LinkedList和CopyOnWriteArrayList的知识整理
LinkedList
1:LinkedList中te实现的接口和ArrayList相比有一个特殊的接口:Deque是一个双端队列,所以LinkList可以作为队列(FIFO)也可以作为栈(LIFO)使用。

java中队列的实现就是LinkedList: 我们之所以说LinkedList 为双端链表,是因为他实现了Deque 接口;我们知道,队列是先进先出的,添加元素只能从队尾添加,删除元素只能从队头删除,Queue中的方法就体现了这种特性。 支持队列的一些操作,我们来看一下有哪些方法实现:
- pop()是栈结构的实现类的方法,返回的是栈顶元素,并且将栈顶元素删除
- poll()是队列的数据结构,获取对头元素并且删除队头元素
- push()是栈结构的实现类的方法,把元素压入到栈中
- peek()获取队头元素 ,但是不删除队列的头元素
- offer()添加队尾元素
可以看到Deque 中提供的方法主要有上述的几个方法,接下来我们来看看在LinkedList 中是如何实现这些方法的。


2:向指定位置插入数据时候会先得到指定位置的前一个元素,这时候会用到“二分”的查找,效率比直接查找高一些。
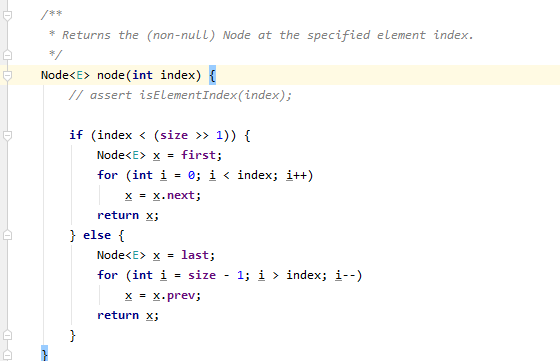
3:迭代器,LinkList中的迭代器比ArrayList中特殊一些。
1):支持向前遍历也支持向后遍历。
2): 可以指定迭代开始的位置,不同从第一个元素开始迭代
3)迭代过程中可以修改元素,甚至可以添加元素删除元素。
CopyOnWriteArrayList
我们都知道ArrayList虽然是很方便的集合,但是它不是线程安全的,为了提供线程安全的集合,在jdk中提供了 Collections.synchronizedxxx
可以把线程不安全的集合转成线程安全的集合,但是这种得到的集合用起来和Vector差不了多少,因为它转换之后的集合把对元素操作的方法都加了锁。

