
group_by 对mutate,summary里的基础函数的适用情况
group_by的价值在于对 从对整个数据框的数据处理,转换为对每个组内的数据处理。
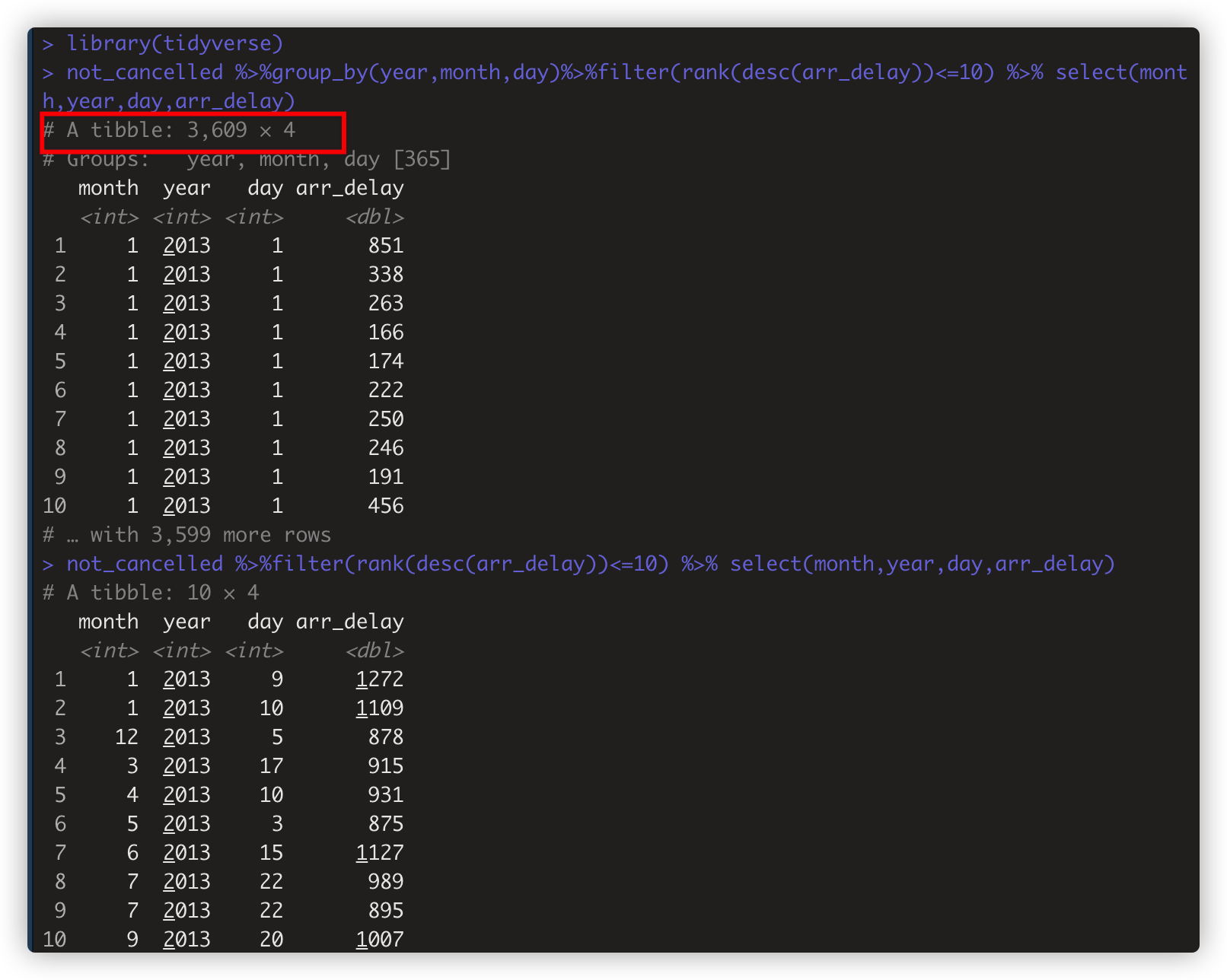
如:> not_cancelled %>%group_by(year,month,day)%>%filter(rank(desc(arr_delay))<=10) %>% select(month,year,day,arr_delay) #取各组内的前10记录。
