tomcat源码分析(二)请求到达的servlet的过程
一:tomcat部署应用的几种方式
1:最常见的war包部署。
把项目打包成war项目,丢到tomcat的webapps文件夹下面,启动tomcat的时候会自动解压。
2:直接部署文件夹
上面war解压后的文件夹,其实可以直接放到webapps文件夹下面,启动tomcat启动的时候也会把这个应用启动起来
3: 描述符部署,这个很少用到,这个是在tomcat/conf/server.xml里的Host节点下面新增:
<Context path="/HelloWorddddd" docBase="D:\tomcatweb\target\tomcat-web"></Context>
这个节点代表一个应用上下文,pathb代表应用的名称,docBase代表应用所在的路径,这个路径可以是tomcat外部的一个路径。tomcat启动后可以通过: http://localhost:8080/HelloWorddddd/ 访问到这个应用
部署是再HostConfig里面操作的,所以上面描述符部署是在Host节点下面部署。
/** * Deploy applications for any directories or WAR files that are found * in our "application root" directory. * 部署应用的三种方式 * 1. 描述符部署 * 2. War包部署 * 3. 文件夹部署 * * 另外Tomcat中是使用异步多线程的方式部署应用的 */ protected void deployApps() { File appBase = appBase(); File configBase = configBase(); String[] filteredAppPaths = filterAppPaths(appBase.list()); // Deploy XML descriptors from configBase // 描述符部署 deployDescriptors(configBase, configBase.list()); // Deploy WARs // war包部署 deployWARs(appBase, filteredAppPaths); // Deploy expanded folders // 文件夹部署 deployDirectories(appBase, filteredAppPaths); }
以war包部署为例看到代码里面写死的
二:容器
从上面描述符定义一个了一个应用看到,它是一个Context,在tomcat中Context就是管理Servlet的,可以说Context就是一个Servlet容器。在tomcat中Context是一个接口它继承了Container接口,是一个容器。在tomcat中容器的接口类图:

主要的几个容器接口Engine,Host,Context,Wrapper,在server.xml中也可以看出层级结构。

Engine:
管理Host,因为可以配置多个Host。
List<Host>
Pipeline pipeline
Host:
管理<Context>的,代表一个虚拟主机,可以配置多个Host节点用来隔离应用,默认有一个localhost。name可以配置一个域名。
List<Context>
Pipeline pipeline
// name 可以配置有一个域名,appBase:应用所在的目录就是默认的那个webapps, unpackWARs: 是否解压war包 autoDeploy :热部署
<!-- 配置多个Host虚拟主机的话,就要区分name了,其他虚拟主机的name要是可以访问的域名, 其他虚拟机主机找不到应用回到这个localhost下面-->
<Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> <!-- SingleSignOn valve, share authentication between web applications Documentation at: /docs/config/valve.html --> <!-- <Valve className="org.apache.catalina.authenticator.SingleSignOn" /> --> <Context path="/HelloWorddddd" docBase="D:\tomcatweb\target\tomcat-web"></Context> <!-- Access log processes all example. Documentation at: /docs/config/valve.html Note: The pattern used is equivalent to using pattern="common" --> <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" prefix="localhost_access_log" suffix=".txt" pattern="%h %l %u %t "%r" %s %b" /> </Host>
<!-- 访问当前Host虚拟主机的应用,日志都在这个里面,所以可以配置多个Host隔离不同的应用,日志也可以分开-->
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
Context:
代表一个应用上下文,它里面管理Servlet,但是由于可能会有多种类型的Servlet,比如单例的,多例的,如果都存在List<Servlet>中,结构不清晰,所以有了,Wrapper,它表示某一类Servlet。
也就是Context管理Wrapper。
List<Wrapper>
Pipeline pipeline
Wrapper: 下面管理具体的Servlet.一个Wrapper对应一个Servlet类型,下面的List<Servlet>对应它Servlet的实例。
List<Servlet> (表示这类servlet有多个实例),自定义的servlet可以实现 SingleThreadModel 接口,表示可以有多个实例。
Servlet (表示这类servlet只有一个实例)
Pipeline pipeline
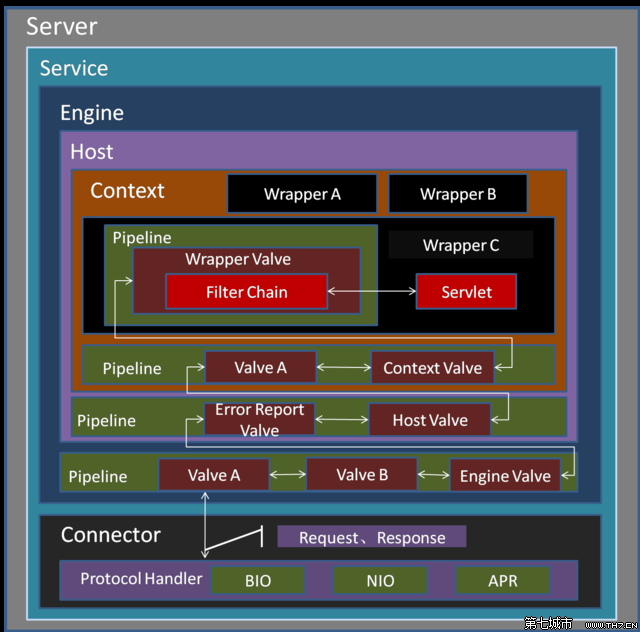
每个容器中都有一个Pipeline pipeline 的属性,翻译过来就是管道的意思,因为上面四个容器有层级关系,当请求到达Engine容器的时候,Engine并非是直接调用对应的Host去处理相关的请求,而是调用了自己的一个组件去处理,这个组件就叫做pipeline组件,
跟pipeline相关的还有个也是容器内部的组件,叫做valve组件。Pipeline的作用就如其中文意思一样管道,可以把不同容器想象成一个独立的个体,
那么pipeline就可以理解为不同容器之间的管道,道路,桥梁。那Valve这个组件是什么东西呢?Valve也可以直接按照字面意思去理解为阀门。pipeline是通道,valve是阀门。容器之间的通信就是通过管道+阀门实现的。一个容器的管道里可以定义多个阀门。默认都有一个默认阀门。
Pipeline
List<Valve>
tomcat数据的流通示意图:
我们可以在不同的容器里自定义自己的阀门。
public class PipeLineTest extends RequestFilterValve { @Override public void invoke(Request request, Response response) throws IOException, ServletException { System.out.println(" 自定义的Valve执行了");
// 管道的阀门是一个链表,执行完当前阀门,需要调用下一个阀门 getNext().invoke(request,response); } @Override protected Log getLog() { return null; } }
我们在server.xml中可以添加这个阀门: 在Host容器节点下面已经有了一个阀门了。

这样请求到Host级别的请求,都会执行到我们定义的valve。
四个容器在tomcat中有四个实现,而四个容器中都有一个基础阀门,并且这个基础阀门会一直在管道的最后一个,执行,用于把请求转到下一个容器执行。
StandarEngine:
有一个基础阀门,StandarEngineValve。这个阀门是管道中最后一个执行,用于把请求向下一个容器Host传递。
public StandardEngine() { super(); pipeline.setBasic(new StandardEngineValve()); /* Set the jmvRoute using the system property jvmRoute */ try { setJvmRoute(System.getProperty("jvmRoute")); } catch(Exception ex) { log.warn(sm.getString("standardEngine.jvmRouteFail")); } // By default, the engine will hold the reloading thread backgroundProcessorDelay = 10; }
同理:
public StandardHost() { super(); pipeline.setBasic(new StandardHostValve()); }
public StandardContext() { super(); pipeline.setBasic(new StandardContextValve()); broadcaster = new NotificationBroadcasterSupport(); // Set defaults if (!Globals.STRICT_SERVLET_COMPLIANCE) { // Strict servlet compliance requires all extension mapped servlets // to be checked against welcome files resourceOnlyServlets.add("jsp"); } }
public StandardWrapper() { super(); swValve=new StandardWrapperValve(); pipeline.setBasic(swValve); broadcaster = new NotificationBroadcasterSupport(); }
tomcat中的Servlet都是靠阀门来调用执行的。
我们定义的Servlet中,只实现doGet方法就可以了,而且方法参数是两个request,response接口,那它怎么被调用,两个参数的实现类到底是什么呢?
Servlet是在Wrapper最后一个阀门执行完调用,得到Servlet实例然后调用doGet方法,而方法中的两个参数分别是:RequestFacade,ResponseFacade 实例,这里采用的是门面模式,里面调用的是另外的实例:Reuest, Response.
我们看下怎么从阀门调用到Servlet的。
我们定义一个一个Servlet:
public class HelloWorldServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { resp.getWriter().write("helloword"); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doGet(req,resp); } }
<web-app>
<display-name>Archetype Created Web Application</display-name>
<servlet>
<servlet-name>helloworld</servlet-name>
<servlet-class>com.indigo.HelloWorldServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>helloworld</servlet-name>
<url-pattern>h.do</url-pattern>
</servlet-mapping>
</web-app>
我们在Wrapper的最后一个阀门StandardWrapperValve 中打个断点,阀门的调用的入口是invoke方法。

