
下检测单前,过滤重复数据
需求:
1)与以前存在的样本名称相同的,筛选出来,这是重复样本,做减法,不后续实验
2) 重复样本中以前检测不合格的,加上,做后续实验。
准备工作:
1.unique的已存在样本列表
-
123456789101112131415
<strong>first_four_Sample<-read.csv("./first_four_Sample.csv")#如果有first_five文件,直接校验duplicatd就行</strong>fifth<-read.csv("./five_uniq_第五批去重去异常.csv")View(first_four_Sample)View(fifth)fifth$客户样本名称fifth$invSampleName<-fifth$客户样本名称# 统一变量名,后续好对列操作fifth$invSampleNamefirst_five<-c(first_four_Sample$invSampleName,fifth$invSampleName)#合并向量first_five<strong>first_five[duplicated(first_five)]# 保障uniq后,继续。summary(first_five)#看有多少观测行</strong>
2. 本次入库待实验的样本
1 2 3 4 5 | sixth<-read.csv("./sixth_2088_Sample.csv")<br>View(sixth)sixth$invSampleNamefirst_six<-c(first_five,sixth$invSampleName)summary(first_six)first_six[duplicated(first_six)] #这里可以sixth_repeated<-first_six[duplicated(first_six)]。如果有dup则继续。为空的话直接全下检测单就行了 |
3. 之前检测不合格的样本
-
12345678
unqualified143<-read.csv("../143unqualified_1217.csv")View(unqualified143)intersect(unqualified143$客户样本名称,first_six[duplicated(first_six)])#本次样本中需要弥补之前不合格的样本sixth_nonrepeate<-setdiff(sixth$invSampleName,first_six[duplicated(first_six)]) #本次入库的非重复样本summary(sixth_nonrepeate)<br>sixth_need<-c(sixth_nonrepeate,supple_unqalified)#需要后续实验的所有样本summary(sixth_need)sample_sixth<-data.frame(invSampleName=sixth_need)View(sample_sixth)#构建一个数据框,方便和后边数据框拼接inner_join
4. 拼接样本信息表及入库单编码。
-
123456789101112
sixth_code<-read.csv("./第六批入库单编码.csv")#入库单编码View(sixth_code)sixth_sampleinfo<-read.csv("./入库第六次_2088样本.csv")#样本信息单View(sixth_sampleinfo)sixth_code$invSampleNamesampleinfo_code<-dplyr::inner_join(sixth_sampleinfo,sixth_code,by="invSampleName")#拼接两个数据框View(sampleinfo_code)glimpse(sampleinfo_code)sampleinfor_code_nonextended<-sampleinfo_code %>%select(!starts_with("extended"))#extend太多列了,不需要glimpse(sampleinfor_code_nonextended)
5. 生成需要的样本信息表
-
123456
test6_need<-dplyr::inner_join(sampleinfor_code_nonextended,sample_sixth,by="invSampleName")#需要后续实验的样本信息表,注意sample_six在后,不然新增的前面质检不合格样本不与之前板号连续View(test6_need)write_excel_csv(test6_need,"./test6_need.csv")repeat6<-first_six[duplicated(first_six)]#重复样本也保留write.csv(repeat6,"./repeat_6th.csv")
新知识
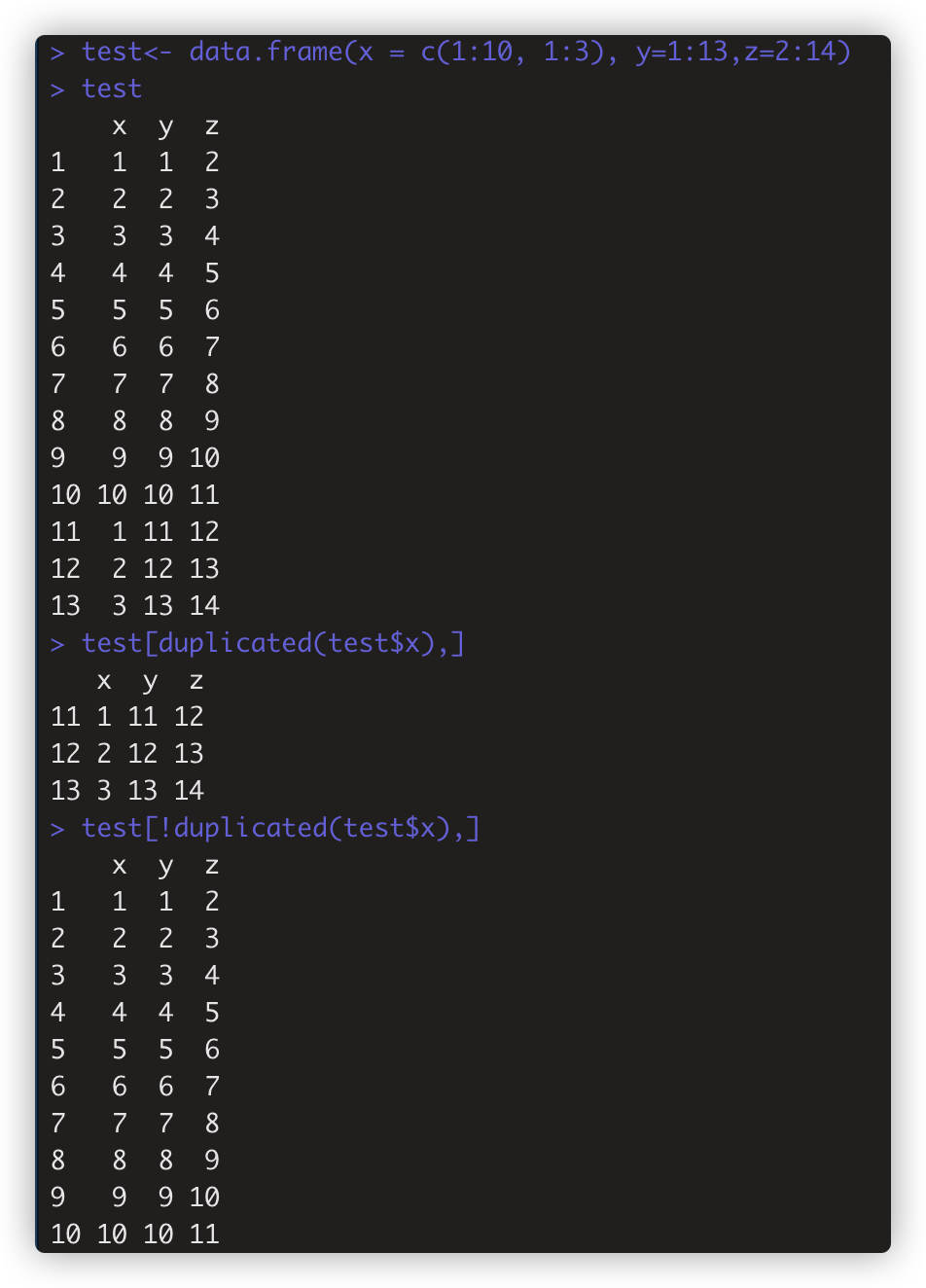
1 | first_six[duplicated(first_six)] 取出向量的重复观测<br><br>数据框的话,如:<br>> test[!duplicated(test$x),] #与前面观测值 重复的行<br>> test[!duplicated(test$x),] #唯一观测,重复项取第一次出现的行。 |
intersect(x,y) 两个向量取交集
union(x,y) 取并集
setdiff(x,y) 取x-y 的部分集。

本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15702741.html

posted on 2021-12-17 16:14 BioinformaticsMaster 阅读(41) 评论(0) 编辑 收藏 举报


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律