JVM(七)字符串详解
常量池:
我们前面也一直说常量池有三种:
1:class文件中的常量池,前面我们解析class文件的时候解析的就是,这是静态常量池。在硬盘上。
2:运行时常量池。可以通过HSDB查看,是InstanceKlass的一个属性:ConstantPool *_constants。在方法区或者说在元空间中(JDK1.8+)
可以通过HSDB查看,HSDB的使用可以看JVM第一篇中的介绍。
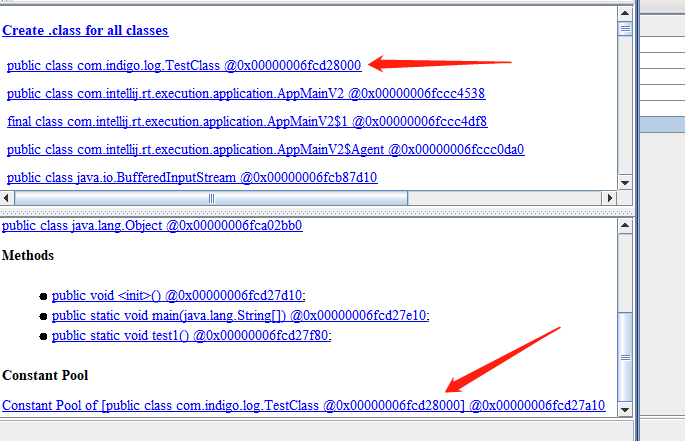

3:字符串常量池。底层是String Pool--StringTable--HashTable。在堆区。
注意:并不是所有的字符串都会在字符串常量池里。
String是怎么存储的?
在java中我们的String对象存储的字符串都是在其内部的一个char数组上的。

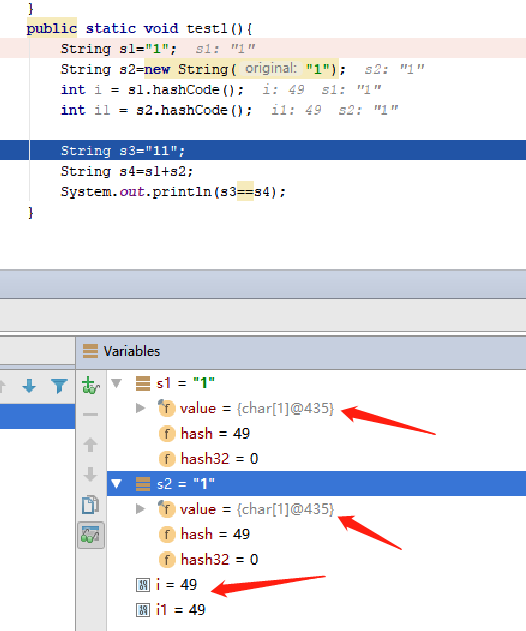
我们看到两个不同的变量,以不同的创建方式创建,字符串一样,但是字符串变量里的value数组属性地址竟然是一样的? 是不是很神奇。这就牵涉到JVM里面
