Java使用selenium爬取加密网页
一般的网站可直接通过HttpClient进行网页爬取,但是如果一些网站用了js加密模板引擎的话,可能就爬取不到了
比如豆瓣的图书搜索页 : https://book.douban.com/subject_search?search_text=9787534293467
所以需要用到爬取数据的保底神器selenium,这个是完全模拟人的操作 , 所以只要网页看得到 ,它就爬的到
不过用起来也很麻烦,需要装驱动和浏览器,本文以Chrome浏览器为例。
(Windows的操作比较简单 , 自行根据本文研究 , 本文主要讲Linux下 , 测试环境为 CentOS7)
1.下载驱动
https://chromedriver.chromium.org/
直接下载就行
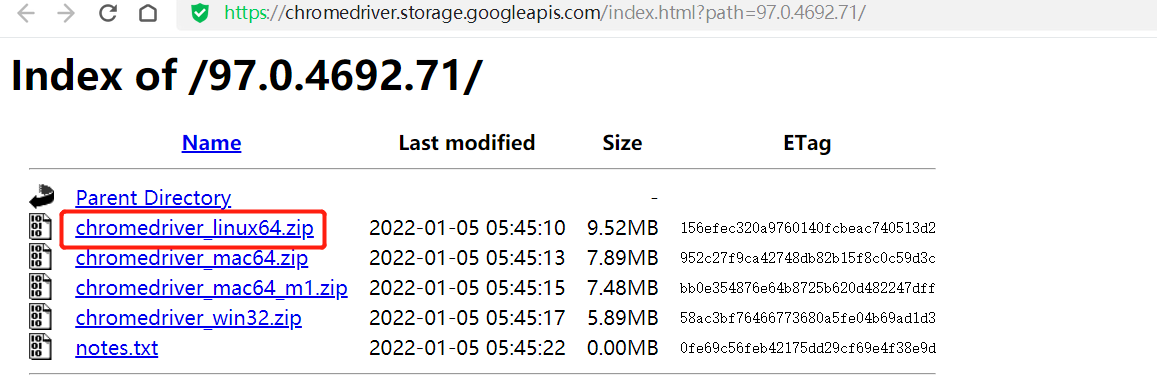
下载好之后 , 把解压后的文件 , 放到 /usr/bin/ 目录下面即可
2.Linux下安装谷歌
本文环境为 CentOS7.1
#直接安装 ,或者把脚本下载下来之后再安装 , 都行 curl https://intoli.com/install-google-chrome.sh | bash
安装完成之后的校验
[root@localhost ~]# google-chrome --version Google Chrome 97.0.4692.99
3.适用selenium爬取网页
/** * 使用浏览器模式爬取网页 , 需要本机安装Chrome和Chrome支持插件 * * @param baseUrl 需要爬取的网页 * @param waitDom 防止页面加载不全 , 而校验页面中的元素是否存在 , 语法参考jQuery , 比如 div[id='root'] * @param waitSecond 防止页面加载不全的最大等待时间 * @param chromeDriverDir ChromeDriver 执行文件指定位置 , 如果配置环境变量 , 可不设 * @param chromeBinaryDir Chrome可执行文件路径 , 如果是默认路径 , 可不设 * @author kreo * @date 2022/1/25 13:19 */ public static String htmlGet(String baseUrl, String waitDom, Long waitSecond, String chromeDriverDir, String chromeBinaryDir) { // 搜索的地址 // String baseUrl = SEARCH + isbn + "&cat=1001"; // 指定ChromeDriver的地址 if (IStr.isNotBlank(chromeDriverDir)) { log.debug("设置ChromeDriverDir >>> " + chromeDriverDir); System.setProperty("webdriver.chrome.driver", chromeDriverDir); } // 配置Chrome参数 ChromeOptions options = new ChromeOptions(); // 无浏览器模式 options.addArguments("--headless"); options.addArguments("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"); options.addArguments("--referer=" + baseUrl); // 配置Chrome的执行地址 if (IStr.isNotBlank(chromeBinaryDir)) { log.debug("设置ChromeBinaryDir >>> " + chromeBinaryDir); options.setBinary(chromeBinaryDir); } WebDriver driver = null; try { driver = new ChromeDriver(options); // 载入网页 log.info("爬取网页 >>> " + baseUrl); driver.get(baseUrl); // 模拟设置Cookie Cookie cookie = new Cookie("bid", "*"); driver.manage().addCookie(cookie); // 防止页面加载不完全 , 默认最长等待10秒 if (IStr.isNotBlank(waitDom)) { By by = By.cssSelector("div[id='root']"); waitForLoad(driver, by, IType.getLong(waitSecond, 15L)); } return driver.getPageSource(); } catch (Exception e) { log.error(">>>> 读取失败 >>> ", e); return null; } finally { if (driver != null) { driver.quit(); } } } /** * 等待元素加载 * * @param driver * @param by */ public static void waitForLoad(final WebDriver driver, final By by, final long waitSecond) { new WebDriverWait(driver, Duration.ofSeconds(waitSecond)).until( (ExpectedCondition<Boolean>) d -> { WebElement element = driver.findElement(by); if (element != null) { return true; } return false; }); }
测试 >>>>>>> :
/** 搜索地址 */ private static final String SEARCH = "https://book.douban.com/subject_search?search_text="; public static void main(String[] args) throws IOException { // 本机Windows下测试 // 如果是Linux下 , chromeDriverDir/chromeBinaryDir 都可设为null String pageSource = htmlGet( SEARCH + "9787534293467" + "&cat=1001", "div[id='root']", 10L, "D:/DevTools/ChromeDriver/chromedriver_win32/chromedriver.exe", "C:/Program Files/Google/Chrome/Application/chrome.exe" ); System.out.println(pageSource); }
或者用jsoup >>>
List<ImmutableMap<String, Object>> bookInfos = null; Document baseDoc = Jsoup.parse(pageSource); Elements itemBookEles = baseDoc.select("a[class=title-text]"); if (itemBookEles != null && itemBookEles.size() > 0) { bookInfos = Lists.newArrayList(); for (Element itemBookEle : itemBookEles) { String href = itemBookEle.attr("href"); bookInfos.add( ImmutableMap.<String, Object>builder() .put("title", itemBookEle.text()) .put("href", href) .build() ); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号