
深度优先搜索、广度优先搜索
深度优先搜索:
英文是Depth First Search,简称为DFS。主要思路就是从图/树中一个顶点开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路走到底。。。不断重复此过程,直到所有的节点都遍历完成。DFS的特点就是一条道走到黑,不撞南墙不回头。
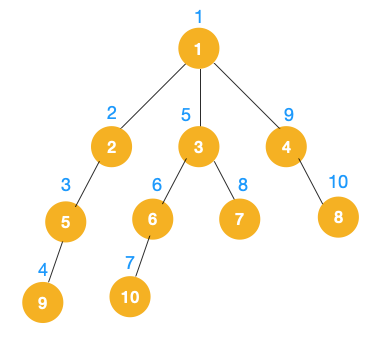
DFS遍历下面的树,步骤是:
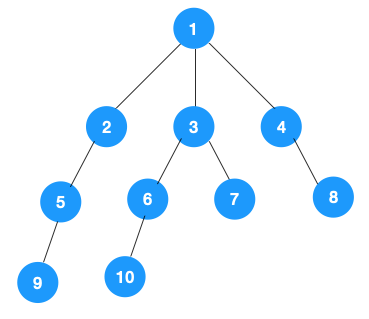
1、从根节点1开始遍历,它的子节点有2、3、4,先遍历节点2,再遍历节点2的子节点5,再遍历节点5的子节点9。如下图
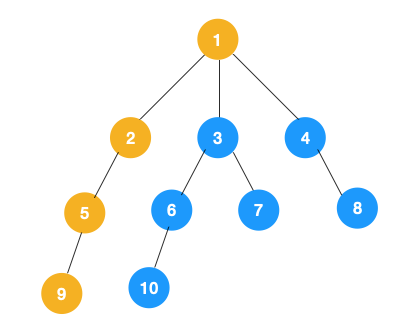
2、走到底后要回退。从节点9回退到节点5,看下节点5是否有除节点9外的子节点。没有,则继续回退到节点2,再继续回退到节点1。节点1有除节点2外的子节点3、4,从节点3开始深度遍历。如下图
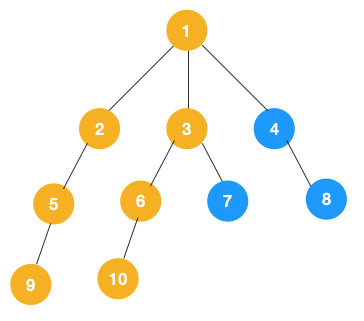
3、同理,从节点10往上回退到节点6,节点6没有除10外的子节点,再回退到节点3,节点3有除节点6外的子节点7,遍历7。如下图
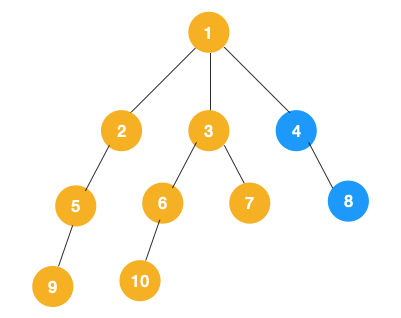
4、从节点7往上回退到节点3,节点3没有除节点6、7外的子节点了,再往上回退到节点1。节点1还有除节点2、3外的子节点4,所以此时沿着节点4、8遍历。
综上,完整的遍历顺序如下
二叉树的DFS就是前序遍历。
DFS有递归和非递归两种实现方式。以二叉树的遍历讲解。
递归方式:
递归实现比较简单。从根节点开始,依次遍历根节点及其左右子树。遍历子树时,也是先遍历子树的根节点,再遍历其左右子树。

/** * Definition for a binary tree node. * public class TreeNode { * int val; * TreeNode left; * TreeNode right; * TreeNode() {} * TreeNode(int val) { this.val = val; } * TreeNode(int val, TreeNode left, TreeNode right) { * this.val = val; * this.left = left; * this.right = right; * } * } */ class Solution { public List<Integer> preorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if (root == null) { return list; } preOrderWithList(root, list); return list; } private void preOrderWithList(TreeNode root, List<Integer> list) { if (root == null) { return; } list.add(root.val); if (root.left != null) { preOrderWithList(root.left, list); } if (root.right != null) { preOrderWithList(root.right, list); } } }
递归方式,如果层级过深,有可能会栈溢出。实测不到10000层就栈溢出了,报StackOverflowError。可以考虑用尾递归来优化。
非递归方式:
非递归方式是有固定套路的,即建一个栈,先把根节点push到栈中。然后开启循环,循环中的操作是pop栈得到一个节点,访问其数据,然后把这个节点的右节点和左节点依次push到栈中。循环的退出条件是栈为空。
public List<Integer> preorderTraversal(TreeNode root) { List<Integer> list = new ArrayList<>(); if (root == null) { return list; } preOrderWithList(root, list); return list; } private void preOrderWithList(TreeNode root, List<Integer> list) { if (root == null) { return; } Deque<TreeNode> stack = new ArrayDeque<>(); stack.push(root); while (!stack.isEmpty()) { TreeNode node = stack.pop(); list.add(node.val); if (node.right != null) { stack.push(node.right); } if (node.left != null) { stack.push(node.left); } } }
使用非递归方式不用担心栈溢出。
广度优先搜索:
英文是Breadth First Search,简称为BFS,适用于层序遍历和最短路径问题。
广度优先是有固定套路的,即建一个队列,先把根节点add到队列中。然后开启循环,循环中的操作是先算出队列的长度,假设为N,则remove N次。在每次remove拿到节点后,先把这个节点的左子节点和右子节点加到队列后,再remove拿下一个节点。循环的退出条件是队列为空。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】
2017-08-06 mysql一些概念