> not_cancelled %>%filter(rank(desc(arr_delay))<=10) %>% select(month,year,day,arr_delay) #取数据框所有数据的前10记录。
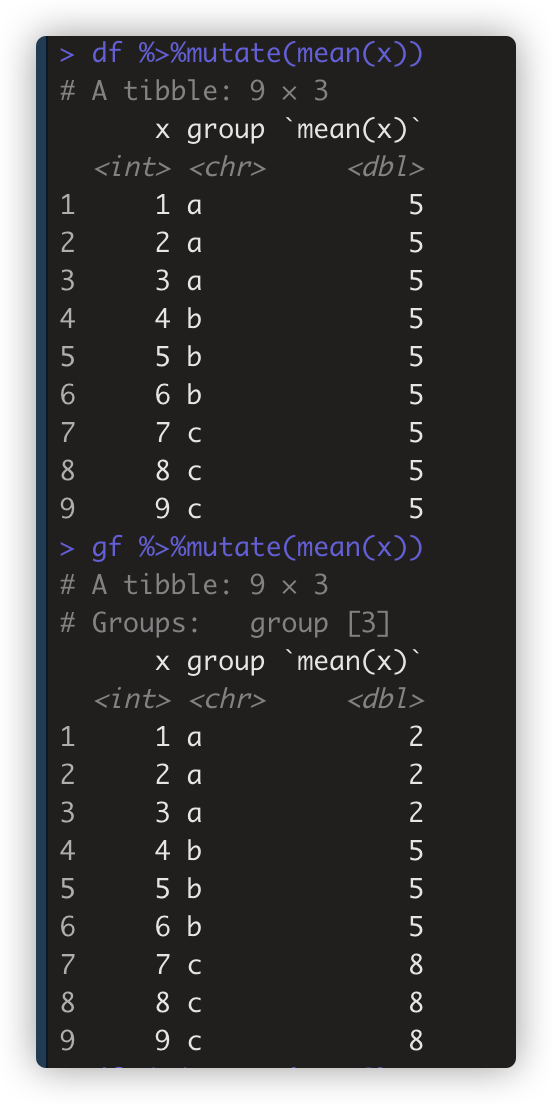
- 摘要函数 如mean() ,median() 适用以分组为基础计算 如 gf %>%mutate(mean(x))

-
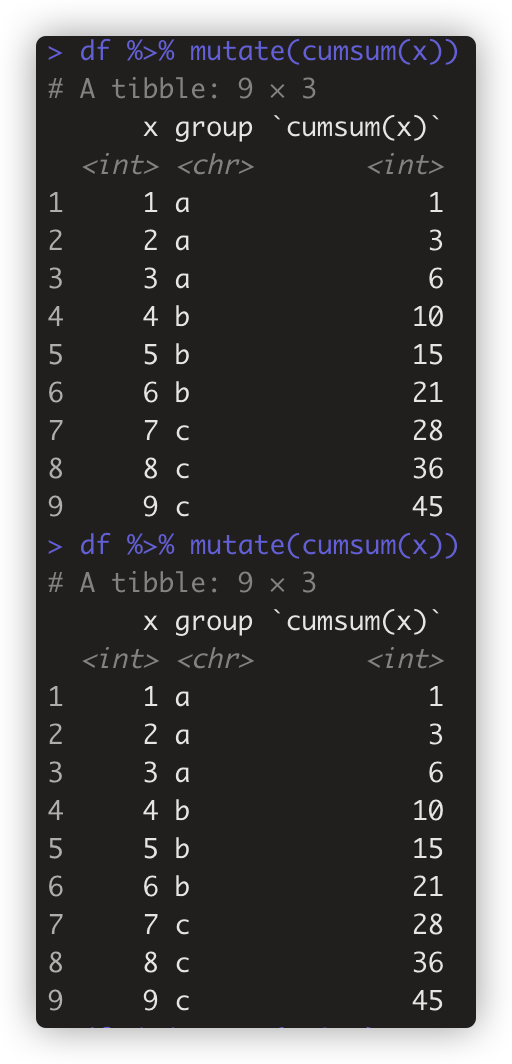
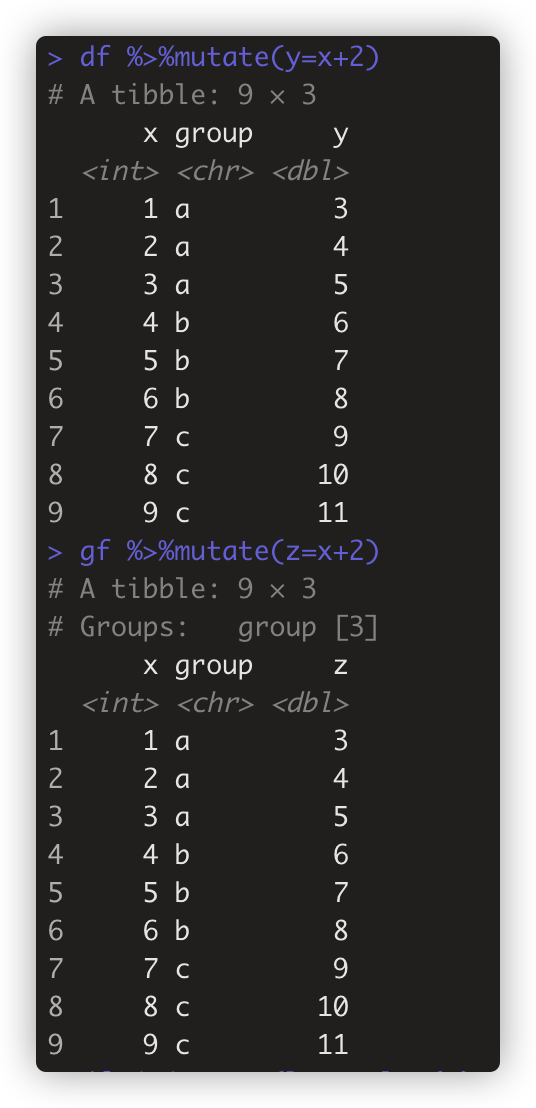
