
Flink Batch File Word Count
POM文件
<dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.10.2</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.10.2</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.11</artifactId> <version>1.10.1</version> </dependency> </dependencies> <build> <plugins> <!-- 该插件用于将Scala 代码编译成class 文件--> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.6</version> <executions> <execution> <!-- 声明绑定到maven 的compile 阶段--> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
源码:
package com.kpwong.wc
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
//批处理的wordcount
object wordCount {
def main(args: Array[String]): Unit = {
//创建一个批处理执行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//从文件中读取数据
val inputPath = "G:\\flinkdemo\\FlinkTutorial\\src\\main\\resources\\hello.txt"
val inputDataSet: DataSet[String] = env.readTextFile(inputPath)
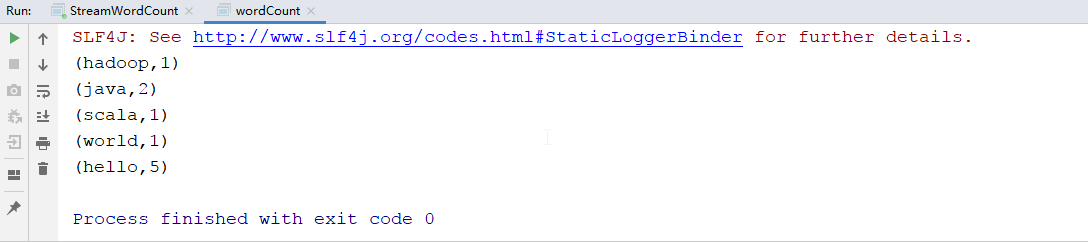
val resultDS: AggregateDataSet[(String, Int)] = inputDataSet.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
resultDS.print()
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号