
第一次个人编程作业
| 这个作业属于哪个课程 | 计科国际班软工 |
|---|---|
| 这个作业要求在哪里 | 要求 |
| 这个作业的目标 | 论文查重程序 |
| 1.GitHub地址:https://github.com/Kris-0614/3119009426 | |
| 2.PSP表格 | |
| PSP2.1 | Personal Software Process Stages |
| --------------------------------------- | -------------------------------- |
| Planning | 计划 |
| · Estimate | · 估计这个任务需要多少时间 |
| Development | 开发 |
| · Analysis | · 需求分析 (包括学习新技术) |
| · Design Spec | · 生成设计文档 |
| · Design Review | · 设计复审 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) |
| · Design | · 具体设计 |
| · Coding | · 具体编码 |
| · Code Review | · 代码复审 |
| · Test | · 测试(自我测试,修改代码,提交修改) |
| Reporting | 报告 |
| · Test Repor | · 测试报告 |
| · Size Measurement | · 计算工作量 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 |
| Sum up | 合计 |
3、设计思路
通过在网上查找资料,了解到论文查重有两个常用的算法,分别是利用TF-IDF与余弦相似性和海明距离来判断文本的相似度,我在个人项目中采用了SimHash算法,过对不同文本的SimHash值进而比较海明距离,从而判断两个文本的相似度。
SimHash算法原理
1.分词
对给定的一段文本进行分词,产生n个特征词,并赋予每个特征词一个权重。比如一段文本为“中国科大计算机系的学生的能力怎么样”,产生的特征词就应该是“中国科大”、“计算机系”、“的”、“学生”、“能力”、“怎么样”,然后对这些词分别赋予权重,假设有1-5五个分类,分词之后以上五个词便会各有一个权重,比如中国科大(4)、计算机系(3)、的(1)、学生(4)、能力(5)、怎么样(3)。