- 对已有变量单个值的运算符不适用按向量分组分组。如 + - log() %/% %% < == 等。 如 gf %>%mutate(z=x+2)
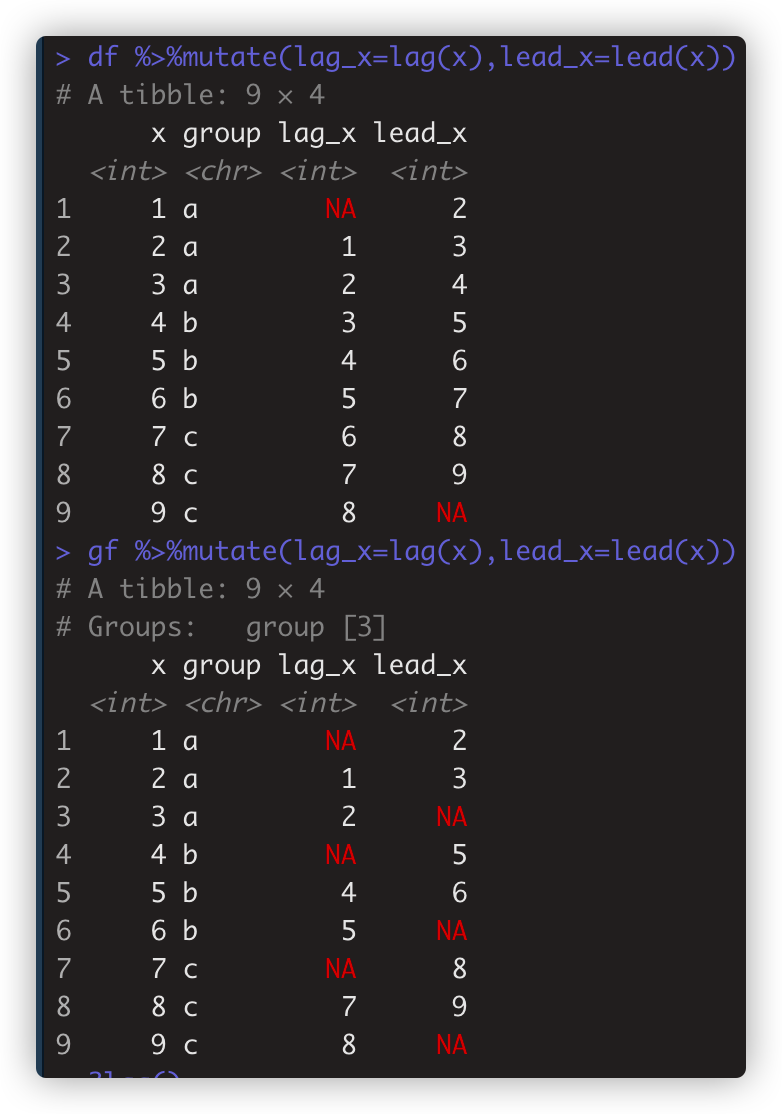
- 偏移函数lag(),lead(),min_rank(),row_number() 同样会按组计算 如
- gf %>%mutate(lag_x=lag(x),lead_x=lead(x))
- gf %>% mutate(min_rank(x))
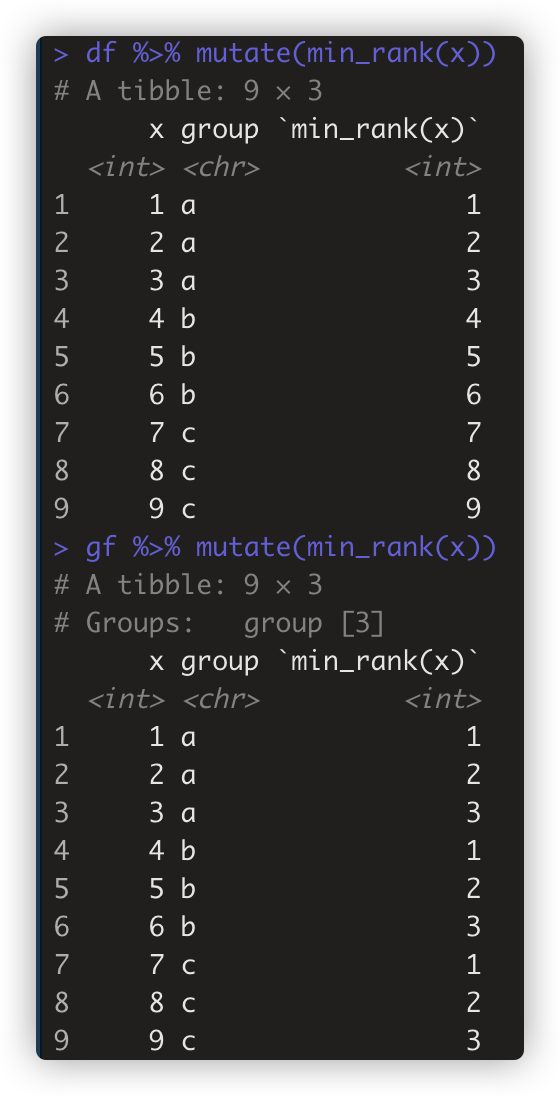
