
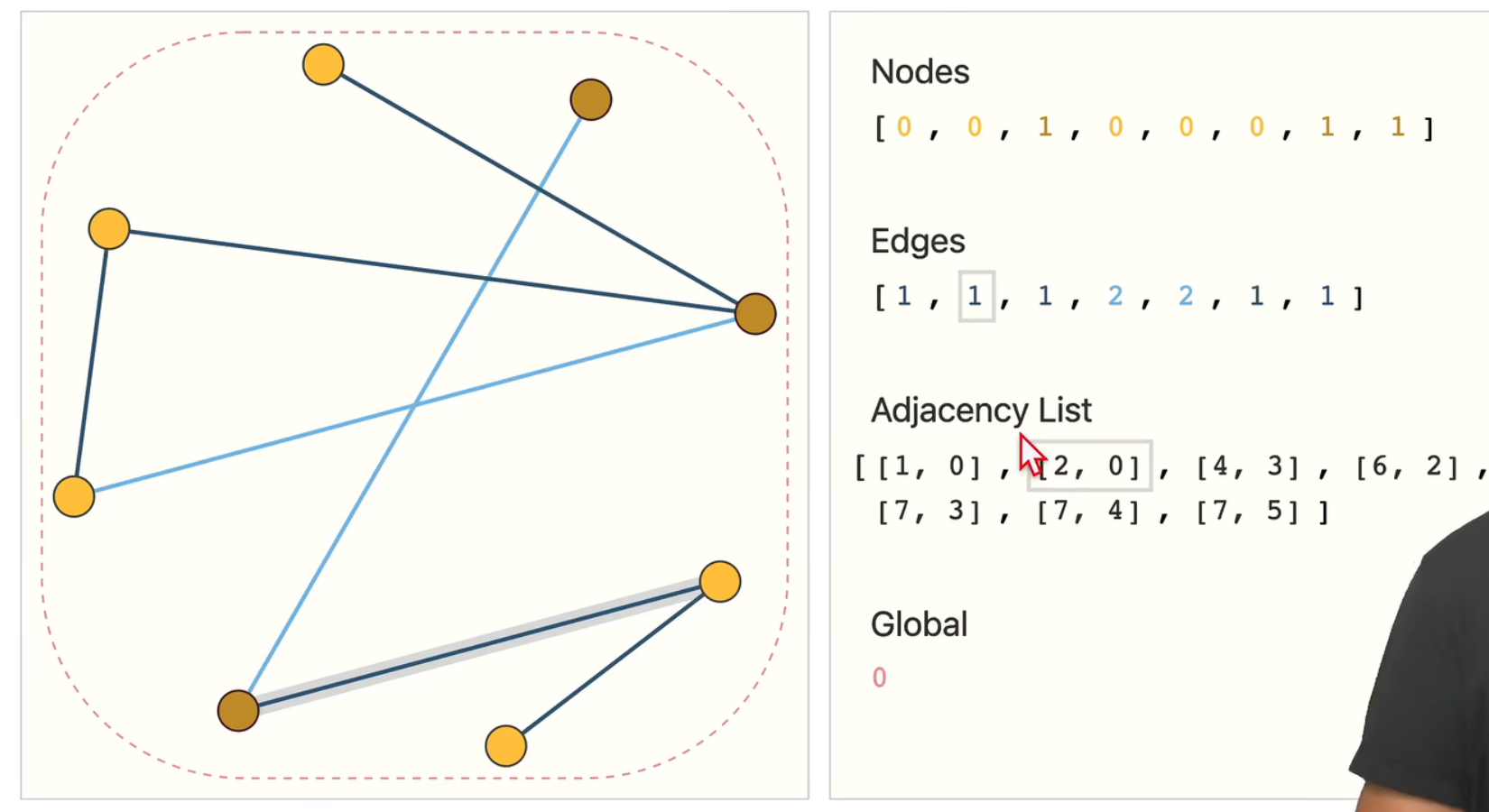
1.李沐课程-零基础多图详解图神经网络
一 前言
图是一个序列
图越深,上层的节点链接的下次节点越多
二 什么是图
1 图是表现一些实体之间的关系
实体:点 关系:边
核心:如何把想要的信息表示为图中的向量,并可以通过数据得到
2 三大类问题
(1)图层面的任务:整个图的识别
(2)顶点层面的任务:点的属性判断
(3)边级别上的任务:边的属性判断
3 图在神经网络的挑战
(1)怎么表示图,使得它和神经网络兼容
图的四种信息:点,边,全局信息,连接性
如果用矩阵来表示,考虑到矩阵大小,只能使用稀疏矩阵
但是稀疏矩阵高效计算很难,放在gpu也难
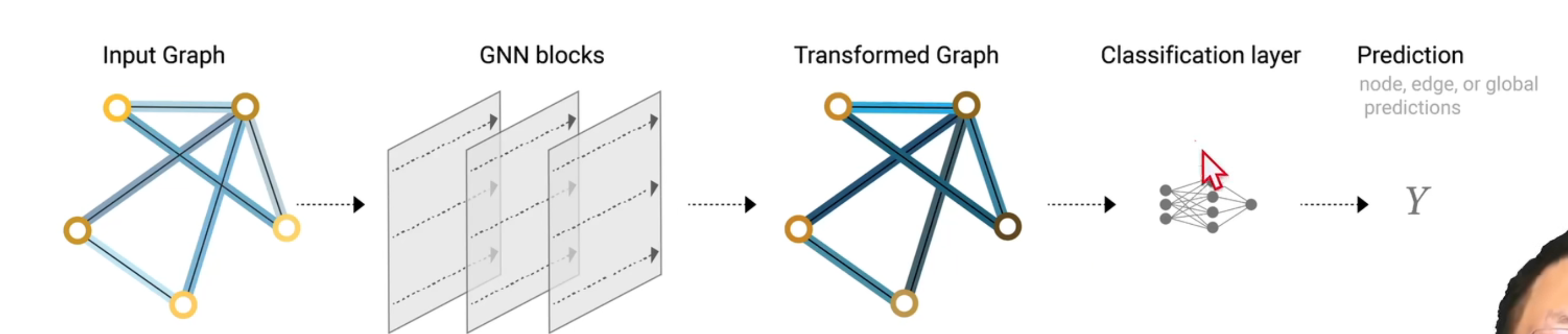
三 图神经网络
图的四种信息:点,边,全局信息,连接性
1 GNN定义:对图上的所有信息,进行一个可以优化的变换,并且能保持图的对称性
这种优化,不会因为排序不同,而产生不同的结果
输入是一个图,输出也是一个图
只对点和边和全局信息进行一个变换,但是不会改变连接性
2.最简易的GNN