对于线程安全的集合还有一个:CopyOnWriteArrayList里处理写操作(包括add、remove、set等)是先将原始的数据通过JDK1.6的Arrays.copyof()来生成一份新的数组,然后在新的数据对象上进行写,写完后再将原来的引用指向到当前这个数据对象,这样保证了每次写都是在新的对象上(因为要保证写的一致性,这里要对各种写操作要加一把锁,JDK1.6在这里用了重入锁),然后读的时候就是在引用的当前对象上进行读(包括get,iterator等),不存在加锁和阻塞,针对iterator使用了一个叫COWIterator的阉割版迭代器,因为不支持写操作,当获取CopyOnWriteArrayList的迭代器时,是将迭代器里的数据引用指向当前引用指向的数据对象,无论未来发生什么写操作,都不会再更改迭代器里的数据对象引用,所以迭代器也很安全。
例如下面的add方法:
public boolean add(E e) { final ReentrantLock lock = this.lock; lock.lock();//先加锁 try { Object[] elements = getArray(); int len = elements.length; Object[] newElements = Arrays.copyOf(elements, len + 1);//复制到新数组中,长度+1 newElements[len] = e;//在新数组中添加元素 setArray(newElements);//将新数组设置给array return true; } finally { lock.unlock(); } }
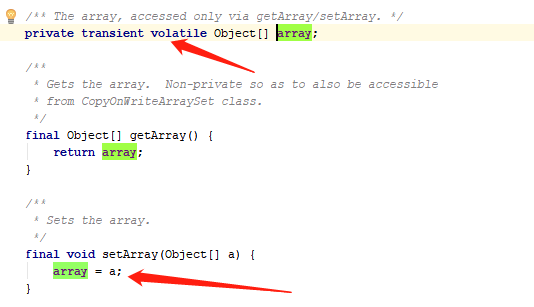
0:先加锁
1: 先获取当前集合数组,数组是用volatile修饰的。
2:通过Arrays.copyOf得到一个新的数组。
3:在新的数组上增加元素。newElements[len]=e
4: 把array引用指向新的数组。setArray(newElements)
指定位置添加元素:
public void add(int index, E element) { final ReentrantLock lock = this.lock; // 加锁 lock.lock(); try { // 获取旧数组 Object[] elements = getArray(); int len = elements.length; // 检查是否越界, 可以等于len if (index > len || index < 0) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+len); Object[] newElements; int numMoved = len - index; if (numMoved == 0) // 如果插入的位置是最后一位 // 那么拷贝一个n+1的数组, 其前n个元素与旧数组一致 newElements = Arrays.copyOf(elements, len + 1); else { // 如果插入的位置不是最后一位 // 那么新建一个n+1的数组 newElements = new Object[len + 1]; // 拷贝旧数组前index的元素到新数组中 System.arraycopy(elements, 0, newElements, 0, index); // 将index及其之后的元素往后挪一位拷贝到新数组中 // 这样正好index位置是空出来的 System.arraycopy(elements, index, newElements, index + 1, numMoved); } // 将元素放置在index处 newElements[index] = element; setArray(newElements); } finally { // 释放锁 lock.unlock(); } }
//添加一个不存在于集合中的元素。 public boolean addIfAbsent(E e) { // 获取元素数组 Object[] snapshot = getArray(); //已存在返回false,否则添加 return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false : addIfAbsent(e, snapshot); } private boolean addIfAbsent(E e, Object[] snapshot) { final ReentrantLock lock = this.lock; lock.lock(); try { // 重新获取旧数组 Object[] current = getArray(); int len = current.length; // 如果快照与刚获取的数组不一致,说明有修改,减少indexOf需要遍历的元素个数 if (snapshot != current) { // 重新检查添加元素e是否在current里,减少indexOf的对比次数 int common = Math.min(snapshot.length, len); for (int i = 0; i < common; i++) //判断是否有其他线程修改了数组,snapshot中肯定不会存在e、前面已经进行过indexOf判断, //所以current[i] != snapshot[i]如果返回false(不考虑并发下是相等的),则eq判断不用进行 //for循环完毕都没有返回false的话,indexOf判断只需要判断current和snapshot的差集 if (current[i] != snapshot[i] && eq(e, current[i])) return false; if (indexOf(e, current, common, len) >= 0) return false; } // 拷贝一份n+1的数组 Object[] newElements = Arrays.copyOf(current, len + 1); // 将元素放在最后一位 newElements[len] = e; setArray(newElements); return true; } finally { // 释放锁 lock.unlock(); } }
获取指定位置的元素:
public E get(int index) { return get(getArray(), index); } final Object[] getArray() { return array; } //私有方法 private E get(Object[] a, int index) { return (E) a[index]; }
这个方法是线程不安全的,因为这个分成了两步,分别是获取数组和获取元素,而且中间过程没有加锁。假设当前线程在获取数组(执行getArray())后,其他线程修改了这个CopyOnWriteArrayList,那么它里面的元素就会改变,但此时当前线程返回的仍然是旧的数组,所以返回的元素就不是最新的了,这就是写时复制策略产生的弱一致性问题。
使用场景及优点
并发容器用于读多写少的并发场景。比如白名单,黑名单等场景。
读操作可能会远远多于写操作的场景。比如,有些系统级别的信息,往往只需要加载或者修改很少的次数,但是会被系统内所有模块频繁的访问。对于这种场景,我们最希望看到的就是读操作可以尽可能的快,而写即使慢一些也没关系。
CopyOnWriteArrayList 的思想比读写锁的思想更进一步。为了将读取的性能发挥到极致,CopyOnWriteArrayList 读取是完全不用加锁的,更厉害的是,写入也不会阻塞读取操作,也就是说你可以在写入的同时进行读取,只有写入和写入之间需要进行同步,也就是不允许多个写入同时发生,但是在写入发生时允许读取同时发生。这样一来,读操作的性能就会大幅度提升。
读写分离
缺点
内存占用,弱一致性
CopyOnWriteArrayList中写操作需要大面积复制数组,所以性能肯定很差,但是读操作因为操作的对象和写操作不是同一个对象,读之间也不需要加锁,读和写之间的同步处理只是在写完后通过一个简单的“=”将引用指向新的数组对象上来,这个几乎不需要时间,这样读操作就很快很安全,适合在多线程里使用,绝对不会发生ConcurrentModificationException,所以最后得出结论:CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存,黑白名单。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号