从ArrayList源码中学到的东西
一:实现了的接口
1:RandomAccess
支持随机访问(基于下标),为了能够更好地判断集合是ArrayList还是LinkedList,从而能够更好选择更优的遍历方式,提高性能!
2:Cloneable
支持拷贝:实现Cloneable接口,重写clone方法、方法内容默认调用父类的clone方法。
3:Serializable
序列化:将对象状态转换为可保持或传输的格式的过程。与序列化相对的是反序列化,它将流转换为对象。这两个过程结合起来,可以轻松地存储和传输数据,在Java中的这个Serializable接口其实是给jvm看的,通知jvm,我不对这个类做序列化了,你(jvm)帮我序列化就好了。如果我们没有自己声明一个serialVersionUID变量,接口会默认生成一个serialVersionUID,默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常(每次序列化都会重新计算该值)
4:AbstractList
继承了AbstractList ,说明它是一个列表,拥有相应的增,删,查,改等功能。
5:list
为什么继承了 AbstractList 还需要 实现List 接口?
1、在StackOverFlow 中:传送门 得票最高的答案的回答者说他问了当初写这段代码的 Josh Bloch,得知这就是一个写法错误。 I’ve asked Josh Bloch, and he informs me that it was a mistake. He used to think, long ago, that there was some value in it, but he since “saw the light”. Clearly JDK maintainers haven’t considered this to be worth backing out later.
二:为什么ArrayList访问速度这么快
我们都知道,ArrayList是基于数组来实现的,数组是一块连续分配的内存,而且数组中存储的数据类型是确定的,也就是说只要知道数据的首地址还有数据所在的索引i就可以根据首地址+i*数据类型大小
定位到数据的位置,这个操作的时间复杂度是o(1),所以速度很快。
三:为什么会有三个Object[]
虽然我们知道存储元素的是数组但是在ArrayList源码里可以看到有三个Object[],

前两个都是静态final修饰的,也就说所有ArrayList对象都可以使用,这是为了节省内存空间所考虑的,因为大部分时候创建ArrayList的时候并没有数据添加,这时候就用上面静态的数组进行初始化,省的每个ArrayList都创建新的Object[],
当集合真正添加数据的时候才会使用第三个数组来存放数据。
那前两个有什么区别呢?是和创建集合时的构造函数有关:传了初始容量和没有初始容量。
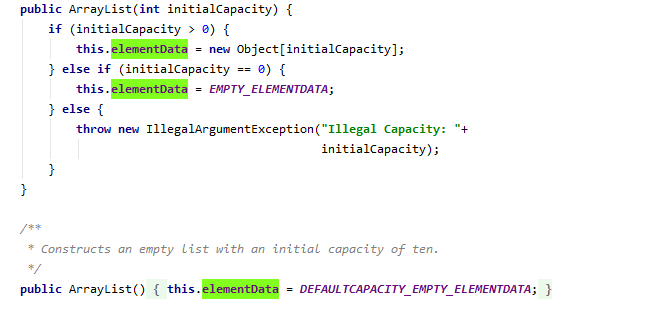
四:集合扩容
每次扩容之前都会检查容量是否够用,向数组末尾添加元素。


每次对集合长度发生改变的时候都会把操作数加一,是为了fast-fail。
注意这里的elementData.length得到是数组的长度,并不是集合中元素的个数,集合中元素的个数是size.
数组没有满的时候是{元素1,元素2,null,null}这样的。
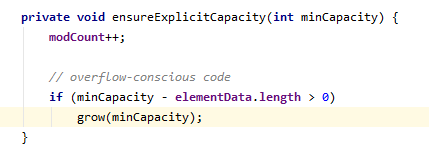
如果当前数组小了就进行扩容。

扩容因子:1.5,即扩大1.5倍,oldCapacity>>1相当小除以2得到的结果。
五:向集合中指定位置添加元素
我们知道向集合中添加元素需要移动数组中的元素,在ArrayList中是使用了一个本地方法进行数组移动的。
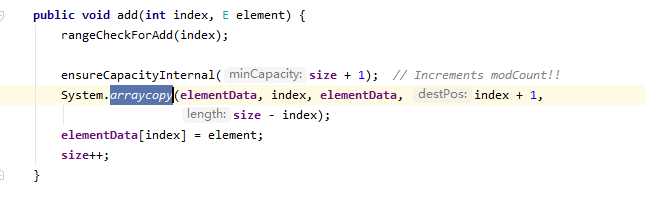
这个方法我们可以在项目copy数组的时候使用,关于它的详细信息可以参见函数说明很容易理解。删除指定位置元素和设计到移动数组元素,也用到这个方法了。
六:subList方法使用的坑
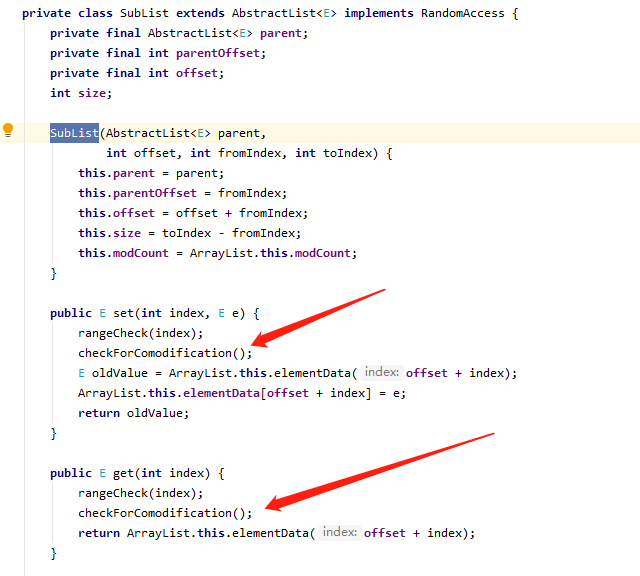
ArrayList中有一个subList的方法可以返回当前集合的一个部分集合,但是返回的集合其实是个内部类,而且这个内部类使用的时候操作还是当前集合,看到创建SubList实例的时候把modCount也传递进去了,
而且get,set方法使用的都是ArrayList.this.elementData,此外在get,set方法操作的时候都会检查是否有并发操作,也就是说我们对原来集合长度的改变会导致subList方法返回的集合在操作get,set的时候报错。
checkForComodification();


七:Arrays.asList不知道的知识点
我们知道 Arrays.asList返回的集合其实是个Arrays内部的一个ArrayList集合:
只提供了一些简单的方法,因此我们不能使用这个返回结果做过多的事情。
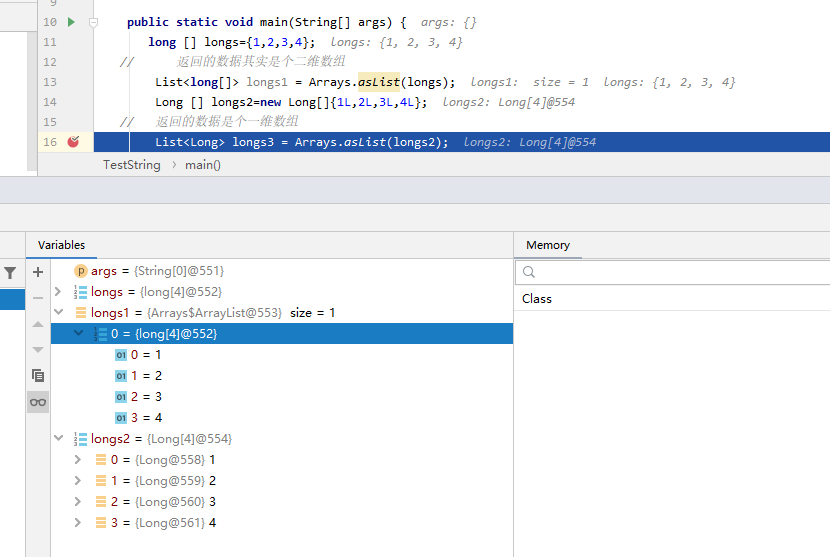
而且我们从下面的例子可以看出,如果我们传入数组元素是基本数据类型和引用数据类型返回的结果也是不一样!!!
这是因为asList方法参数是个泛型, 我们知道基本数据类型是不支持泛型的,数组也没办法向下转型,所以我们传递基本数据类型数组的时候,jvm直接把我们的传递进去的数组当成一个整体元素进行
我们知道基本数据类型是不支持泛型的,数组也没办法向下转型,所以我们传递基本数据类型数组的时候,jvm直接把我们的传递进去的数组当成一个整体元素进行
存储了,返回的其实是个二维数组,第一位元素就是我们传递进去的数组,从自动生成的变量就可以看出不同了。但是我们传递引用数据类型的时候,jvm是支持泛型,得到就是我们熟悉那种集合结构了。
八:不可变集合
可以使用下面的方式把集合变成只读的集合,就是只提供get方法,但是集合的内容还是会受到原来集合的影响,因为只是对其的引用,但是这种方式可以把主要的信息封装成集合对外暴露不可变集合。
Collections.unmodifiableList
九:迭代器
注意的点,迭代器遍历过程中不能使用集合中的remove方法,会发生ConcurrentModificationException异常,只能使用迭代器中的remove方法
remove 方法的弊端。
1、只能进行remove操作,add、clear 等 Itr 中没有。
2、调用 remove 之前必须先调用 next。因为 remove 开始就对 lastRet 做了校验。而 lastRet 初始化时为 -1。
3、next 之后只可以调用一次 remove。因为 remove 会将 lastRet 重新初始化为 -1
十:Vector
基本不再使用,很多方法加了锁,但是加锁不一定九支持高并发了,虽然加锁可以让某个方法支持高并发,但是管不住多线程对同一个对象的多个方法进行操作,要想安全应该加全局锁。比如下面的这个代码:
单独执行 testVector(); 方法是没有问题,但是多线程testThread();同时执行的时候就会出现下标越界的问题。
private static Vector<Integer> vector=new Vector<>(); public static void main(String[] args) { testVector(); testThread(); } public static void testVector(){ for (int i = 0; i <10 ; i++) { vector.add(i); } for (int i = 0; i <vector.size() ; i++) { System.out.println(vector.get(i)); vector.remove(i); i--; } } public static void testThread(){ Thread thread1=new Thread(new Runnable() { @Override public void run() { Thread.yield(); testVector(); } }); Thread thread2=new Thread(new Runnable() { @Override public void run() { Thread.yield(); testVector(); } }); thread1.start(); thread2.start(); }

虽然我们单独执行Vector的 add,remove方法,方法上加 synchronized锁的是同一个对象,但是在testThread()方法中使用了两个加锁的方法add,remove,这种叫复合操作,这种复合操作时没办法保证原子性的,
因为add方法一执行完锁就释放了,所以对于这种复合操作需要程序自己加锁来保证原子性比如加在testThread()方法上可以保证原子性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号