是怎么存储字符串的问题了。还有就是两个变量的hashcode值也是一样的,这是因为String重写了hashcode方法,hash值只和字符串的内容也就是value有关,所以是一样的。
JVM中的String是怎么存储的呢?
在JVM中,使用StringTable来存储String的当然也有些不是通过StringTable存储的,这个后面说明。StringTable继承HashTable,也就是字符串在JVM中是key-value形式存储的。数据结构也就是数组+链表。
在openJDK中的symbolTable.cpp中如下方法:
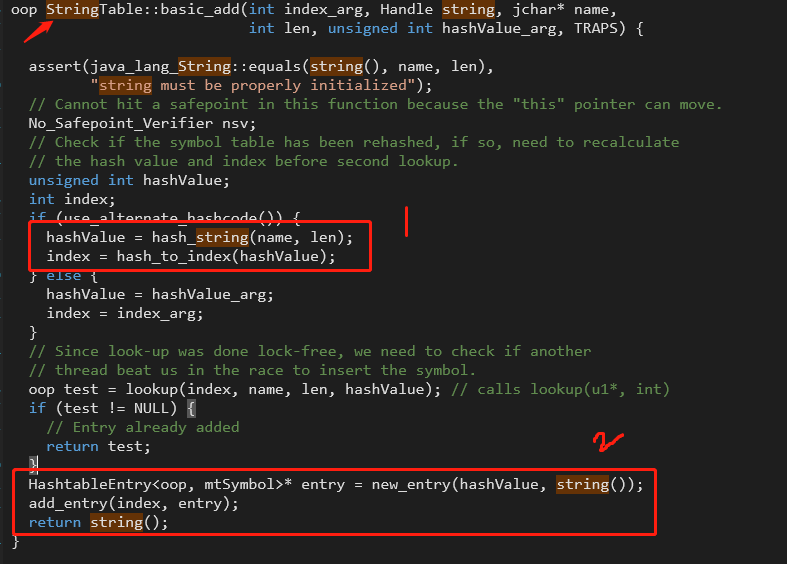
key:
是通过1中的方式生成的。1)根据字符串以及字符串的长度计算出hashvalue.2)根据hashvalue计算出index,这个index就是key。也就是数组的下标,在这里称为bucket(桶)默认桶的数量为60013个。
可以通过-XX:StringTableSize=2000参数来调整桶的大小。
value:
key计算出了bucket的位置,value的值就是2中生成的 HashtableEntry<oop, mtSymbol>* entry = new_entry(hashValue, string());
它是将Java中String类的实例instanceOopDesc封装成了HashtableEntry,再存储起来的。
这里补充下,在第一篇JVM中已经提到了oop-klass体系。这里再说明下:
Oop: java中对象在JVM中的存在形式。klass是java中的类在JVM中存在的形式。

通过idea我们可以看到在创建String过程中都创建了些什么内容
实例
我们从idea中接着看上面的例子。看下创建字符串过程中到底创建了那些内容。
public static void main(String[] args) { test1(); } public static void test1(){ String s1="1"; String s3="1"; String s2=new String("1"); System.out.println(s1==s3); System.out.println(s1==s2); }
以Debug的方式调试,在控制台最右上角有个Memory View,可以实时看到每一步创建了那些对象,创建了几个。
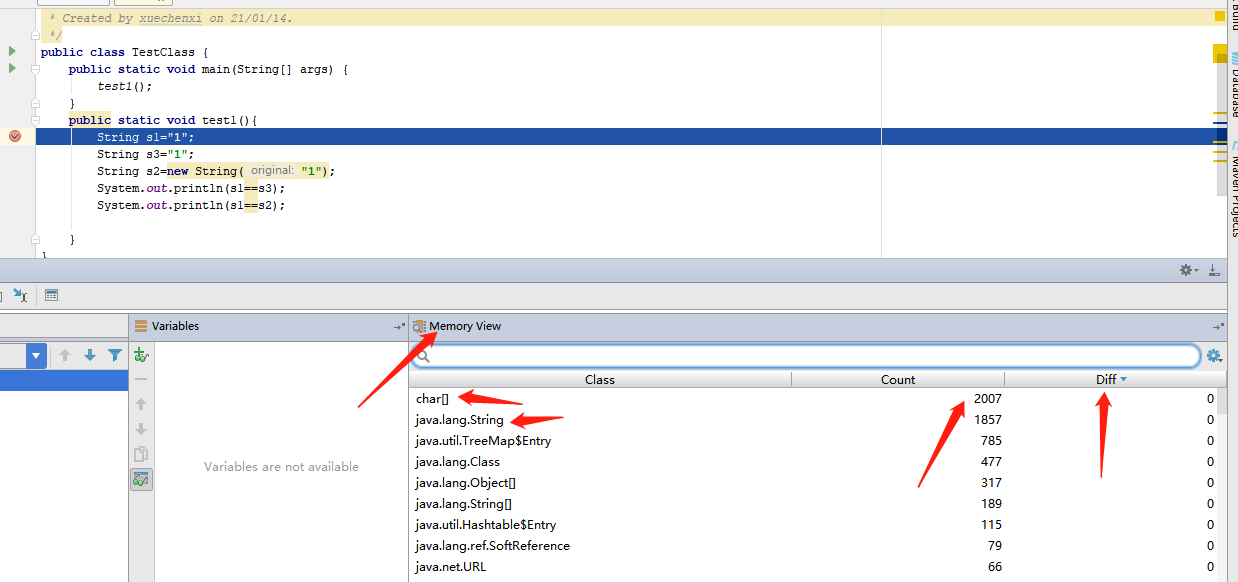
第一行执行完:我们看到char[] ,String各新增了一个。
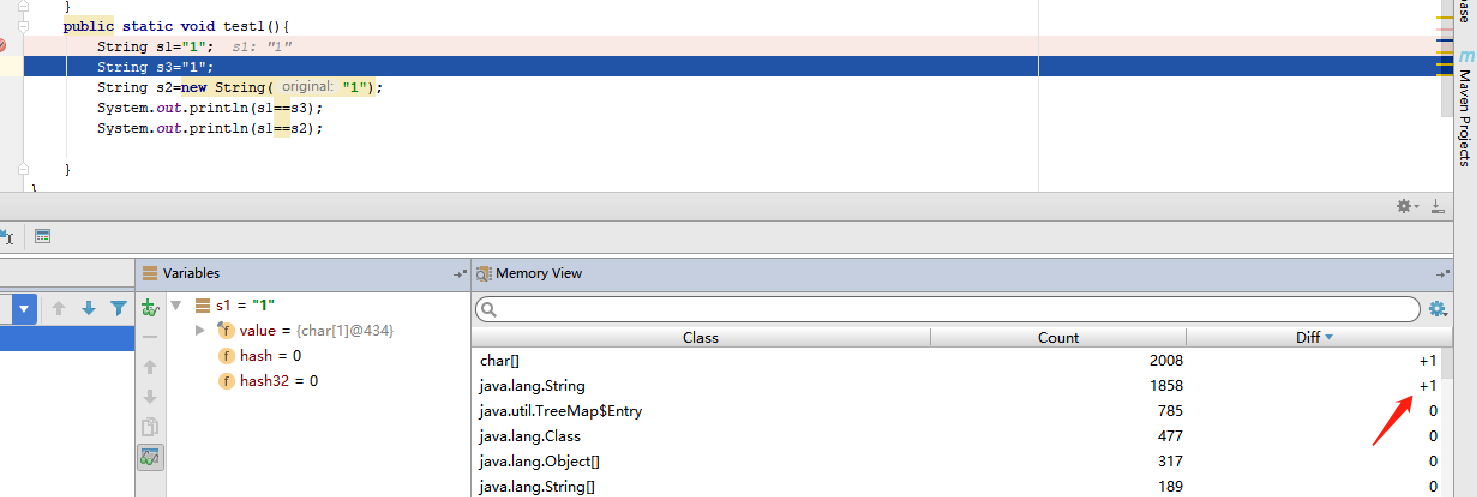
第二行执行完:char[],String一个都没新增,很神奇吧,别慌,执行完。
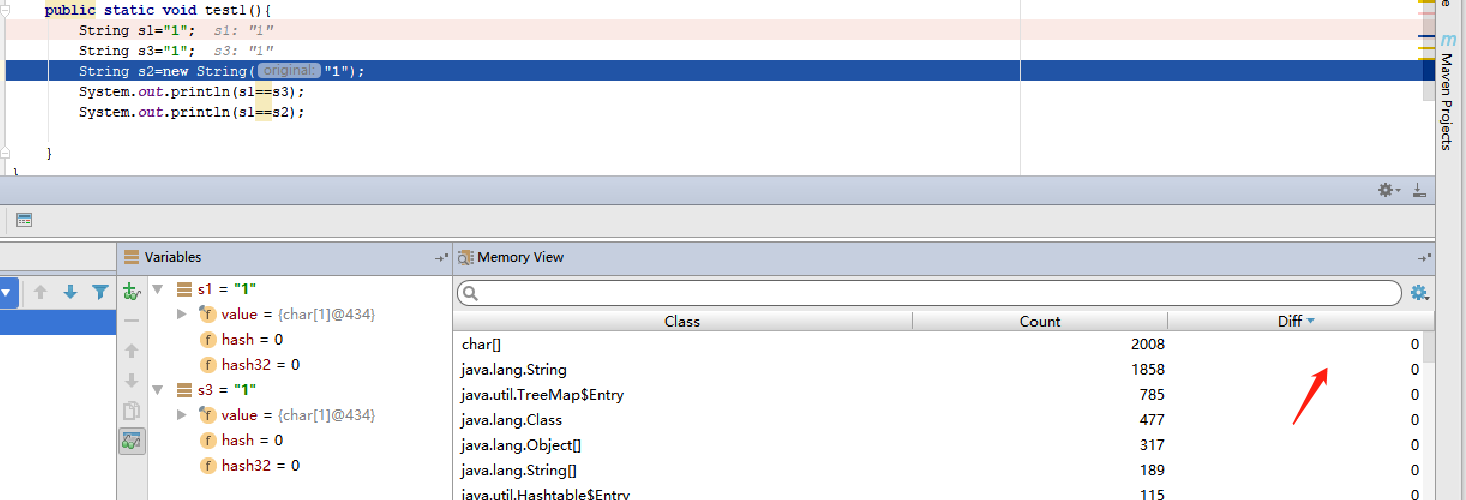
第三行执行完:只新增了一个String。
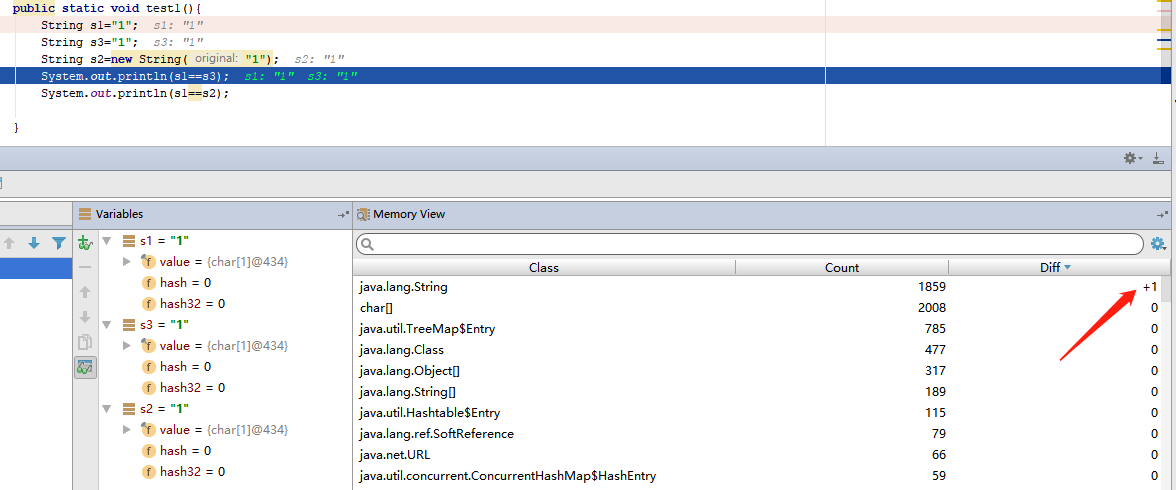
两个比较结果:s1和s3的地址是一样的。s2是不同的地址。

为什么会出现上面看到的结果呢?关键看下图:
1)如果是一个char[]数组类型数据 ,它的对象在JVM中是typeArrayOopDesc形式的。
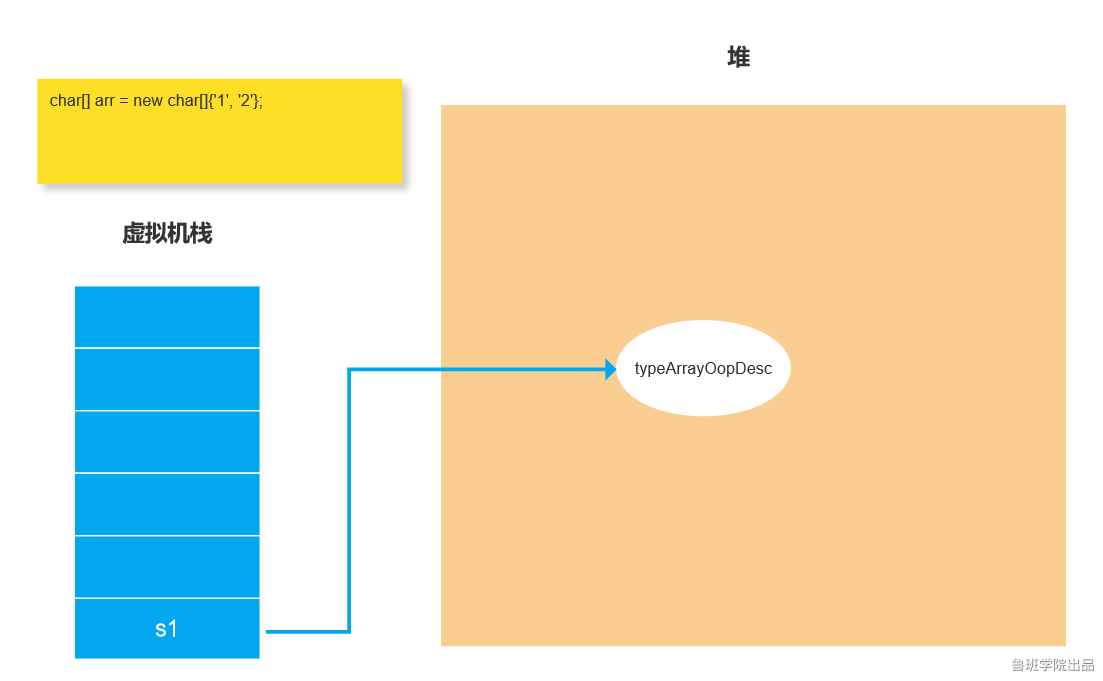
2:直接双引号创建一个字符串:按照上面说的,字面字符串会在堆里有一个String对象,String对象里有一个char[]数组对象,把String对象对应的instanceOopDesc封装成HashTableEntry然后把HashTableEntry放入常量池中。s1只是引用这个String对象。
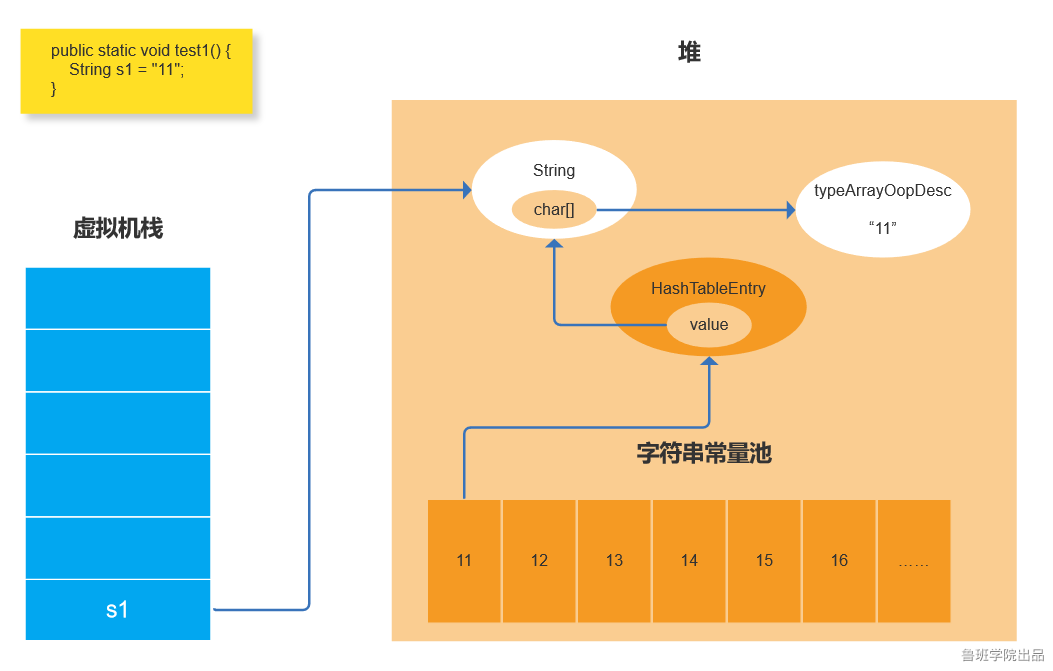
3:两个双引号:当s2创建“11”字面字符串时,会首先判断常量池是否有这个字符串如果有的话会直接返回这个字符串的instanceOopDesc。所以s1,s2指向的是同一个块地址。
如果没有的话会创建一个像2中的那样。
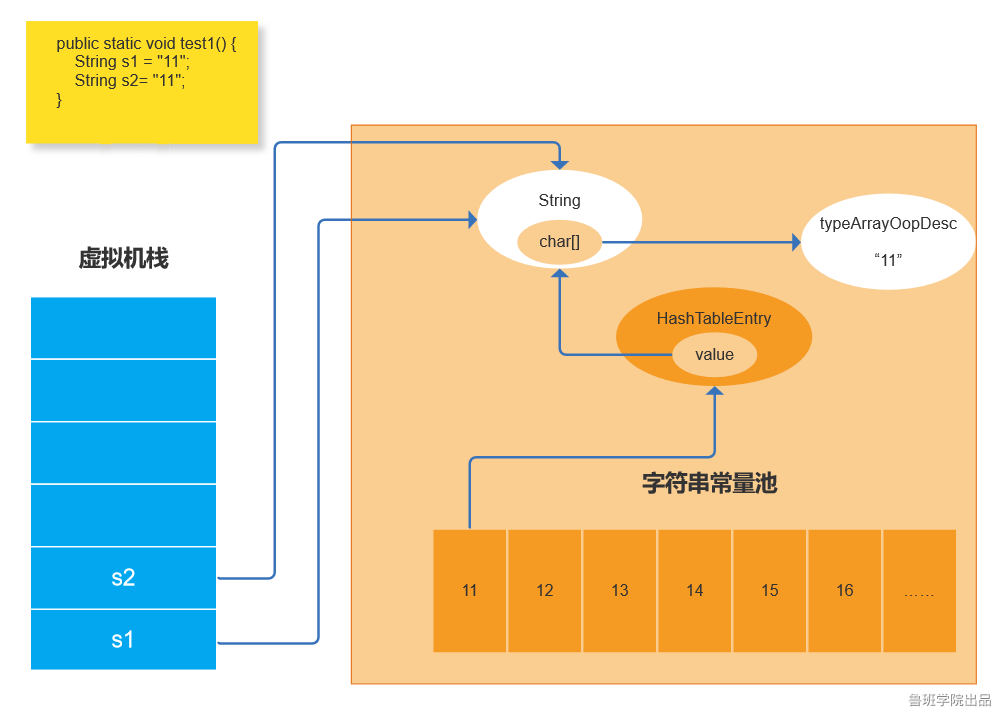
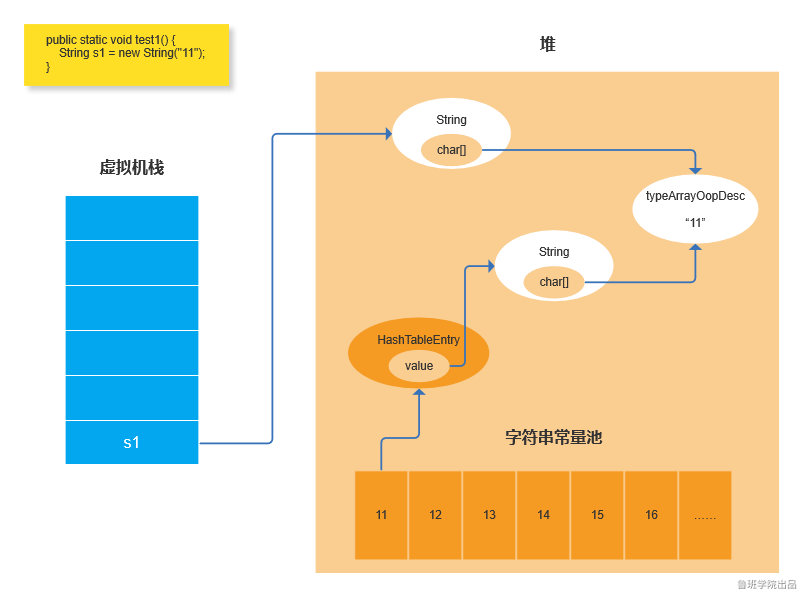
4:通过 new String 创建字符串:new 操作会在堆里创建一个String对象,这个String对象的char数组还是指向typeArrayOopDesc,如果字符串常量池中已经存在了当前字符串,
还是会指向已经存在的地址。
因此可以看到上面举得例子,s1,s2,s3变量中的char数组的内存地址都是一样的!!
