
factor()函数
因子型(factor)表示编号或登记,是用来存储类别的数据类型,是离散的,与连续性值相对。如果把数字作为因子,那么在导入数据后,需要将向量转换为因子(factor),而因子在整个计算过程中不再作为数值,而是作为“符号”。 讲的很好的R因子
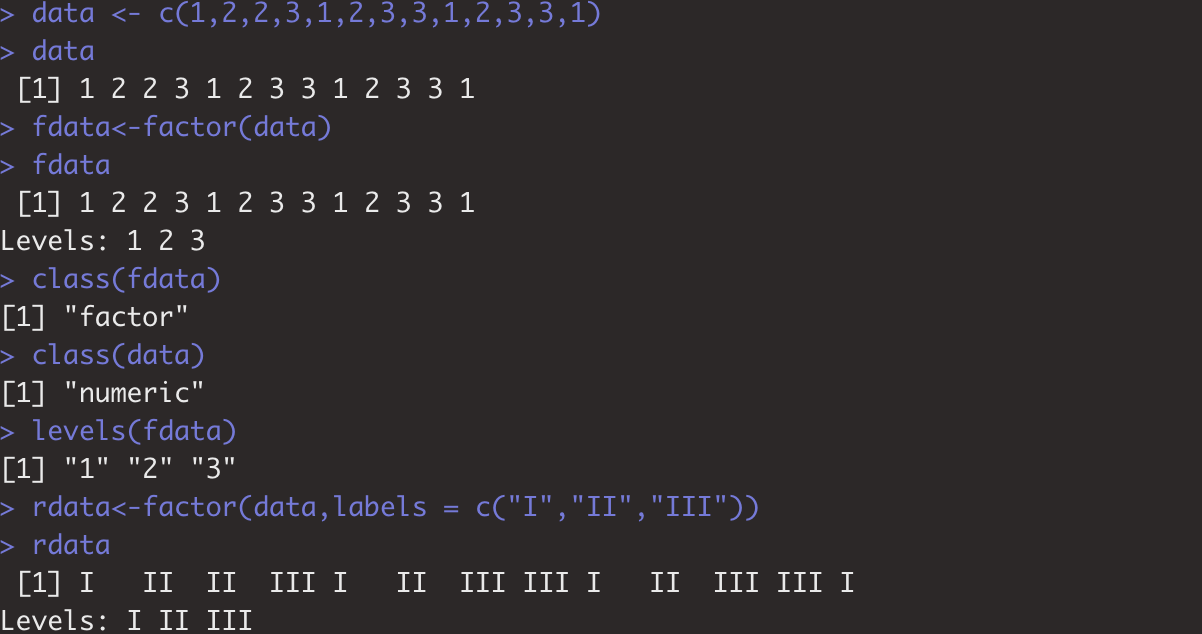
data <- c(1,2,2,3,1,2,3,3,1,2,3,3,1)
data
fdata<-factor(data)
fdata
class(fdata)
class(data)
levels(fdata)
rdata<-factor(data,labels = c("I","II","III"))
rdata
rdata<-factor(data,labels=c("e","ee","eee"))
rdata
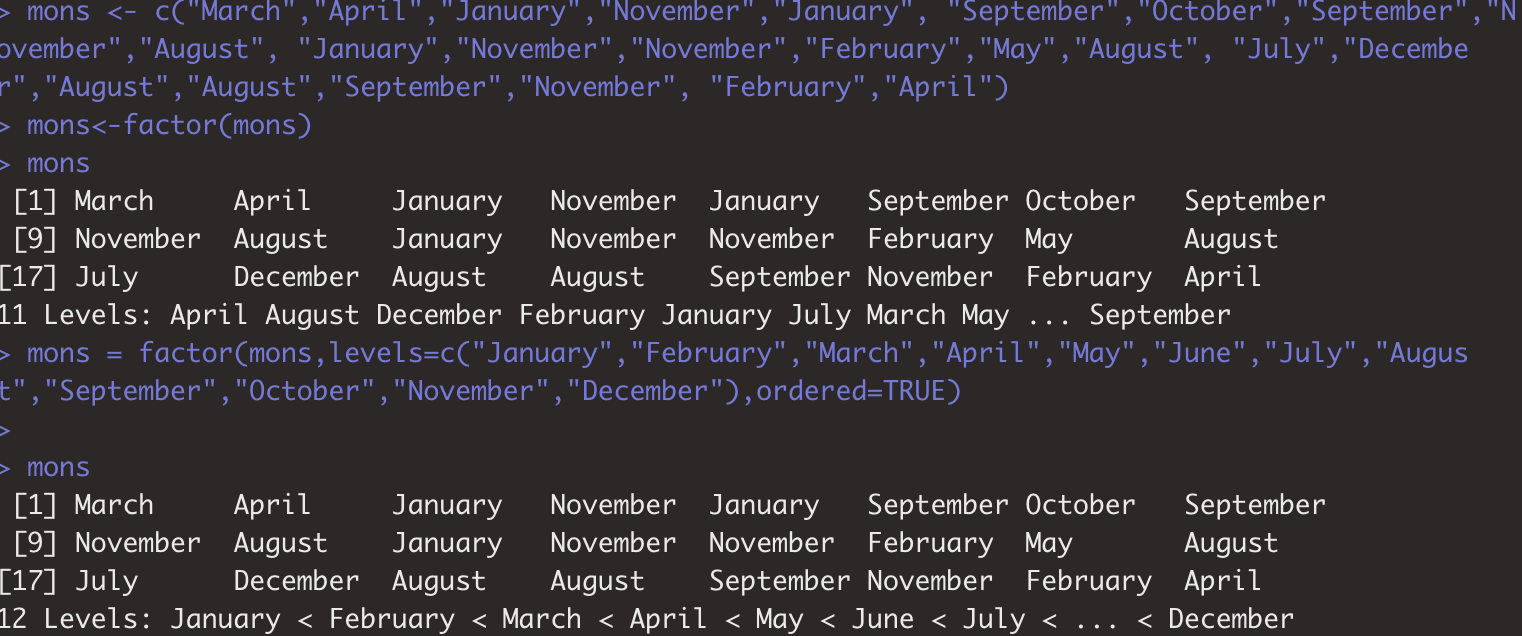
mons <- c("March","April","January","November","January", "September","October","September","November","August", "January","November","November","February","May","August", "July","December","August","August","September","November", "February","April")
mons<-factor(mons)
mons
mons = factor(mons,levels=c("January","February","March","April","May","June","July","August","September","October","November","December"),ordered=TRUE)
mons
table(mons)