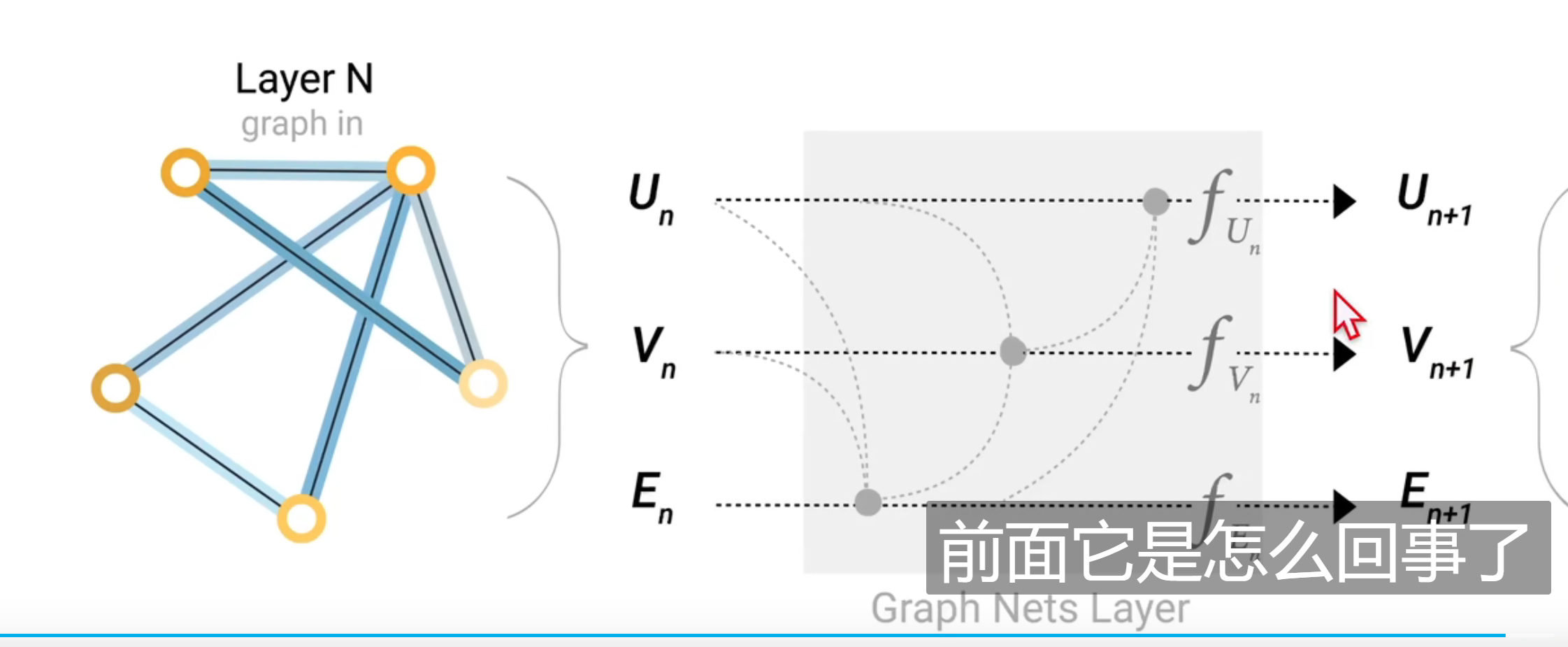
总览:
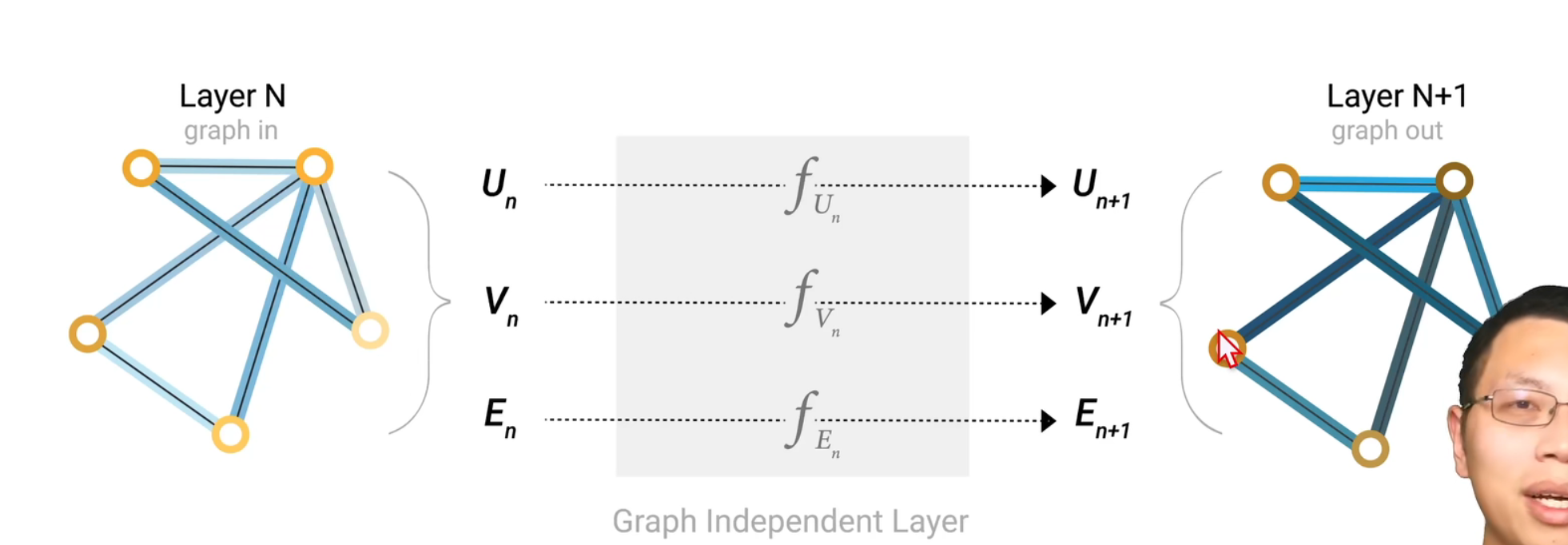
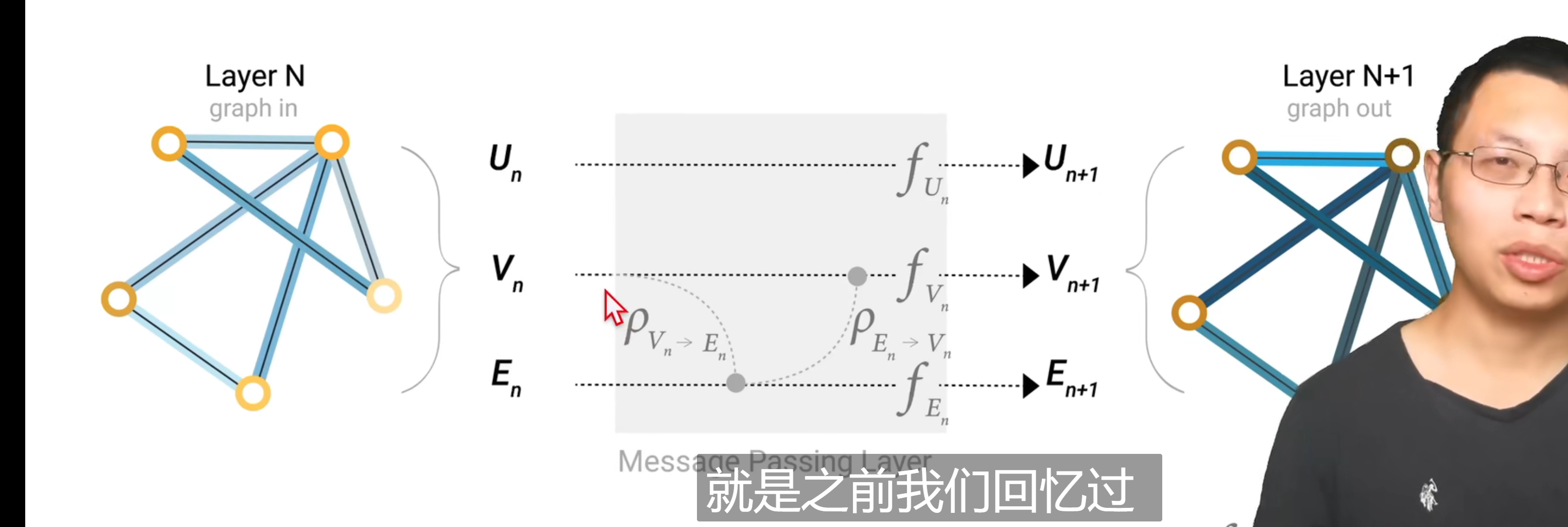
将全局信息U 点的信息V 边的信息E 都输入到对应的MLP中
这些MLP组合在一起构成了GNN的层,对属性进行了一个更新
最后的输出得到结果:
将所有数据,输入到一个全连接层(二分类就连接层输出为2,n分类就连接层输出为n)
所有的顶点共享连接层的参数
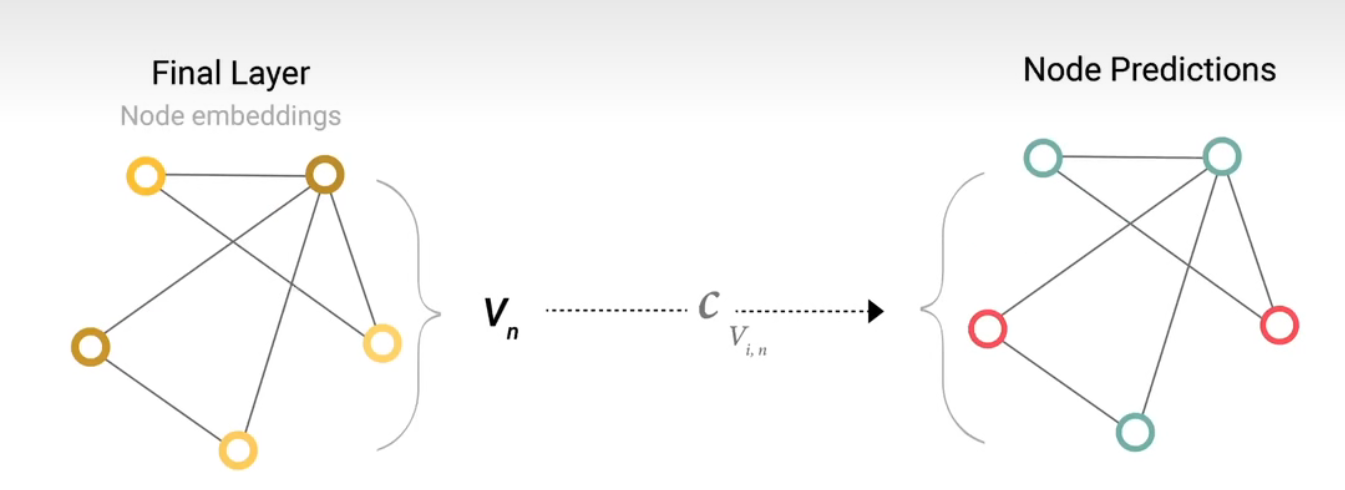
如果一个 点没有向量,想对他做出预测,使用polling(汇聚)
将全局信息和连接这个点的变信息取出来,汇聚到一起代表这个点
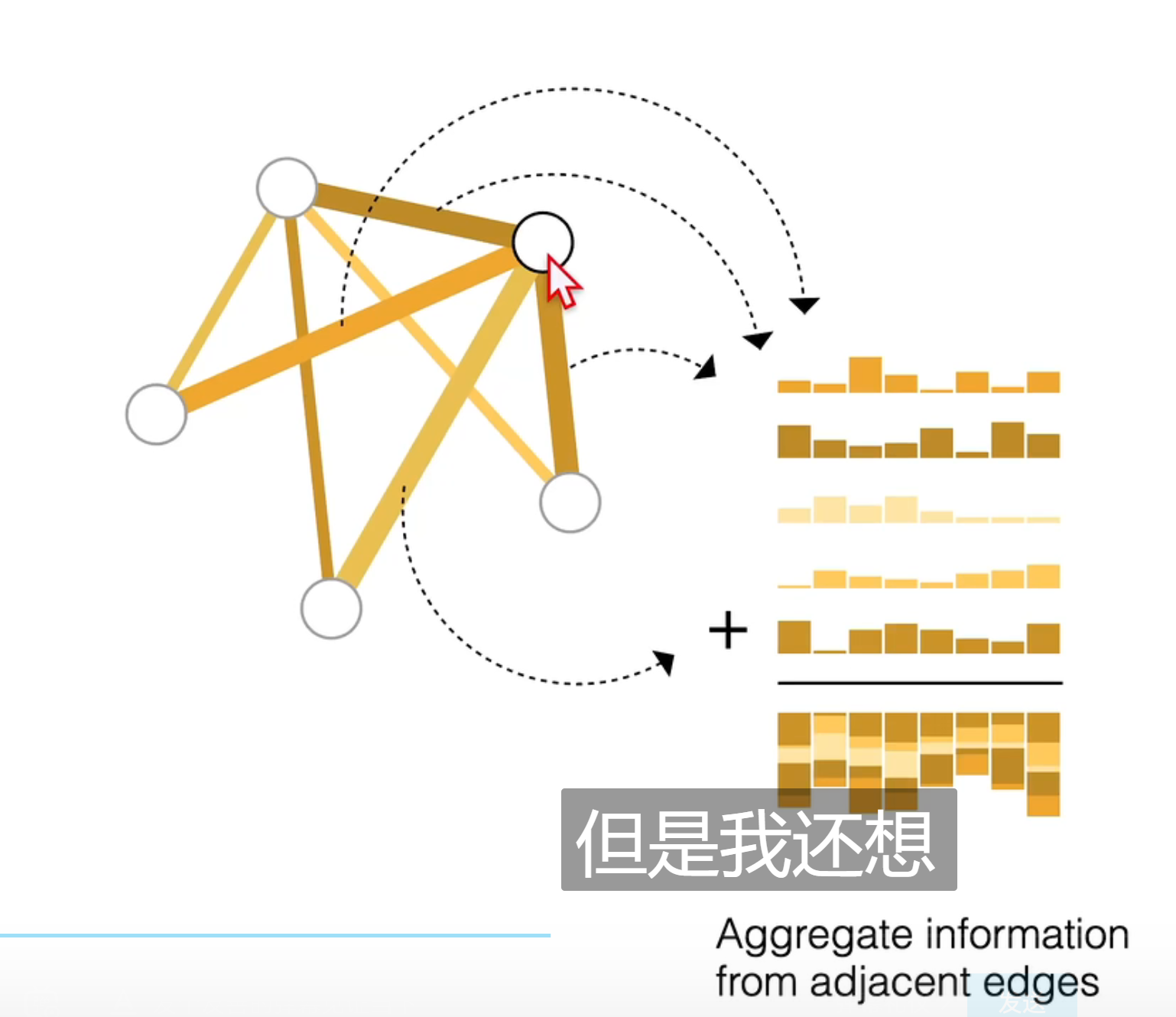
最后将汇聚得到的向量,代理点的向量,输入的连接层,得到顶点的输出
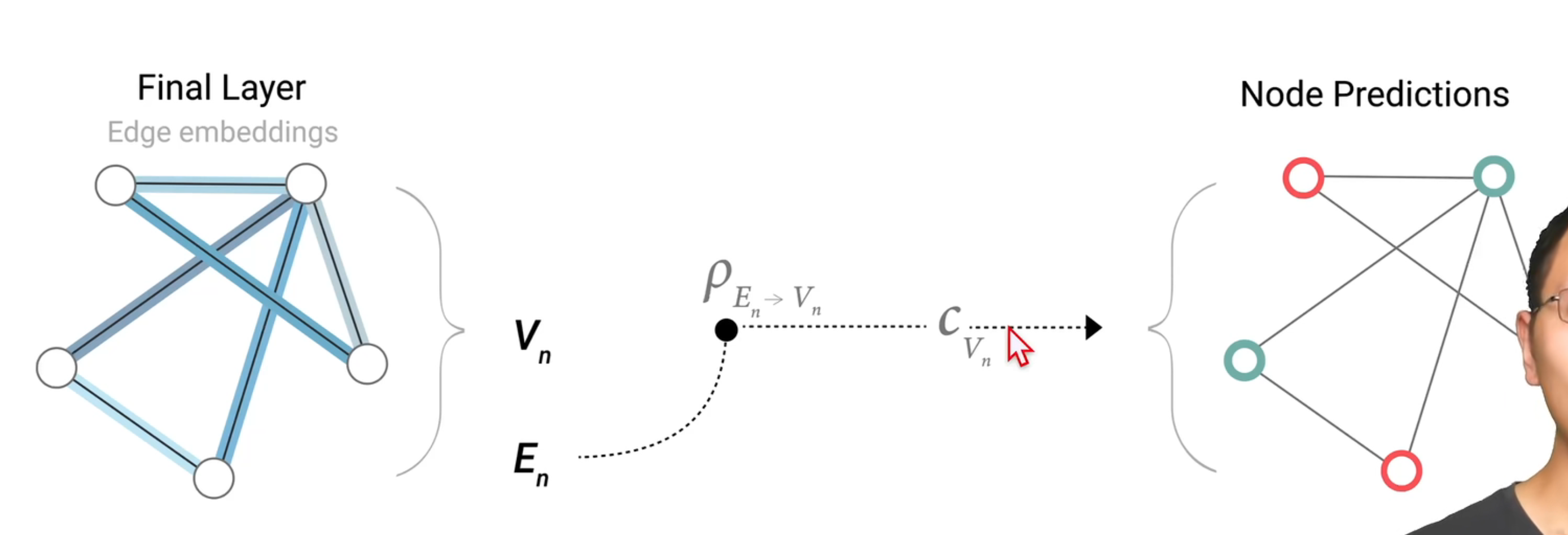
同样的道理,可以代替边和全局向量
缺陷:只是单纯在做属性的变换,并没有边得连接信息
3 信息传递
更新顶点向量时候,把邻居的向量添加进去