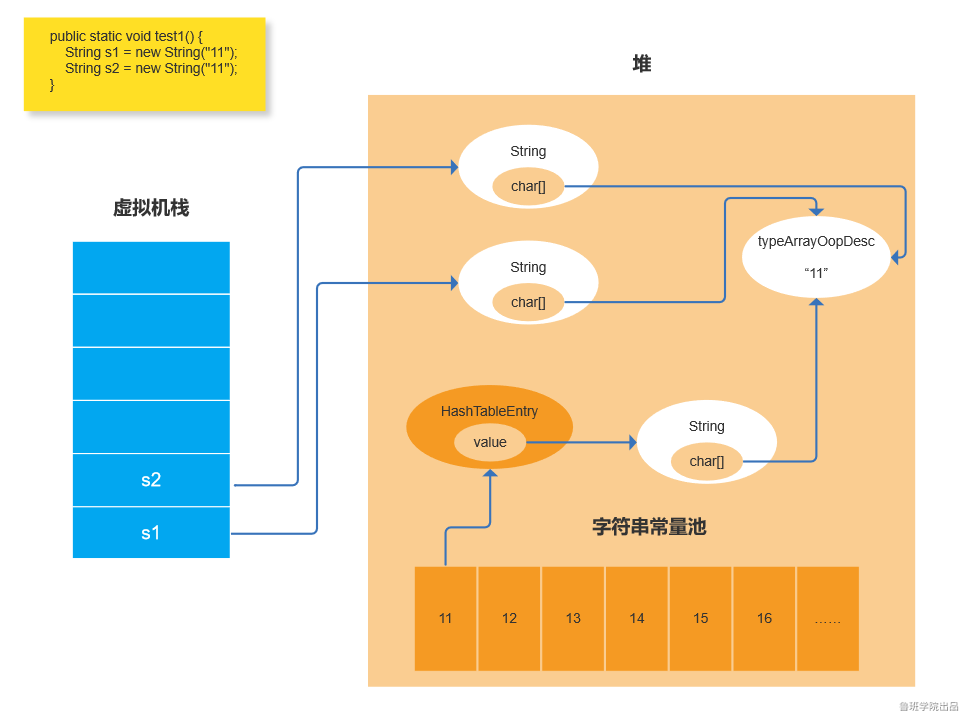
5:创建两个new String方式的字符串,常量池中还是只有一个,但是两个s1,s2地址是不一样的,但是其下的char数组还是会指向同一个typeArrayOopDesc。
字符串拼接
public static void test1(){ String s1="1"; String s2="2"; String s3=new String("3"); String s6="12"; String s7="13"; String s4=s1+s2; String s5=s1+s3; }
我们首先看下字符串拼接底层是怎样实现的。通过 javap -c TestString.class 可以查看字节码指令。或者直接通过idea查看.class文件
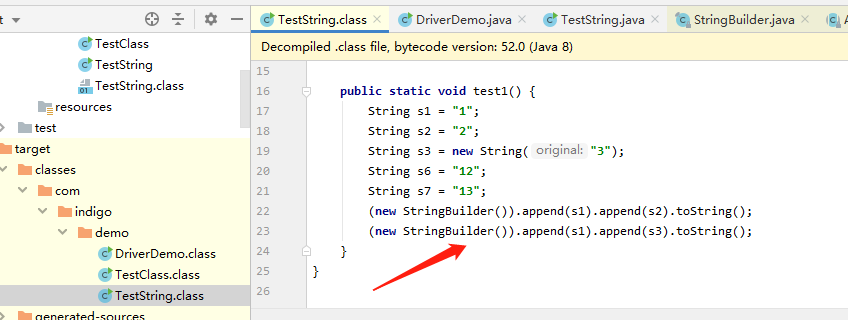
我们看到String s4=s1+s2; String s5=s1+s3; 底层都是通过StringBuilder#append来拼接之后再toString得到的。但是不仅仅只有这一点区别!
