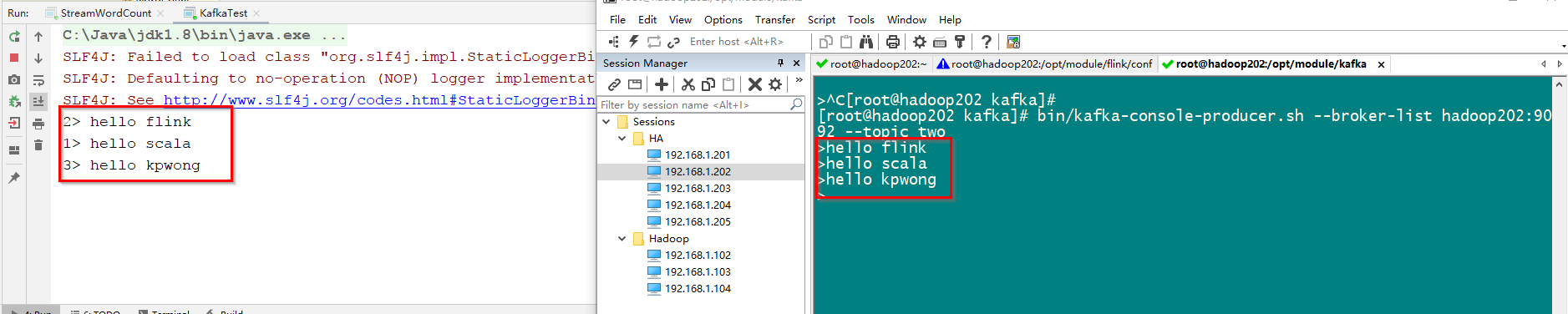
Flink 读取 Kafka数据
POM
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.11_2.11</artifactId>
<version>1.10.1</version>
</dependency>
</dependencies>
源码:
package com.kpwong.aiptest
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
object KafkaTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//从kafka读取数据
val prob: Properties = new Properties()
prob.setProperty("bootstrap.servers","hadoop202:9092")
//bin/kafka-console-producer.sh --broker-list hadoop202:9092 --topic two 发送数据命令
val kafkaDS: DataStream[String] = env.addSource( new FlinkKafkaConsumer011[String]("two",new SimpleStringSchema(),prob))
kafkaDS.print()
env.execute()
}
}
Kafka发送数据:
//bin/kafka-console-producer.sh --broker-list hadoop202:9092 --topic two
运行结果: