部分网页中仅供浏览的pdf文件下载方法
现在越来越多的网站提供的PDF资料只能在线浏览,不提供下载功能,实际上仅仅是通过网页PDF浏览插件来访问文件资源,如果能够获取到该文件的访问地址,就可以访问下载。
以Firefox浏览器访问某大学网站为例:
该网页文件浏览插件不提供下载功能:

方法一:
1.页面右击选择“查看页面源代码”;
2.Ctrl+F或者在搜索框内输入“.pdf”搜索;
3.找到pdf的url地址并复制;

4.如果地址前域名缺省,在前面加上www.域名;
5.在浏览器地址栏中输入并访问,即可将该pdf文件下载。

方法二:
1.在页面右击选择检查选项;
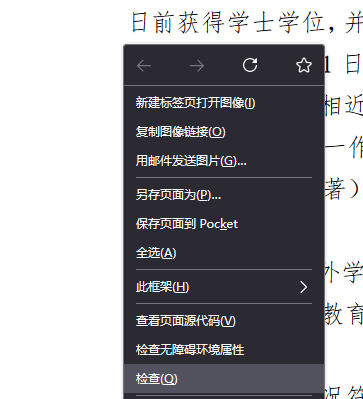
2.选择“网络”;

3.选择“XHR”后点击“重新载入”;
4.此时列表中会出现加载的pdf文件,该文件即为我们所需下载的文件;
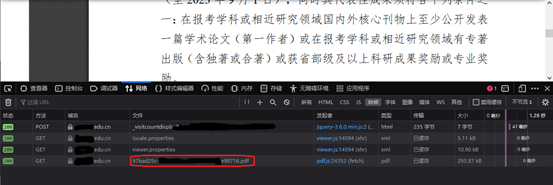
5.将鼠标移至该文件名上可出现该文件的访问地址,此时我们只需在该文件名上右击,选择“复制值”-“复制网址”,即可获取该访问地址;
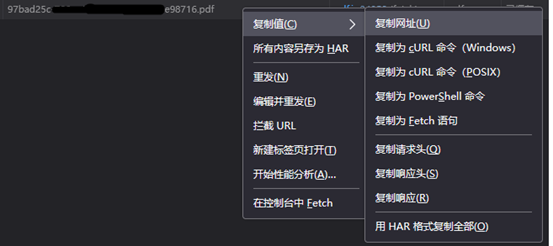
6.最后只需在浏览器地址栏中将该地址粘贴上去,回车,该文件即开始自动下载。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号