:线程在CPU上执行;就绪状态:具备运行条件,一旦分配到CPU就可以立即执行;阻塞状态:线程在等待某个条件的发生从而转为就绪状态。
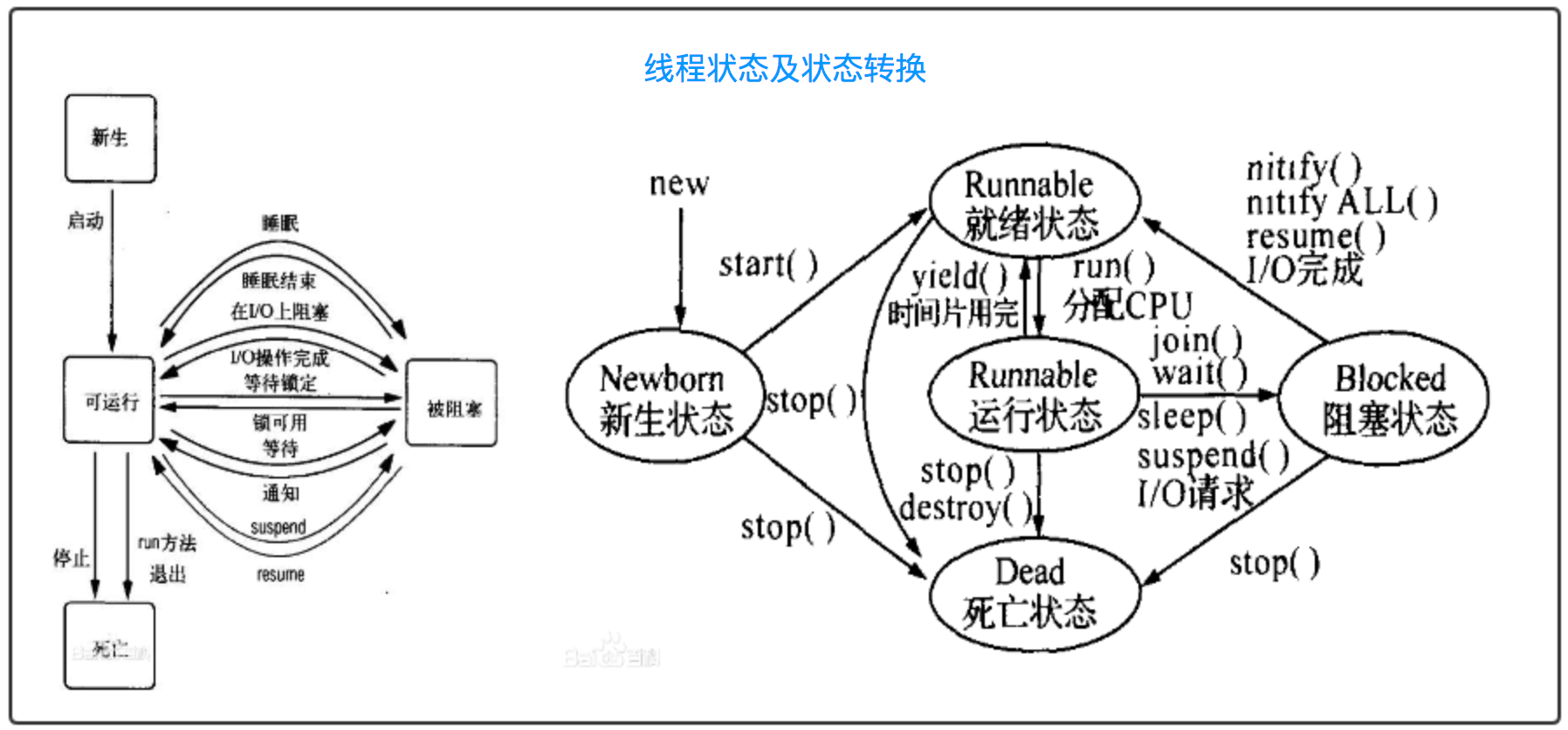
其它有关线程的概念都可以参考进程有关概念。
二、python线程模块
threading是Python中内置的线程模块,能够实现用户级线程的管理。在Cpython中,python中的一个线程对应c语言中的一个线程。
1.线程创建
线程创建可以通过函数或者子类的方式实现。The Thread class represents an activity that is run in a separate thread of control. There are two ways to specify the activity: by passing a callable object to the constructor, or by overriding the run() method in a subclass. No other methods (except for the constructor) should be overridden in a subclass. In other words, only override the __init__() and run() methods of this class。
from threading import Thread def desc(step): global num for i in range(step): # print("desc-----: ", num) num -= 1 print("----------num------------", num) def add(step): global num for i in range(step): # print("add: ", num) num += 1 print("----------num------------", num) if __name__ == '__main__': num = 0 # 由于共享进程资源,num被子线程共享 step = 1000 # 也可以作为参数传进去来共享变量,而进程必须用队列或者管道 p1 = Thread(target=desc, args=(step, )) p2 = Thread(target=add, args=(step, )) p1.start() p2.start() p1.join() p2.join() print(num)
以子类继承的方式重现上述逻辑。
from threading import Thread class Desc(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): print("desc-----: ", num) num -= 1 class Add(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): print("add: ", num) num += 1 if __name__ == '__main__': num = 0 step = 1000000 p1 = Desc(step) p2 = Add(step) p1.start() p2.start() p1.join() p2.join() print(num)

错误示例在于将共享变量赋给对象属性后,对对象属性进行了自增(自减运算)而没有操作共享变量num。

from threading import Thread class Desc(Thread): def __init__(self, step): super().__init__() self.step = step self.num = num def run(self): for i in range(self.step): print("desc-----: ", self.num) self.num -= 1 print("----------num------------", self.num) class Add(Thread): def __init__(self, step): super().__init__() self.step = step self.num = num def run(self): for i in range(self.step): print("add: ", self.num) self.num += 1 print("----------num------------", self.num) if __name__ == '__main__': num = 0 step = 1000 p1 = Desc(step) p2 = Add(step) p1.start() p2.start() p1.join() p2.join() print(num)
一些线程自带的函数。
from threading import Thread from threading import (active_count, current_thread, get_ident, enumerate, main_thread) import time class Example(Thread): def __init__(self): super().__init__() def run(self): print("current_thread: ", current_thread()) # 当前线程标识符 print("get_ident: ", get_ident()) # 当前线程 time.sleep(3) print("-------------------------------------------------") if __name__ == '__main__': p1 = Example() p1.start() # p1.setDaemon(True) # 守护线程,主线程结束子线程如果没结束就直接被kill掉 print("active_count: ", active_count()) # 活跃线程数:2 print("enumerate: ", enumerate()) # 当前进程内活跃的线程对象 p1.join() # 主线程等待子线程结束再结束/不写时主线程结束,子线程继续执行 print("active_count: ", active_count()) # 活跃线程数:1 - 主线程 print("current_thread: ", current_thread()) # 当前线程标识符 print("get_ident: ", get_ident()) # 当前线程 print("main_thread: ", main_thread()) # 主线程对象
2.全局解释锁GIL
如果将上面的step设置一个非常大的值,那么num值就有各种结果。这里(解释器Cpython)就要说到全局解释锁GIL (Global interpreter Lock)。它有两个特点:
1.设计之初为了追求简单,会在Cpython上加一把全局锁,能够控制多线程对同一资源的访问。但后来导致的问题是,在同一时刻只有一个线程在一个CPU上执行,也即多个线程无法利用多个CPU。
2.python会按照一定字节码数量(比如1000行字节码)和一定时间间隔(比如15毫秒)主动释放GIL锁。多个线程此时可以争抢GIL锁。这破坏了全局锁的初衷(限制多线程的资源访问,保证数据的准确性),导致GIL锁变得很鸡肋。
3.python会在遇到IO操作时会主动释放GIL。因此python多线程在做I/O操作时任务时(如爬虫)会具有优势。
因此,通过共享变量的方式进行线程间通信是不安全的。一般会通过队列的方式实现线程间通信,它是线程安全的(队列里的数据只有一份。。。)。
from threading import Thread from queue import Queue def desc(step): for i in range(step): num = q.get() - 1 print("desc-----: ", num) q.put(num) def add(step): for i in range(step): num = q.get() + 1 print("add: ", num) q.put(num) if __name__ == '__main__': q = Queue() # queue队列实现了线程安全 q.put(0) step = 1000000 p1 = Thread(target=desc, args=(step,)) p2 = Thread(target=add, args=(step,)) p1.start() p2.start() p1.join() p2.join() print(q.get())
3、Lock和Rlock,Semaphore
由于GIL锁的主动释放,在线程间共享变量进行同步计算时,会导致结果不准确,也就是多线程切换计算,会造成重复赋值的极端情况。实质上是在STORE_FAST这一步发生了切换。
import dis def add(num): num -= 1if __name__ == '__main__': print(dis.dis(add))
3 0 LOAD_FAST 0 (num)
2 LOAD_CONST 1 (1)
4 INPLACE_SUBTRACT
6 STORE_FAST 0 (num)
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
None
线程锁Lock是在保证原子操作的基础上,对共享变量进行同步限制。根据同步原语(获得锁 -- dosomething -- 释放锁),Lock有两个方法acquire和release。前者获取锁,release释放锁,中间部分则是不可分割的代码逻辑。线程锁是全局对象,用于操作所有线程。
from threading import Thread, Lock class Desc(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): lock.acquire() num -= 1 lock.release() class Add(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): lock.acquire() num += 1 lock.release() if __name__ == '__main__': num = 0 step = 1000000 lock = Lock() p1 = Desc(step) p2 = Add(step) p1.start() p2.start() p1.join() p2.join() print(num)
acquire和release的所包裹的代码要尽可能小,本例中只包含可能发生重复赋值(线程不安全)的那行代码,如此并不影响两个线程for循环的切换。
线程锁的弊端在于:1.线程会影响性能;2.会造成死锁。注意,这句话是相对多线程共享数据操作而言的,对于队列不适用。另外,acquire和release之间的状态是阻塞的。
Lock只能让acquire和release成对出现,当想要访问多个共享变量时,在一个锁内控制多个共享变量显然是不符合实需的,另外,在锁内加锁(嵌套锁)Lock也是无法实现的。
递归锁则可以实现上面的缺陷。它也要求有多少个acquire就要有多少个release。
from threading import Thread, Lock, RLock class Desc(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): lock.acquire() num -= 1 lock.release() class Add(Thread): def __init__(self, step): super().__init__() self.step = step def run(self): global num for i in range(self.step): lock.acquire() num += 2 lock.acquire() num -= 1 lock.release() lock.release() if __name__ == '__main__': num = 0 step = 1000000 lock = RLock() p1 = Desc(step) p2 = Add(step) p1.start() p2.start() p1.join() p2.join() print(num)
Lock和RLock都支持上下文管理,即with语句。
Semaphore基于Condition和RLock、Lock生成一个信号量("锁池"),而不是无限制的使用acquire和release。在多线程时,如果锁池内的锁被用完了,那么其它线程进入阻塞状态,等待占有锁的线程释放锁。
from threading import Thread, Semaphore, current_thread import time class Fn(Thread): def __init__(self, sm): super().__init__() self.sm = sm def run(self): self.sm.acquire() print('current_thread: {}, {}'.format(current_thread().name, current_thread().ident)) time.sleep(2) self.sm.release() if __name__ == '__main__': sm=Semaphore(3) t_list = [] for i in range(10): t = Fn(sm) t_list.append(t) for t in t_list: t.start()
4、线程同步
条件变量Condition用于线程间同步执行。线程同步和进程同步相似,实质上是通过线程锁互斥,将并行异步变成了串行同步(阻塞)。Condittion也是基于Lock和RLock实现的。
A condition variable obeys the context management protocol: using the with statement acquires the associated lock for the duration of the enclosed block.
官方解释提了两个重要的信息:1.可以用with语句创建condition,此时不用写acquire和release,只需要在with上下文内写逻辑即可;2.可以通过acquire和relrease获取和释放锁,逻辑写在锁内部。
The wait() method releases the lock, and then blocks until another thread awakens it by calling notify() or notify_all(). Once awakened, wait() re-acquires the lock and returns. It is also possible to specify a timeout.
wait和notify(notify_all)是一对方法。wait用于本线程阻塞,直到得到其它线程的notify通知,再从阻塞状态转到就绪状态(运行);notify用于本线程通知其它一个(notify_all是多个)线程,可以从阻塞状态转到就绪状态(运行)。请注意前文配图。
from threading import Thread, Condition class Poetry1(Thread): def __init__(self, con, poetry): super().__init__() self.poetry = poetry self.con = con def run(self): global lis with self.con: for line in self.poetry: lis.append(line) self.con.notify() self.con.wait() class Poetry2(Thread): def __init__(self, con, poetry): super().__init__() self.poetry = poetry self.con = con def run(self): global lis with self.con: for line in self.poetry: self.con.wait() lis.append(line) self.con.notify() if __name__ == '__main__': con = Condition() lis = [] poy1 = ["楚国多豪俊,", "每与豺狼交,"] poy2 = ["相比得剑术。", "片血不沾衣。"] p1 = Poetry1(con, poy1) p2 = Poetry2(con, poy2) p2.start() # 必须让wait的线程先跑起来,从新生状态转到阻塞状态,等待notify激活 p1.start() p1.join() p2.join() print("\r\n".join(lis))
"""
楚国多豪俊,
相比得剑术。
每与豺狼交,
片血不沾衣。
"""
第二种写法: con.acquire()和con.release()。
from threading import Thread, Condition class Poetry1(Thread): def __init__(self, con, poetry): super().__init__() self.poetry = poetry self.con = con def run(self): global lis self.con.acquire() for line in self.poetry: lis.append(line) self.con.notify() self.con.wait() self.con.release() class Poetry2(Thread): def __init__(self, con, poetry): super().__init__() self.poetry = poetry self.con = con def run(self): global lis self.con.acquire() for line in self.poetry: self.con.wait() lis.append(line) self.con.notify() self.con.release() if __name__ == '__main__': con = Condition() lis = [] poy1 = ["楚国多豪俊,", "每与豺狼交,"] poy2 = ["相比得剑术。", "片血不沾衣。"] p1 = Poetry1(con, poy1) p2 = Poetry2(con, poy2) p2.start() p1.start() p1.join() p2.join() print("\r\n".join(lis))
官方文档给出了惯用的线程锁的模型:
# Consume one item with cv: while not an_item_is_available(): cv.wait() get_an_available_item() # Produce one item with cv: make_an_item_available() cv.notify()
现在来复原这段代码:
生产者(Producer): 如果队列中的包子数量小于20,立刻生产10个包子;消费者(Consumer):如果队列中的包子数量大于20,立刻消费3个包子。
设置4个生产者和10个消费者,开启循环。
from threading import Thread, Condition, current_thread from queue import Queue import time class Producer(Thread): def __init__(self, con, q): super().__init__() self.con = con self.q = q def run(self): while True: with self.con: while self.q._qsize() > 20: self.con.wait() for i in range(10): self.q.put("包子") print("{}: 生产了10个包子.".format(current_thread().name)) self.con.notify() class Consumer(Thread): def __init__(self, con, q): super().__init__() self.con = con self.q = q def run(self): while True: with self.con: while self.q._qsize() < 20: self.con.wait() time.sleep(2) for i in range(3): self.q.get() print("{}: 消费了3个包子。".format(current_thread().name)) self.con.notify() if __name__ == '__main__': q = Queue() con = Condition() t_list = [] for i in range(4): t = Producer(con, q) t_list.append(t) for i in range(10): t = Consumer(con, q) t_list.append(t) for t in t_list: t.start() for t in t_list: t.join()
