
hadoop 再次格式化文件系统 bin/hdfs namenode -format
hadoop 系统第一次格式化系统运行
bin/hdfs namenode -format
完成后,运行一段时间。想重新格式化系统。需要注意。
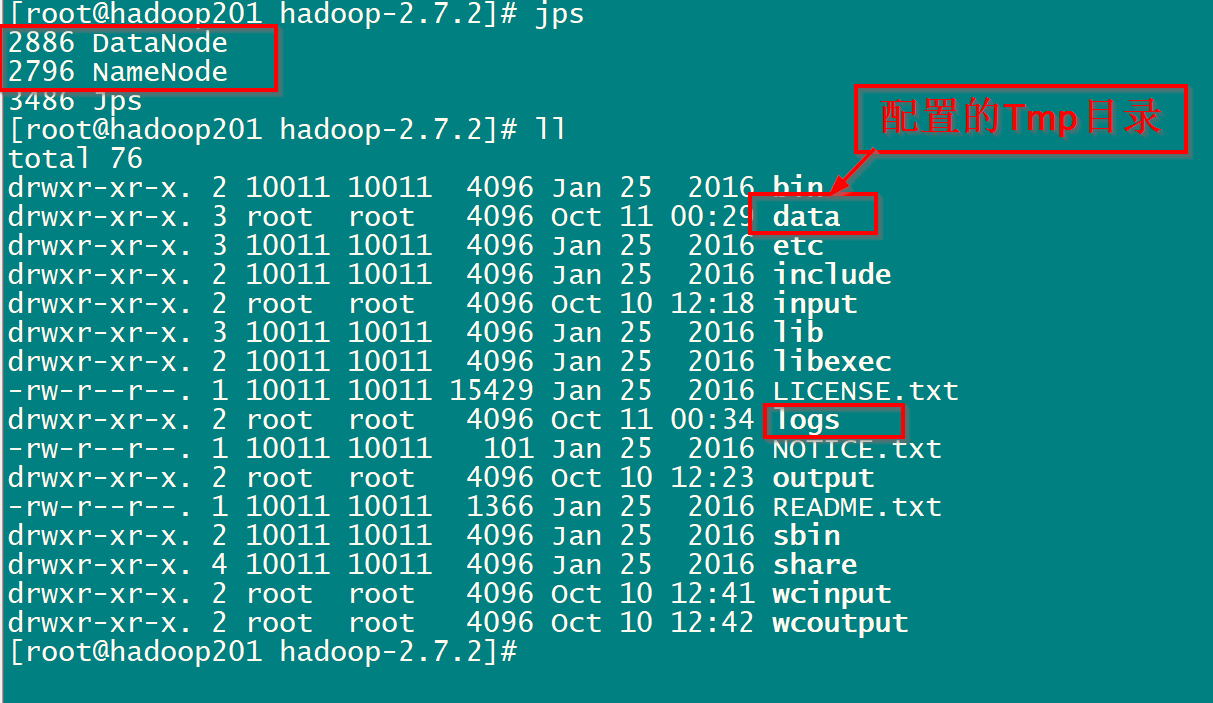
第一步:关停hadoop进程.NameNode,DataNode.
第二步:手动删除Data,logs目录。
第三步:运行 bin/hdfs namenode -format 命令 格式化系统.
为什么不能一直格式化NameNode,格式化NameNode,要注意什么?
[root@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/name/current/
[root@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
[root@hadoop101 hadoop-2.7.2]$ cd data/tmp/dfs/data/current/
[root@hadoop101 current]$ cat VERSION
clusterID=CID-f0330a58-36fa-4a2a-a65f-2688269b5837
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。所以,格式NameNode时,一定要先删除data数据和log日志,然后再格式化NameNode。

