AWK{shell三剑客awk,sed,grep}
AWK:
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告是,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
使用方法:awk '{pattern + action}' {filename}
尽管操作可能会很复杂,其中pattern 表示AWK 在数据中查找的内容,而action是在找到匹配内容是所执行的一系列命令。花括号({})不需要再程序中始终出现,但它们用于根据特定的模式对一系列指定进行分组。pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是再文件或者字符串中基于指定规则浏览和抽取信息后,才能进行其他文本操作。完整的awk脚本通常用格式化文本文件中的信息。通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
awk的变量:
ARGC 命令行参数个数
ARGV 命令行参数排列
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
FNR 浏览文件的记录数
FS 设置输入域分隔符,等价于命令行 -F选项
NF 浏览记录的域的个数
NR 已读的记录数
OFS 输出域分隔符
ORS 输出记录分隔符
RS 控制记录分隔符
$0 变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域.......以此类推。
$NF 是number finally,表示最后一列的信息,跟变量NF是有区别的,变量NF统计的是每行列的总数
awk输出:
搜索/etc/passwd有root关键字的所有行

搜索/etc/passwd有root关键字的所有行,并显示对应的shell

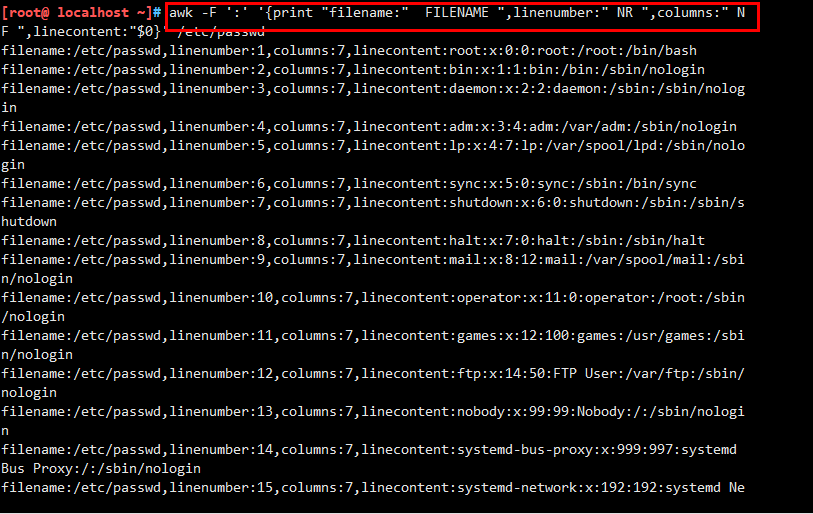
统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容:
使用printf替代print,可以让代码更加简洁,易读

打印/etc/passwd/的第二行信息

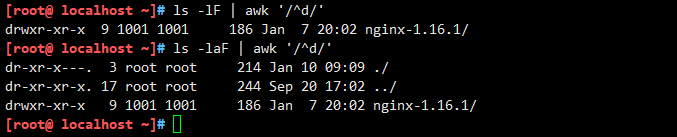
awk的过滤的使用方法
指定特定的分隔符,查询第一列

指定特定的分隔符,查询最后一列

指定特定分隔符,查询最前一列:

指定特定的分隔符,查询倒数第二列$(NF-1):
倒数第一行
awk '{print $(NF)}'
倒数第二行
awk '{print $(NF-1)}'
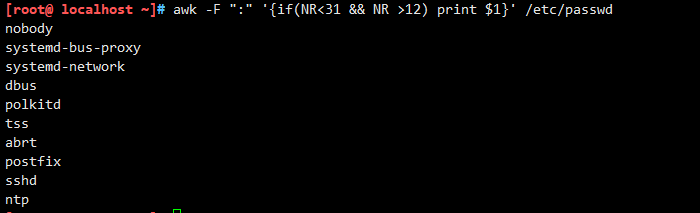
获取12到31行的第一列的信息
多分隔符的使用 这里以/为分隔符,多个分隔符利用[ ]让后往里面写分隔符:

添加了BEGIN和END(这里说的是以name,shell表示开始以hello来表示结束):

查看最近登录最多的IP信息

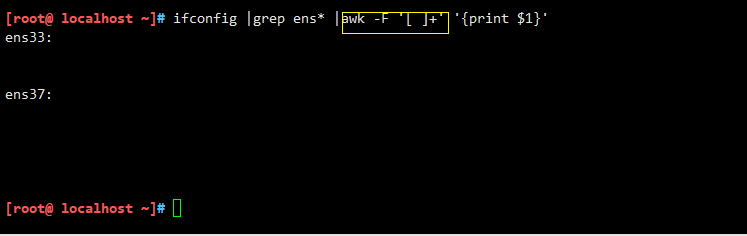
利用正则过滤多个空格
awk变量和赋值
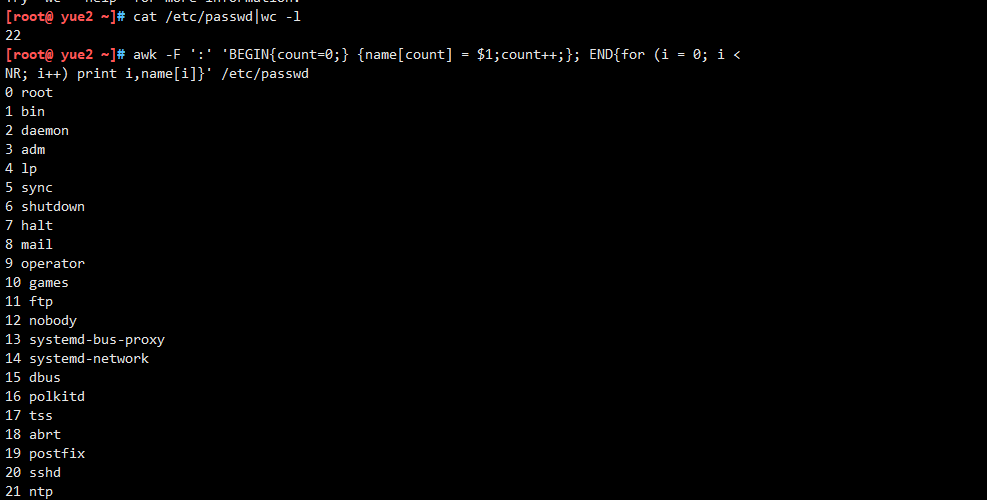
除了awk的内置变量,awk还可以自定义变量,awk中的循环语句同样借鉴借鉴玉c语言,支持while、do/while、for、break、continue,这些关键字的语义完全相同。统计某个文件夹下的大于100k文件的数量和总和
<strong>备注:<strong>count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}
可以有多个语句,以;号隔开
【因为awk会轮询统计,所以会显示整个过程】

显示最后

显示开头

统计显示/etc/passwd的账户


 浙公网安备 33010602011771号
浙公网安备 33010602011771号