5、线程池
concurrent.futures实现了线程池。concurrent.futures提供了一致线程和进程的接口。
来一个简单的例子。
from concurrent.futures import ThreadPoolExecutor import time def fn(num): print(num) time.sleep(2) if __name__ == '__main__': executor = ThreadPoolExecutor(max_workers=2) # 创建一个线程池 executor.submit(fn, 100) executor.submit(fn, 200) # 提交执行,第一个参数是函数,第二个参数是函数的参数
官方示例:
import concurrent.futures import urllib.request URLS = ['http://www.foxnews.com/', 'http://www.cnn.com/', 'http://europe.wsj.com/', 'http://www.bbc.co.uk/', 'http://some-made-up-domain.com/'] # Retrieve a single page and report the URL and contents def load_url(url, timeout): with urllib.request.urlopen(url, timeout=timeout) as conn: return conn.read() # We can use a with statement to ensure threads are cleaned up promptly with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor: # Start the load operations and mark each future with its URL future_to_url = {executor.submit(load_url, url, 60): url for url in URLS} for future in concurrent.futures.as_completed(future_to_url): url = future_to_url[future] try: data = future.result() except Exception as exc: print('%r generated an exception: %s' % (url, exc)) else: print('%r page is %d bytes' % (url, len(data)))
现在来改写上一章节多进程爬取天龙八部小说的代码。
from concurrent.futures import ThreadPoolExecutor, as_completed from threading import Thread from queue import Queue import urllib from bs4 import BeautifulSoup class UrlMaker(Thread): def __init__(self, number): super().__init__() self.number = number def run(self): num = 2024354 for i in range(self.number): url = "https://www.ybdu.com/xiaoshuo/10/10237/{}.html".format(num) q.put(url) print(url) num += 1 q.put("over") def urlParser(file): url = q.get() # 从列表中获取url if url == "over": return { "code": False, "url": False, } else: html = urllib.request.urlopen(url) # 请求html html_bytes = html.read() # 读取字节数据 soup = BeautifulSoup(html_bytes, "html.parser") title = soup.find("div", attrs={"class": "h1title"}).h1.get_text() string = soup.find("div", attrs={"class": "contentbox", "id": "htmlContent"}).get_text() # 获取小说内容 lines = string.split() with open(file, mode="a", encoding="utf-8") as f: # 写入文件 f.write(title + "\r\n") for i, line in enumerate(lines[: -6]): f.write(" " + line + "\r\n") return { "code": True, "url": url, "title": title, } def callback(msg): if msg["code"]: print("Process handled url: {}, title: {}.".format(msg["url"], msg["title"])) else: print("All urls had parsed.") if __name__ == '__main__': q = Queue() executor = ThreadPoolExecutor(max_workers=5) p1 = UrlMaker(10) p1.start() p1.join() task_list = [] for i in range(20): task = executor.submit(urlParser, "天龙八部1.txt") task_list.append(task) for task in as_completed(task_list): # as_completed是任务执行后的一些数据的封装 data = task.result() # 获取执行结果 print("Task: {} , data: {}.".format(task, data["url"]))