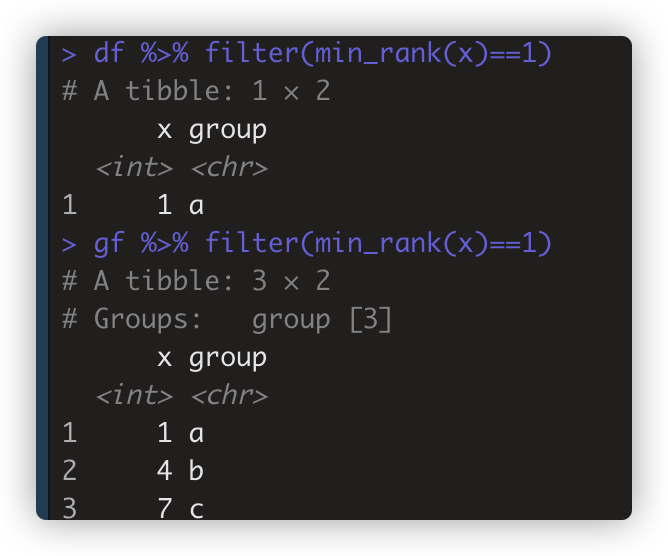
-
其中取每个分组的第一个值gf %>% filter(min_rank(x)==1)
-
arrange()需要指定.group=TRUE,才适用。如df %>% group_by(group) %>%arrange(x,.by_group=TRUE)
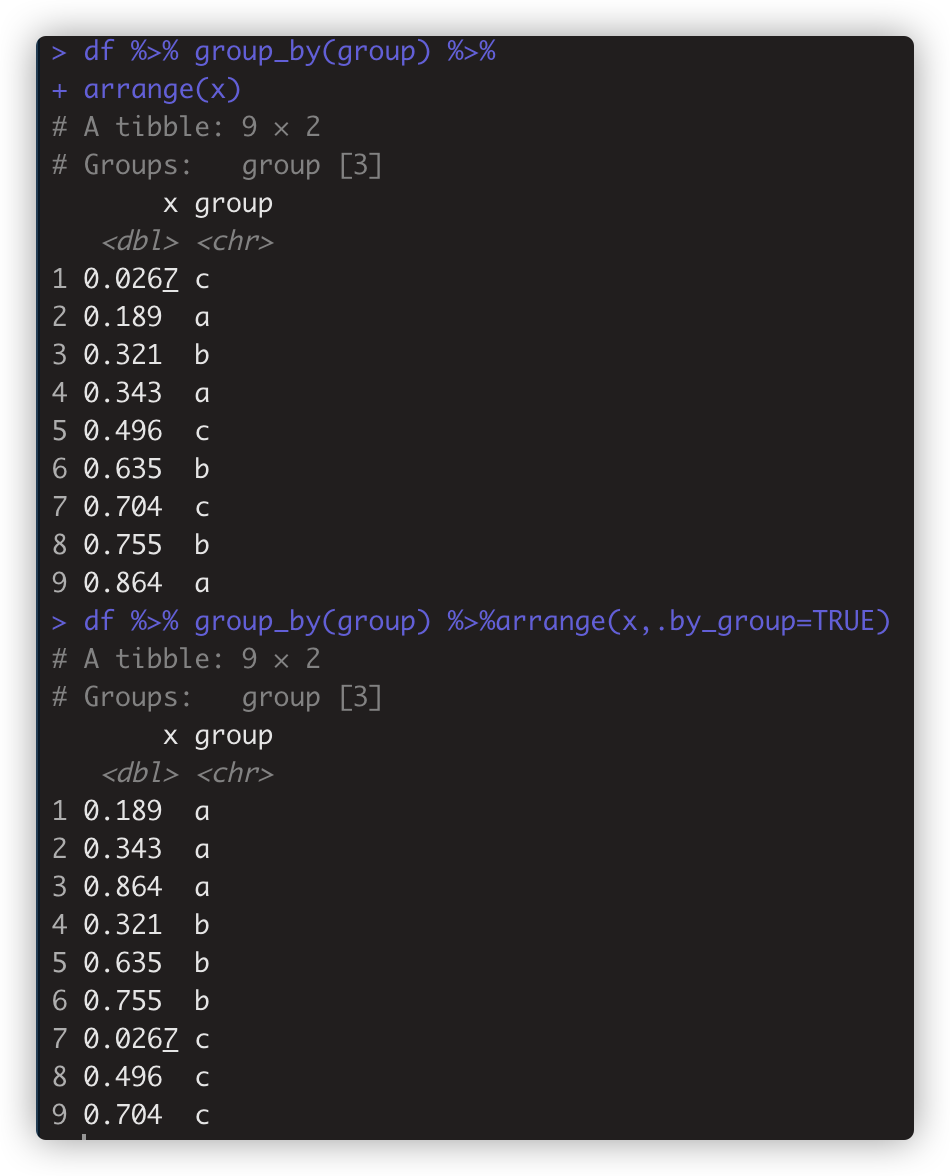
lag() 返回向量中元素前一个值
lead() 返回向量中元素后一个值
#Find the "previous" (lag()) or "next" (lead()) values in a vector. Useful for comparing values behind of or ahead of the current values.
本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15706234.html

posted on 2021-12-18 22:19 BioinformaticsMaster 阅读(299) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律