如果在最终的图结构的角度来看,最后的结果:顶点不仅会汇聚邻居的消息,也会汇聚邻居的邻居的消息
对比上述的预测模块中解决属性缺失问题,在最后的环节汇聚其他属性来弥补;消息传递更早的就进行了属性汇聚
这里是边把自己相连接的顶点的信息加到了自己的信息中
而顶点则是将自己所连接的边的信息加到自己的顶点信息中
维度不同,进行投影
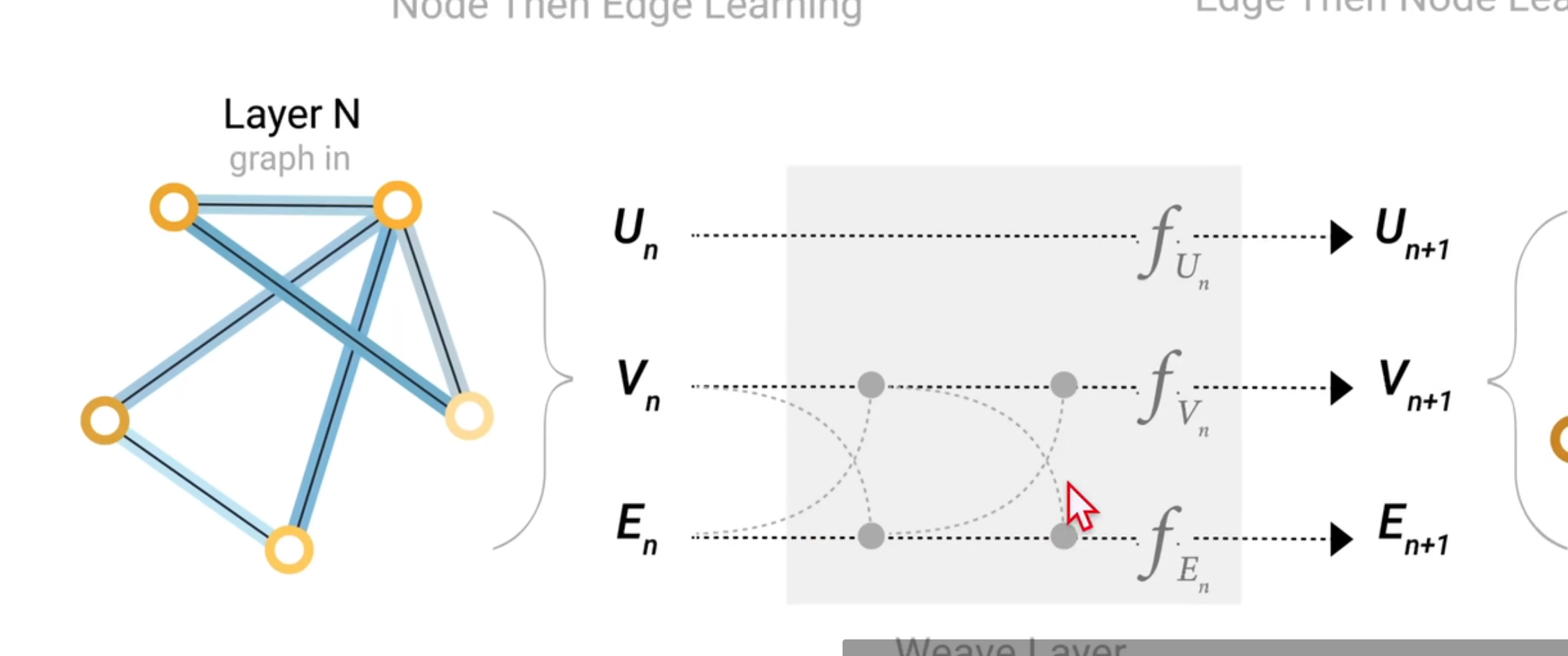
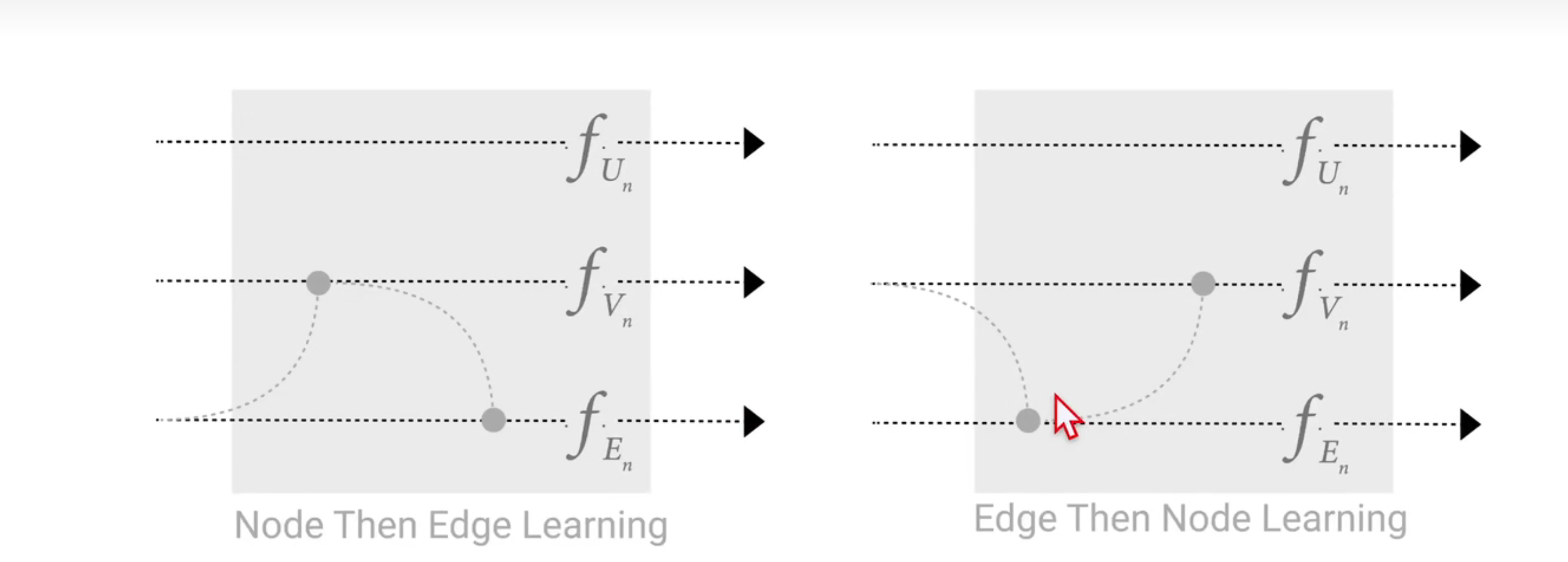