页面发起请求之后,走到StandardWrapperValve#invoke方法,这个类里会从容器中获取wrapper= (StandardWrapper) getContainer()。 wrapper.allocate()得到的就是一个Servlet实例,这里就是我们自定义的Servlet。

创建完serlet的之后,会创建过滤器链。并把当前servlet传递进去。

在dofilter中真正执行servlet的方法,而且,传递方法的时候分别调用了,request.getRequest(),response.getResponse()。这两个方法就是得到对应的门面模式的那个
RequestFacade,ResponseFacade,所以在servlet中得到request,response都是这个类对象。


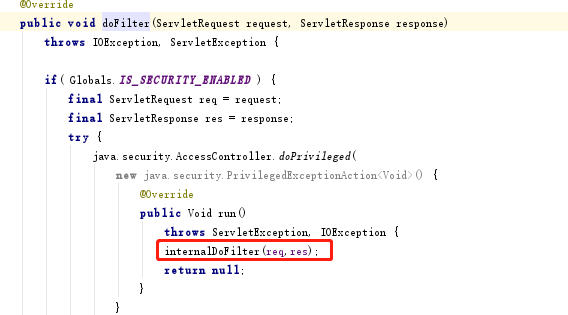
在这个内部方法中调用servlet的方法。
上面的流程可以简单用下面的图表示:
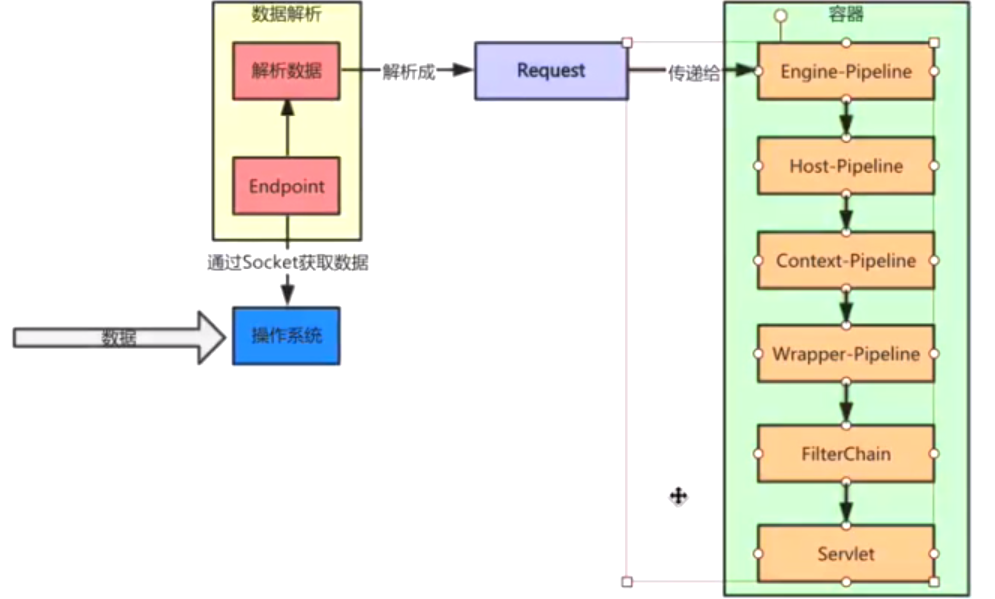
其实tomcat 就是处理请求和响应的,那么我们上面看到的request到底怎么生成的呢?
请求----->tomcat服务器:
首先要经过tcp协议(是由操作系统实现的)传输数据到服务器的操作系统。 Socket通信也是调用操作系统内核暴露出来的函数。
操作系统接收到的数据也就是tcp传输过来的都是字节数据,服务器通过Http协议(只关注数据格式进行解析) 在应用层解析数据成request。tomcat从Socket中取数据,具体获取数据的方式就IO模型有关了,tomcat中有BIO,NIO。
在tomcat中这个应用的层协议是在连接器 Connector 中配置,在server.xml中会有这个配置:
<!---protocol 属性会在构造Connector 的时候判断这个字符串内容 可以有HTTP/1.1 , AJP/1.3两种协议,在tomcat中有对应的协议处理器 如果上面都不是 需要传入自定义的协议处理器的全类名 --> <Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" />
在tomcat7中默认还是BIO的模型:

在tomcat8中已经变成NIO模型了

在tomcat8及以上的版本中,默认已经使用Nio模型了,bio在上面的构造过程中已经看不到了,但是看到有一个apr 的判断。其实在tomcat有bio,nio,apr三种的IO模型。
关于这三种模型的介绍: https://www.cnblogs.com/krock/p/14849189.html
用的最多的就是Http协议,从tomcat7中源码去看:org.apache.coyote.http11.Http11Protocol
public Http11Protocol() { // 处理BIO的一个组件 endpoint = new JIoEndpoint(); cHandler = new Http11ConnectionHandler(this); ((JIoEndpoint) endpoint).setHandler(cHandler); setSoLinger(Constants.DEFAULT_CONNECTION_LINGER); setSoTimeout(Constants.DEFAULT_CONNECTION_TIMEOUT); setTcpNoDelay(Constants.DEFAULT_TCP_NO_DELAY); }
主要是通过上面的JIoEndpoint 组件来处理数据解析封装。
 它的父类有三个子类,对应三种IO模型的处理。
它的父类有三个子类,对应三种IO模型的处理。
上面流程图中的EndPoinde就是处理IO的阶段,不同的IO模型对应不同的处理方式。
我先看BIO模型的JIoEndpoint

胡萝卜 马蹄五个 青椒红椒(尖椒 )
里面有一个Acceptor的内部类,它是一个实现了Runnable的类,可以作为线程启动。
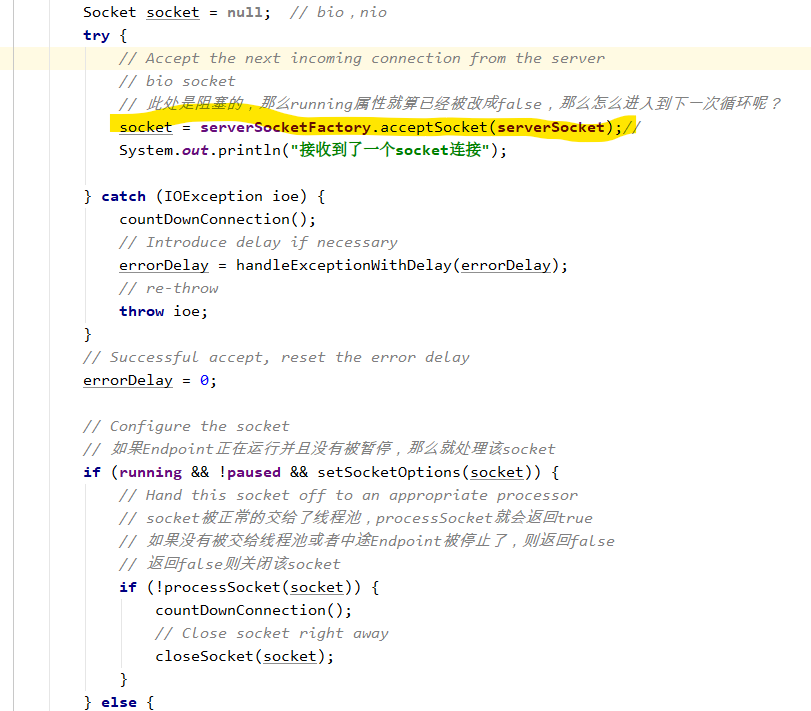
在 processSocket中处理到来的socket连接
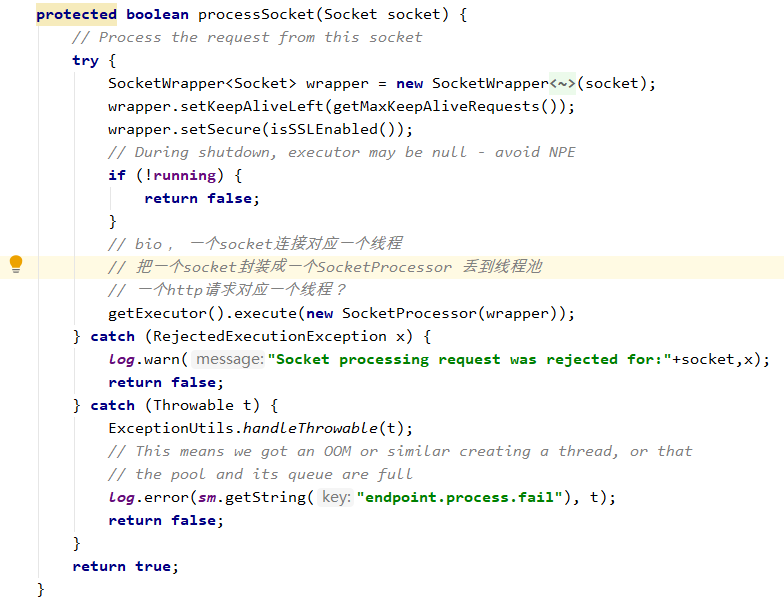
所以处理的逻辑都在SocketProcessor中了。这个也是JIoEndpoint的内部类。

AbstractProtocol#process

AbstractHttp11Processor#process
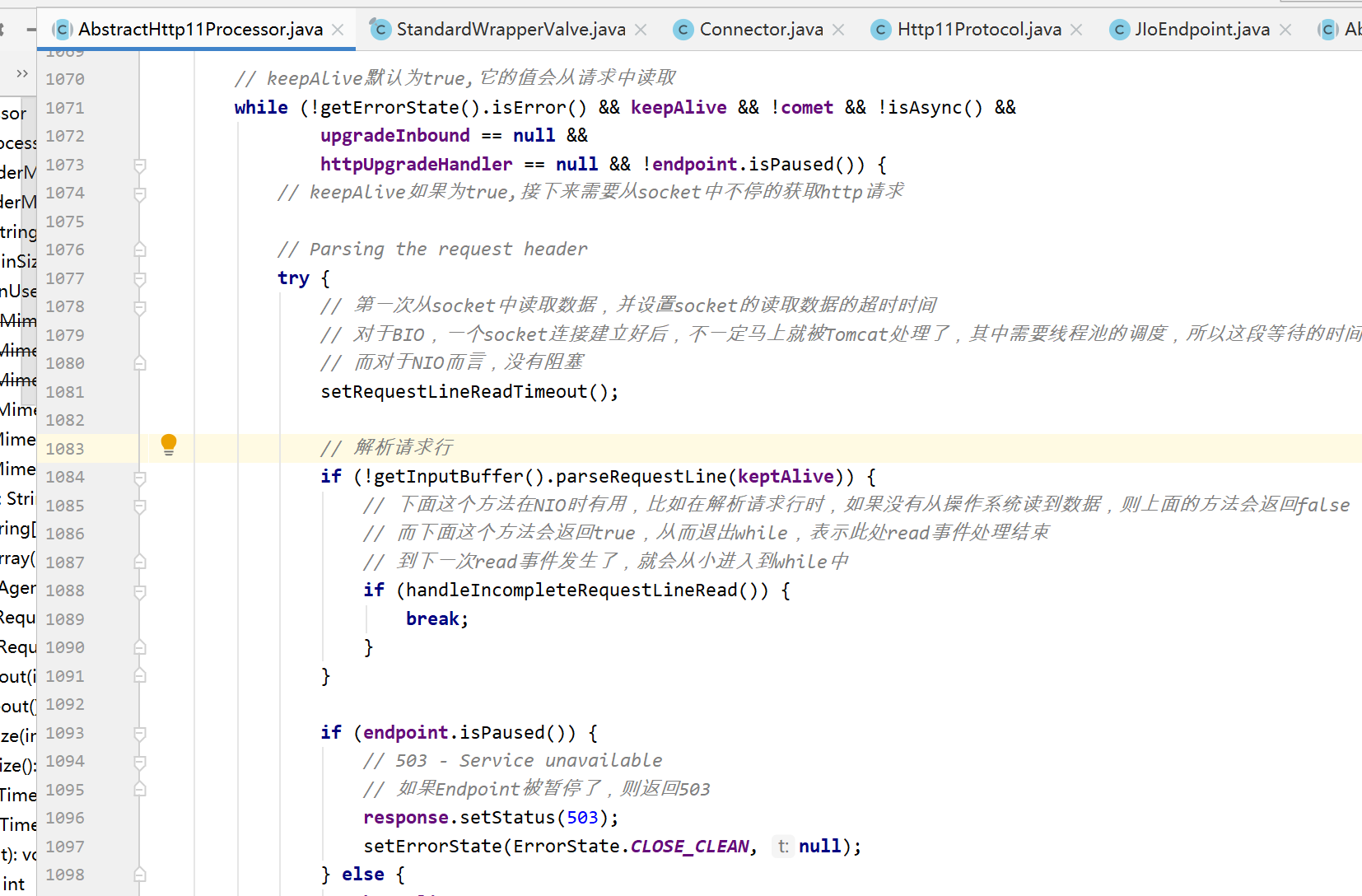
解析请求行也是和IO模型有关的:
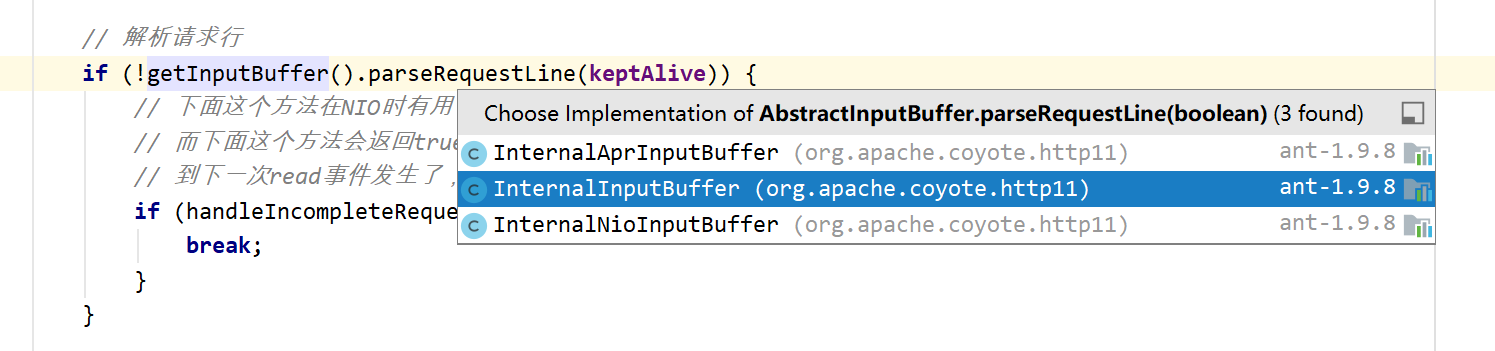
BIO用的是 InternalInputBuffer。后面分析具体的解析流程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号