我们继续看StringBuilder#toString方法。发现是调用了 new String(value, 0, count); 的构造方法。
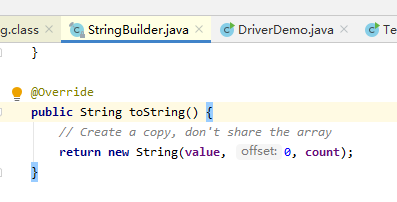
我们通过Debug看下,通过拼接得到的字符串有什么不一样的地方?
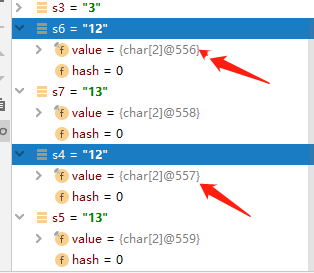
首先看下 String s6="12"; String s4=s1+s2; 的区别,s1+s2得到的字符串也是"12", 这里char数组地址竟然不一样了!!!
我们上面知道常量池中如果已经有了这个字符串,下面创建同样的字符串的时候都是从常量池中获取,char数组的地址都是一样的。这里竟然不一样了!
这就是拼接字符串的不同之处,拼接出来的字符串并没有从常量池中获取,创建出来的字符串也不会放入字符串常量池中,s6是常量池中的字符串,s4里面的char数组就是普通的堆里面的数组。s5拼接的字符串也是这样的。
我们这里把这个这个构造函数和常量字符串构建单独拉出来看下。
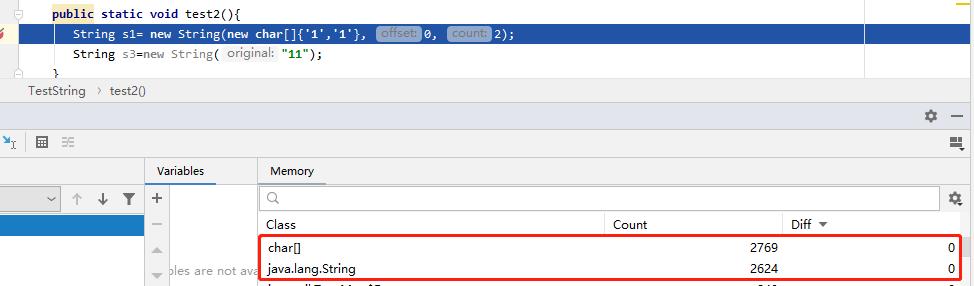
第一行执行完:String,char[] 各新增一个。
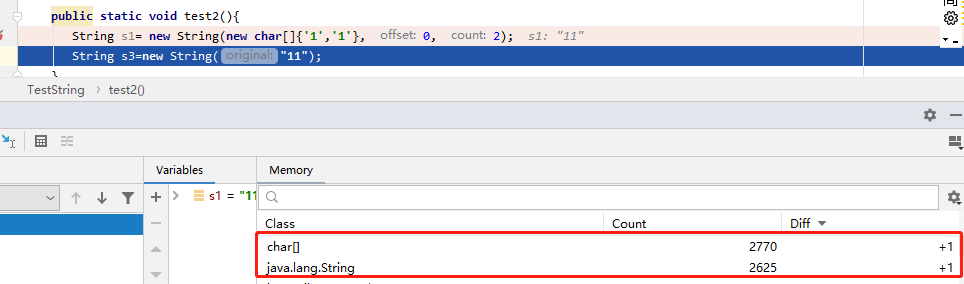
第二行执行完:新增了两个String,一个char[]数组 ,而且看到s1,s3字符串虽然一样的,但是char[] 却不再一样了。这也就是s1字符串并不在常量池中,s3会把字符串放入常量池中。
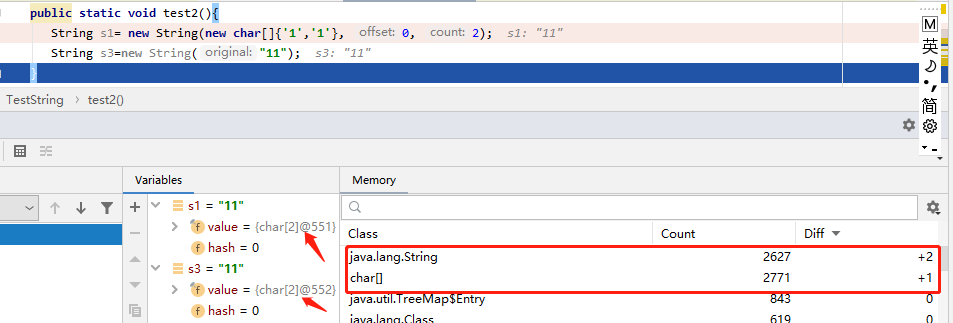
虽然String s=s1+s2这种拼接的字符串并不会放到字符串常量池中,但是我们可以调用String#intern方法把当前的字符串主动放入字符串常量池中。
我们还是以上面这个例子,加一行代码:
第一行执行完结果:
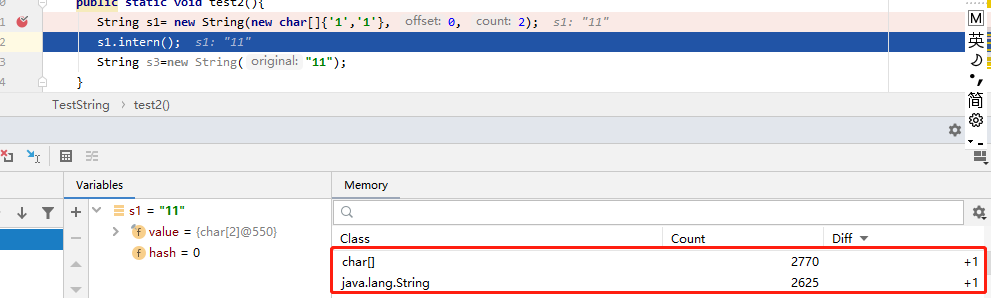
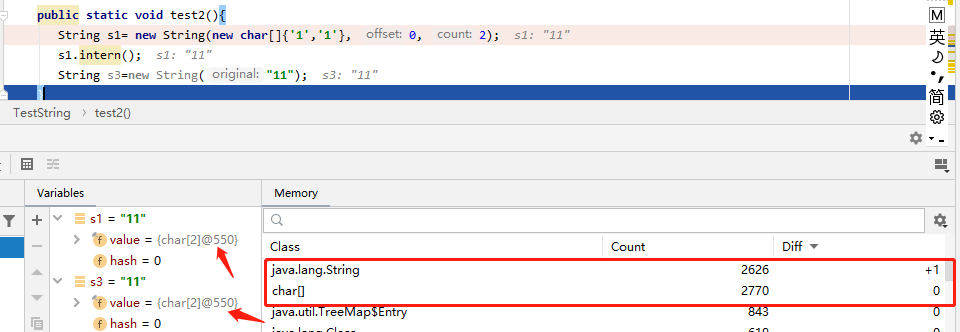
第二行执行完结果:没有什么明显的结果
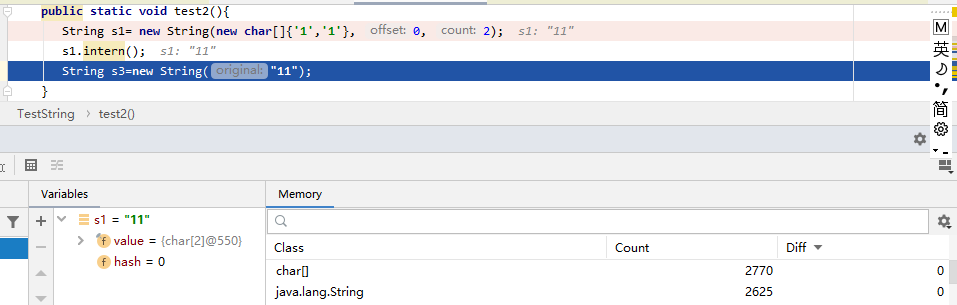
第三行执行完: 只新增了一个String对象,而且char[] 数组地址是一样的。这是因为s1.intern()方法,把s1的字符串放入常量池中了,s3创建的时候,只是在堆里再创建一个新的String对象就可以了,这个在上面的图解中也说明了。
还有一种特殊情况我们来看下,有final修饰符修饰的字符串之间的拼接情况:
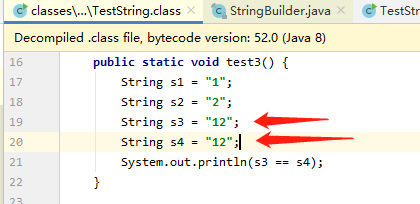
public static void test3(){ final String s1="1"; final String s2="2"; String s3=s1+s2; String s4="12"; System.out.println(s3==s4); }
因为s1,s2是final修饰的,在编译阶段就放入了字节码的常量池中,s3其实在编译阶段已经指向了常量池中的"12"了。
我们通过编译后的class也可以看到:所以比较肯定是true。
// 只会创建一个String 一个char[],编译的时候就优化成"帅帅" String s="帅"+"帅"; // 三个String,三个char数组对象, String s2 = "帅" + new String("真帅");

 浙公网安备 33010602011771号
浙公网安备 33010602011771号