先把顶点信息给边,边更新了信息再给顶点
如果顺序相反,结果也是不同的
一种新的思路:二者同步进行,同时把边的信息汇聚到顶点,顶点的信息汇聚给边,然后再同时汇聚一次
解释为什么需要一个全局信息:
当图比较大,并且连接不是很紧密,从一个点传递消息到另一个点需要走很多步
加入一个虚拟点master node (context vector),这个点和所有的点相连和所有的边相连-------------------------就是全局信息U
因为U和所有的点和边相连,所以点和边更新信息时候,会把U的信息汇聚
同样的,U再更新信息时候,会把所有的点和边的信息汇聚
在最终环节里,可以使用的许多向量,比如相邻的顶点向量,连接的边的向量,全局信息

四 实验
五 相关技术
如果图的连通性比较好,最后的图的顶点就算只看一个近邻,由于消息传递机制,能够看到整个图的信息
在计算梯度时候,要在forwad中保存中间信息,对最后的图计算梯度时候,要保存整个图的中间信息,计算很困难
所以要进行采样,对采样的小图进行信息汇聚,计算梯度时候,只要保存小图的中间信息
1 随机采样 2 随机游走 3 将二者结合 4 取一个点做宽度遍历
GNN的假设基准是:保持了图的对称性,不论顶点顺序如何变换,GNN的作用不变
汇聚操作中,max sum mean需要自己去验证,没有哪一种方式是最佳的
GCN(MPNN)如果有K层,每一层只看一个邻居,类似于卷积网络中K层 3X3的卷积
图卷积作为矩阵乘法,和矩阵乘法在图上工作的关系
在图上做卷积和在图上做随机游走,等价于拿出邻居矩阵做一个矩阵乘法
图卷积和汇聚操作的区别:
前者是做一个加权和,每个量的权重不同,权重和位置是相关的,3X3的窗口中,固定的位置有固定的权重
后者的各个量的权重相同
如果是在图上做加权和,可以用注意力机制