其中,数字越大,代表特征词在句子中的重要性就越高。这样,我们就得到了一个文本的分词的词向量和每个词向量对应的权重。
2.Hash
通过hash函数对每一个词向量进行映射,产生一个n位二进制串,比如CSDN的hash值就是100101。
3.加权
前面的计算我们已经得到了每个词向量的Hash串和该词向量对应的权重,这一步我们计算权重向量W=hash*weight。
具体的计算过程如下:hash二进制串中为1的乘以该特征词的分词权重,二进制串中为0的乘以该特征词的分词权重后取负,继而得到权重向量。
举个例子,CSDN的hash二进制串是100101,CSDN的权重是3,那么生成的权重向量就是[3,-3,-3,3,-3,3]。
4.合并
对于一个文本,我们计算出了文本分词之后每一个特征词的权重向量,在合并这个阶段,我们把文本所有词向量的权重向量相累加,得到一个新的权重向量,形如[3,4,1,5,-5,1]
5.降维
对于前面合并后得到的文本的权重向量,大于0的位置1,小于等于0的位置0,就可以得到该文本的SimHash值,以上面提到的[3,4,1,5,-5,1]为例,我们得到[1,1,1,1,0,1]这个bit串,也就是论文中提及的该文本的指纹。
到此为止,我们已经计算出了一个文本的SimHash值。那么,如何判断两个文本是否相似呢?我们要用到海明距离。
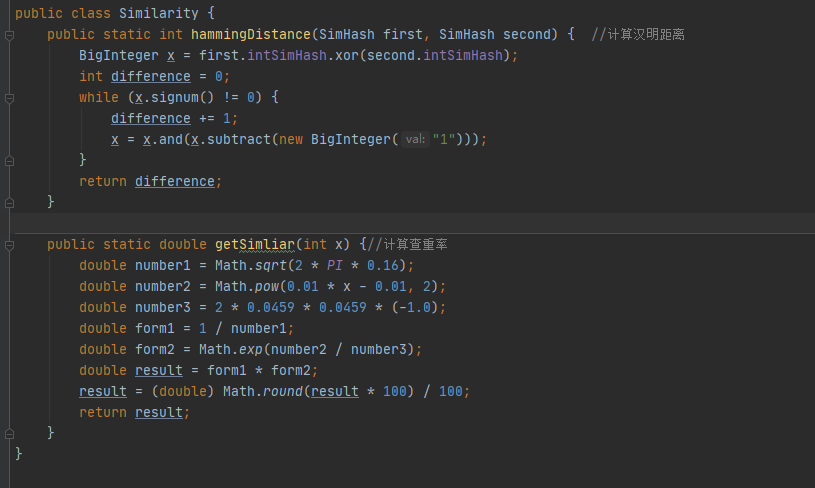
6.由公式 ,将汉明距离带入x即可计算出文本相似度
,将汉明距离带入x即可计算出文本相似度
4、项目各模块设计
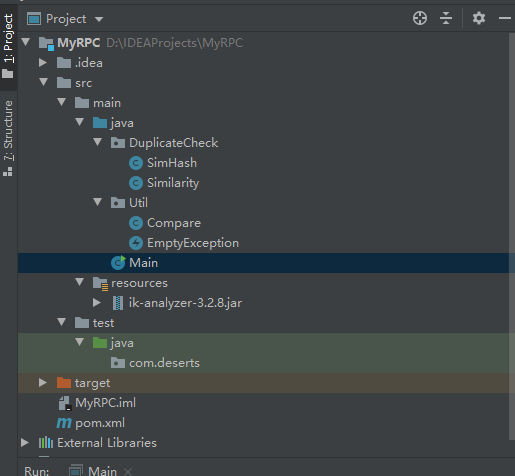
5.部分代码展示
