
MongoDB
1.介绍及spring boot操作
介绍:https://blog.csdn.net/yanpenglei/article/details/79261875
操作:https://www.jianshu.com/p/fdd7e303dff1
spring boot注解介绍:https://cloud.tencent.com/developer/article/1384034
2.概念
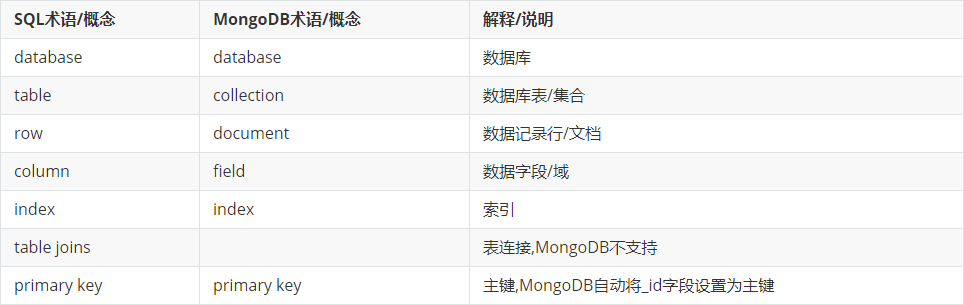
3.命令
3.1 基础命令
show dbs; #展示所有数据库
use dbname; #切换数据库
db; #展示当前数据库名称
show collections; #展示当前数据库所有的集合名称
db.collectionName.find(); #展示collectionName集合下所有记录
3.2 数据库操作
db.collectionName.insert({records}); #向不存在的库中新建一个集合插入一条数据即可新建一个数据库
db.dropDatabase(); #在要删除的库下面执行该命令,即可删除该库
3.3 集合操作
3.3.1 创建集合
db.createCollection(name, options) #创建集合
例如:
db.createCollection("mycol", { capped : true, autoIndexId : true, size : 6142800, max : 10000 } )
参数说明:
-
name: 要创建的集合名称
-
options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:

在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
当插入一些文档时,MongoDB 会自动创建集合
db.mycol2.insert({"name" : "菜鸟教程"})
3.3.2 删除集合
db.collectionName.drop()
3.4 文档操作
3.4.1 插入文档
db.COLLECTION_NAME.insert(document)
#若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。
db.COLLECTION_NAME.save(document)
#已废弃,新版本可使用insertOne()或者replaceOne()
3.2 版本之后新增
#向集合插入一个新文档
db.collection.insertOne(
<document>,
{
writeConcern: <document>
}
)
#向集合插入一个多个文档
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
#操作
# 插入单条数据
> var document = db.collection.insertOne({"a": 3})
> document
{
"acknowledged" : true,
"insertedId" : ObjectId("571a218011a82a1d94c02333")
}
# 插入多条数据
> var res = db.collection.insertMany([{"b": 3}, {'c': 4}])
> res
{
"acknowledged" : true,
"insertedIds" : [
ObjectId("571a22a911a82a1d94c02337"),
ObjectId("571a22a911a82a1d94c02338")
]
}
3.4.2 修改操作
**update()方法 **
# 将匹配到的值都进行修改
# <multi>属性默认是false(不写就是默认),即每次只修改扫描到的第一条数据;
# 当为true时,修改所有
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}},{multi:true})
**save()方法 **
# 将匹配到的值都进行修改
# <multi>属性默认是false(不写就是默认),即每次只修改扫描到的第一条数据;
# 当为true时,修改所有
db.col.save({
"_id" : ObjectId("5f2374ebb38cdd2108824376"),
"title" : "MongoDB",
"description" : "MongoDB 是一个 Nosql 数据库",
"by" : "Runoob",
"url" : "http://www.runoob.com",
"tags" : [
"mongodb",
"NoSQL"
],
"likes" : 110
})
3.4.3 删除操作
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
参数说明:
-
query :(可选)删除的文档的条件。
-
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
-
writeConcern :(可选)抛出异常的级别。
db.col.deleteOne({'title':'MongoDB 教程'});
db.col.deleteMany({'title':'MongoDB 教程'});
3.4.3 查询操作
db.collection.find(query, projection)
-
query :可选,使用查询操作符指定查询条件
-
projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
若不指定 projection,则默认返回所有键,指定 projection 格式如下,有两种模式
db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键
db.collection.find(query, {title: 0, by: 0}) // exclusion模式 指定不返回的键,返回其他键
_id 键默认返回,需要主动指定 _id:0 才会隐藏
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
db.collection.find(query, {title: 1, url: 0}) // 错误
只能全1或全0,除了在inclusion模式时可以指定_id为0
db.collection.find(query, {_id:0, title: 1, url: 1}) // 正确
MongoDB 与 RDBMS Where 语句比较
如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询:
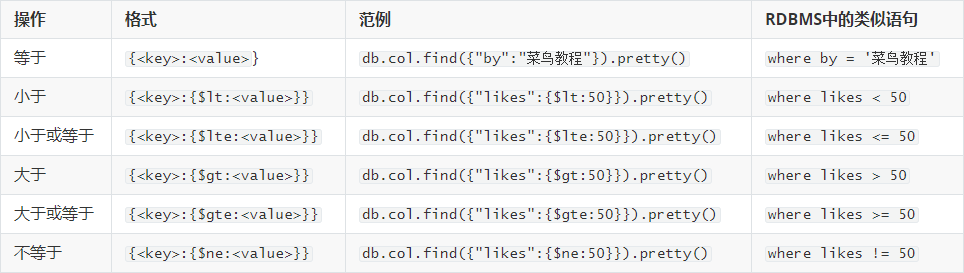
#若是50<likes<110
#写法为
db.col.find({likes: { $lt: 110 ,$gt: 50}})
MongoDB AND条件语句
db.col.find({key1:value1, key2:value2}).pretty()
MongoDB OR条件语句
db.col.find({$or:[{"by":"菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
MongoDB AND和OR联合使用
db.col.find({"likes": {$gt:50}, $or: [{"by": "菜鸟教程"},{"title": "MongoDB 教程"}]}).pretty()
MongoDB sort() 方法
#sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
db.col.find().sort({_id:1}).limit(1)
❤️注意:skip(), limilt(), sort()三个放在一起执行的时候,执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
MongoDB Limit与Skip方法
skip方法在执行时,会遍历所有数据,一条一条过滤。
# 以下实例为显示查询文档中的两条记录
db.col.find({},{"title":1,_id:0}).limit(2)
#以下实例只会显示第二条文档数据
db.col.find({},{"title":1,_id:0}).limit(1).skip(1)
#注意:无论limit是在前面还是后面,skip出现时,skip优先执行
❤️此外,limit和skip联合使用可以用来分页,但是当数据量大的时候会对性能有一定影响
官网建议:https://www.cnblogs.com/woshimrf/p/mongodb-pagenation-performance.html#_caption_1
MongoDB 分页
# 方法一
# 查询第一页
db.col.find().sort({_id:1}).limit("pageSize");
# 查询之后的页数
db.col.find().sort({_id:1}).limit("pageSize").skip("pageSize * pageNum");
该方法在数据量大的情况下,性能会有点低,原因由skip方法导致。
# 方法二
# 查询第一页
db.col.find().sort({_id:1}).limit("pageSize");
# 查询之后的页数
# 获取每页最后一条记录的_id为lastOneId
db.col.find({_id:{$gt: lastOneId}}).sort({_id:1}).limit("pageSize")
3.5 管道操作
//TODO
3.6 聚合操作
//TODO