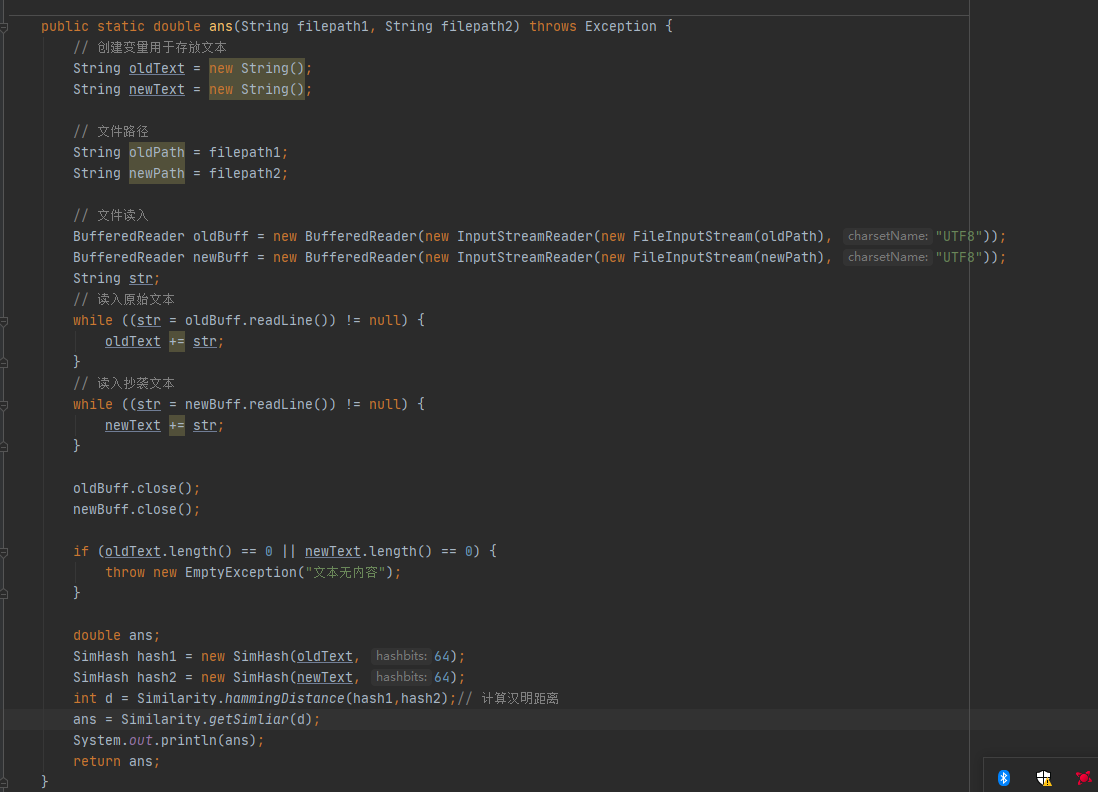
计算汉明距离,得到查重率
6.计算模块接口部分的性能
JVM监控工具
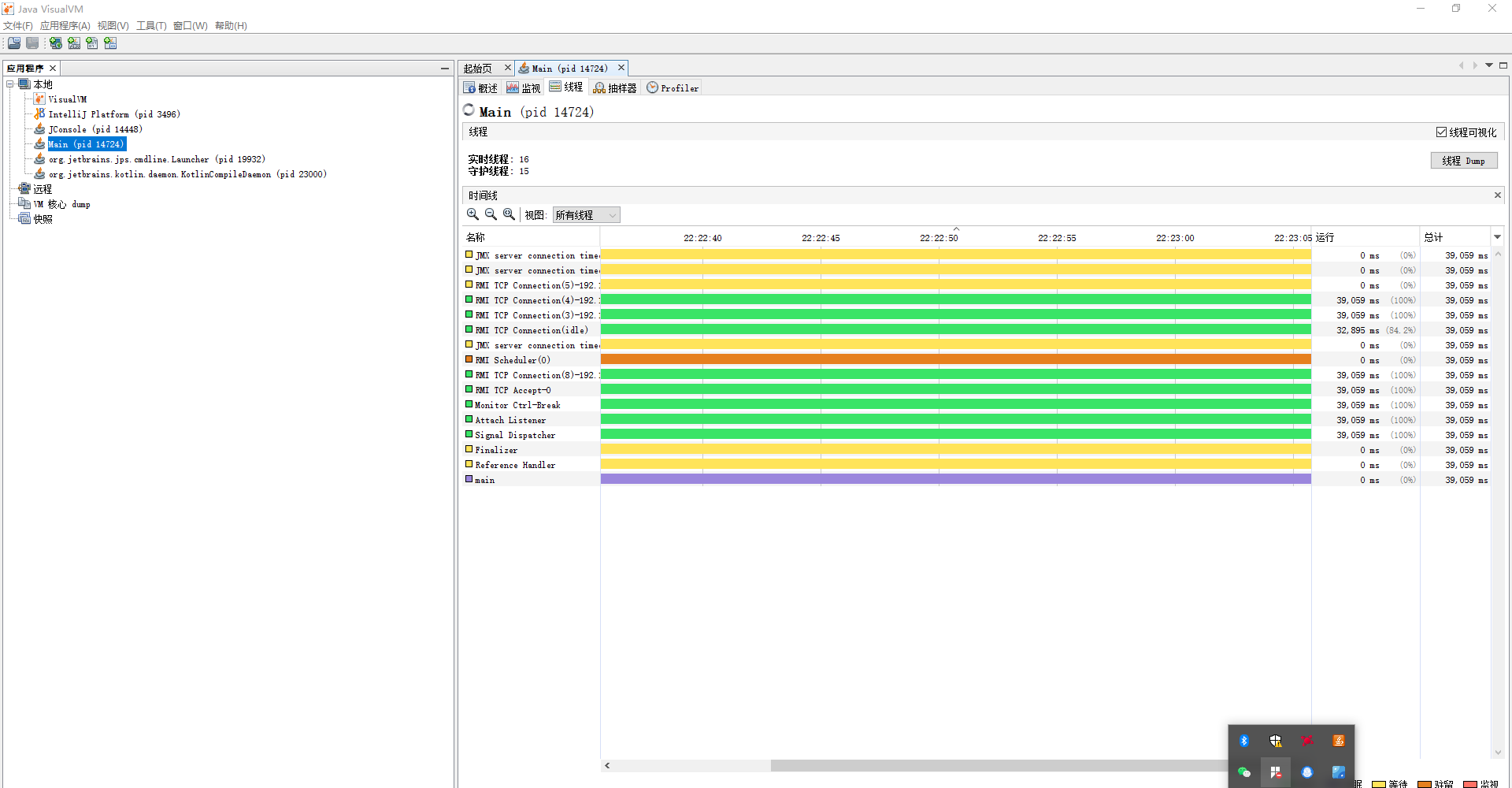
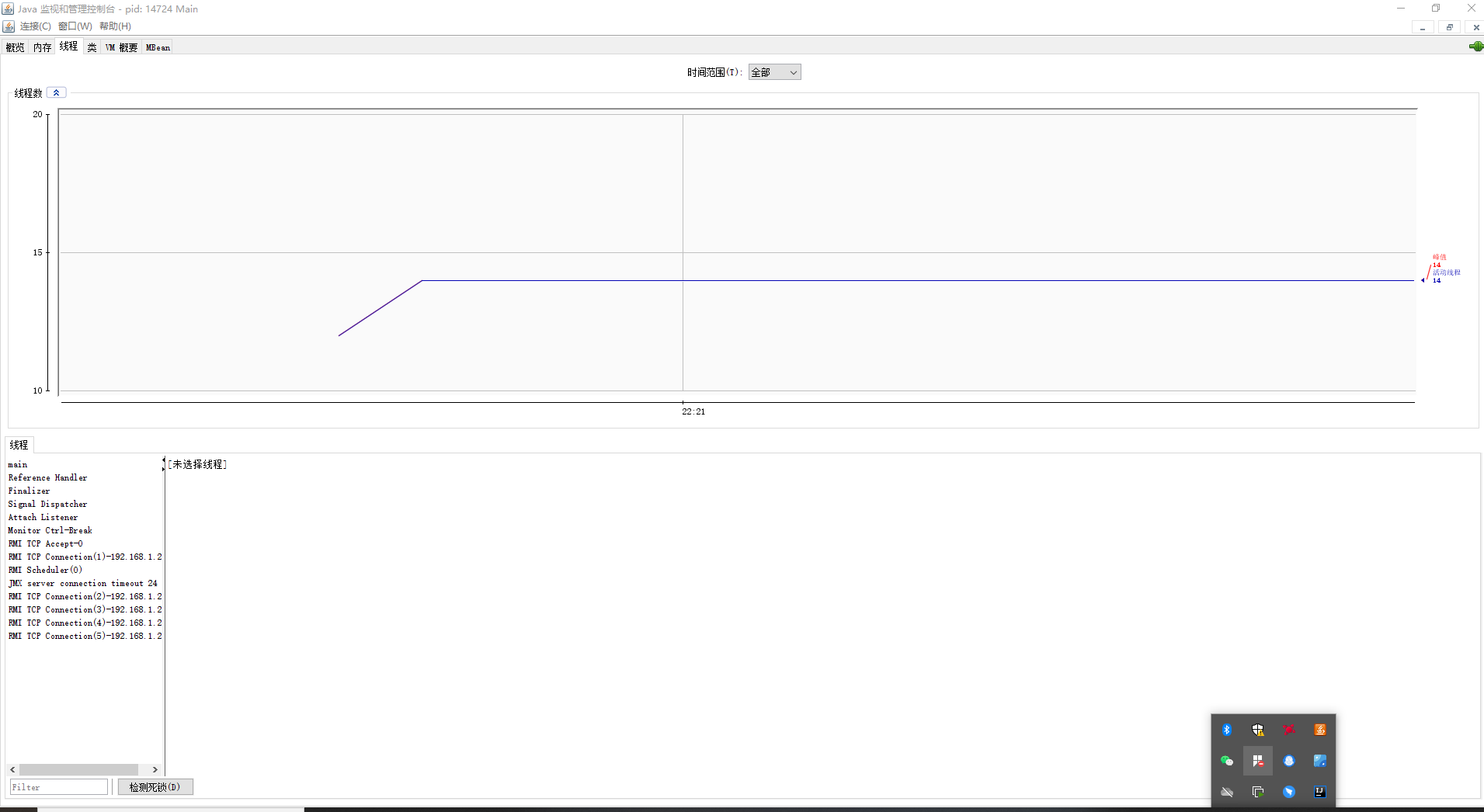
线程监控
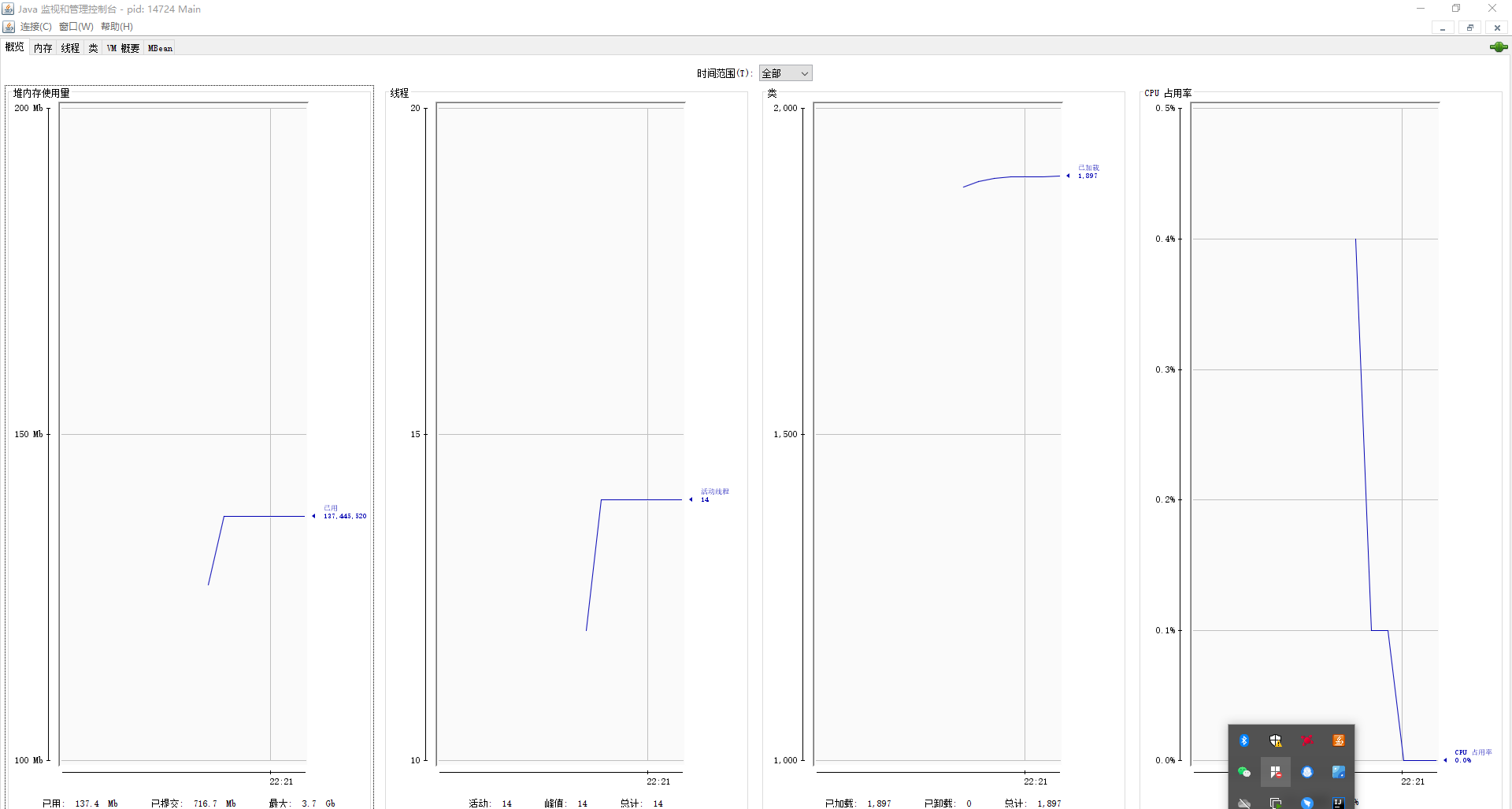
内存监控
7.项目测试结果
单元测试 多个测试文本重复率
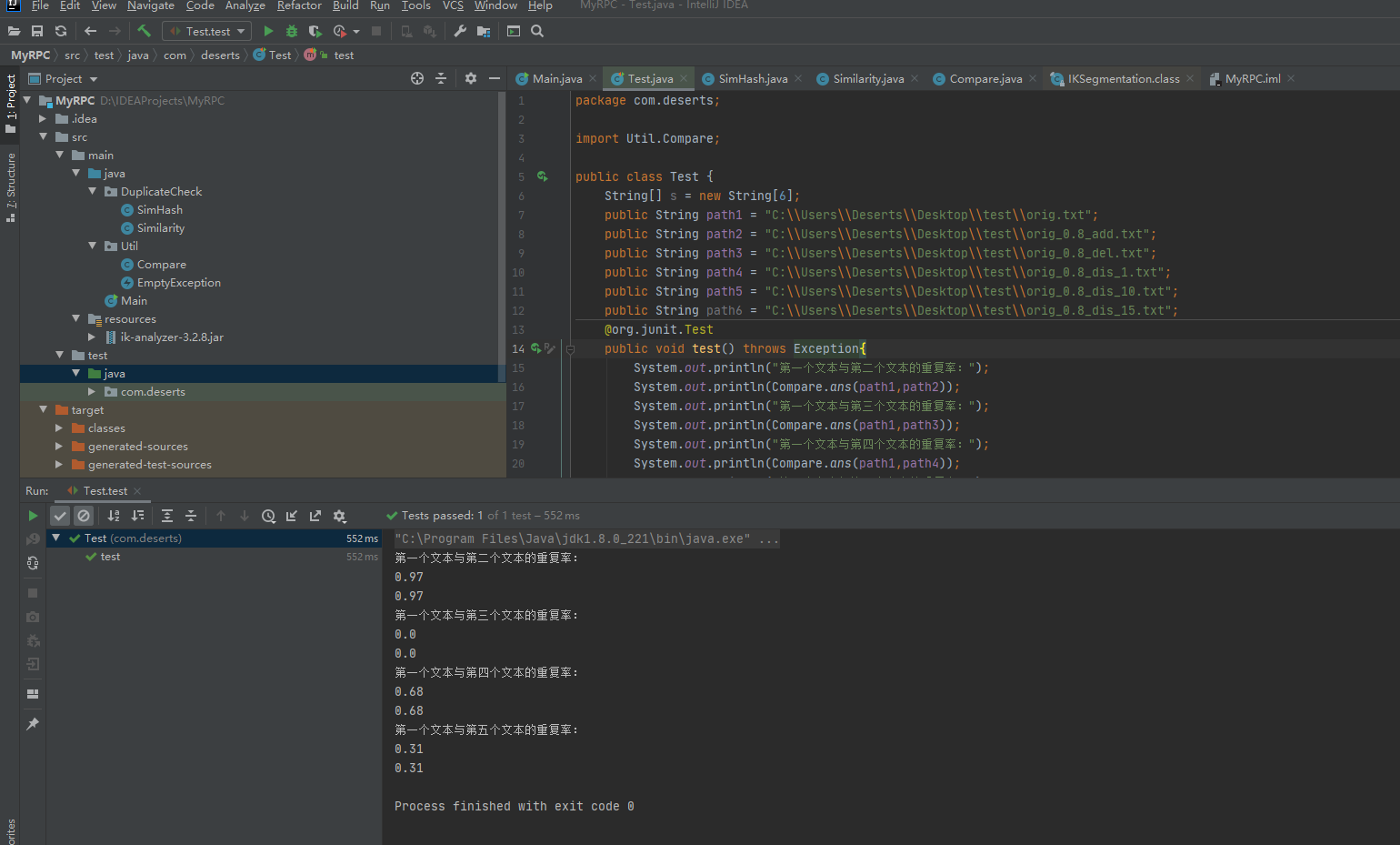
结果

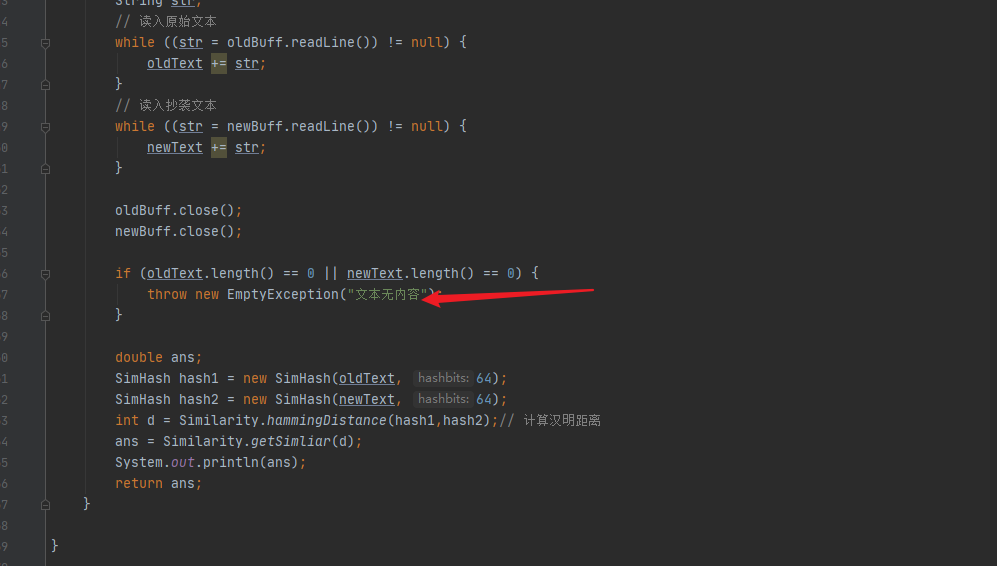
计算模块部分异常处理
空白文本异常

 浙公网安备 33010602011771号
浙公网安备 33010602011771号