?table()

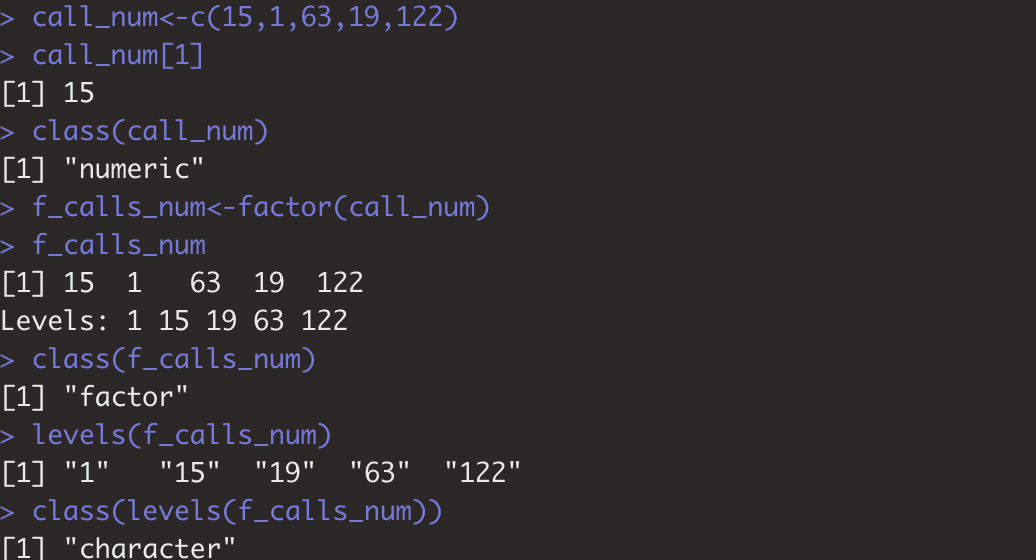
#factor()函数将原来的数值型的向量转化为factor类型。factor类型的向量有levels和labels的概念。Levels就是factor所有因素的集合(没有重复),Levels就是factor中元素排除重复后字符化的结果,levels元素都是character类型,可以在生成factor时,指定levels。
factor最大的作用是指定数据的顺序,即指定后边作图过程自变量的显示顺序。
Levels表示因子的值域。所以在指定了levels后,factor每个元素值只能取因子水平中的值或缺失。
创建因子用factor()函数创建因子型变量。factor(x=character(),levels,lables=levels) #默认的labels等于levels
还可以通过factor()修改level

可以通过factor()函数创建因子,factor(x=character(),levels,labels=levels,exclude=NA,orderd=is.ordered(x),nmax=NA)
x: 字符向量
levles: 水平,字符类型,用于设置x可能包含的唯一值,元素的集合,默认值是x的所有唯一值。 注:如果x不是字符向量,那么就会用as.character(x)转换为字符向量,然后取x向量的水平。x向量的取值与levels有关。levels顺序默认是向量的独特元素集合。通过设置levels 调整子图顺序。如
#jointcalling_GenotypeQC$maf=factor(jointcalling_GenotypeQC$maf,levels=c("All", "MAC=1","0-0.01","0.01-0.05","0.05-0.2","0.2-0.5")) glimpse(jointcalling_GenotypeQC) #ggboxplot(jointcalling_GenotypeQC,x="Steps",y="CONCORDANCE",color = "Steps",facet.by = "maf",bxp.errorbar = T,palette = "aaas")+stat_compare_means(aes(label = ..p.format..),label.x=1.4)
labels: 水平的标签,用于对每个因子水平添加标签,可以对因子水平levels重命名。顺序与levels顺序对应一致.
exludes: 排除的字符
ordered: 逻辑值,指定水平是否有序
nmax: 水平的上限数量
如 sex<-factor(c('f','m','f','f','m'),levels=c('f','m'))
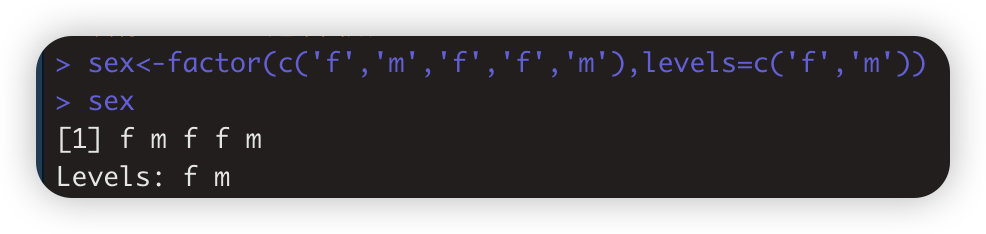
> levels(sex) #查看因子水平
[1] "f" "m"
> nlevels(sex) #查看level长度
[1] 2
> sex=factor(c('f','m','f','f','m'),levels=c('f','m'),labels=c('female','male'),ordered=TRUE) # 典型例子。

因子是无序的,因子的顺序实际指因子水平的顺序,有序因子的因子水平是有序的,即ordered=TRUE,默认值。

> factor(mtcars$cyl) #因为cyl列的levels是默认的按从小到大排序的独特集:4,6,8 对其对应的重赋值alpha beta gamma. 因此出来的值就是 beta..
[1] 6 6 4 6 8 6 8 4 4 6 6 8 8 8 8 8 8 4 4 4 4 8 8 8 8 4 4 4 8 6 8 4
Levels: 4 6 8
本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15629949.html
posted on 2021-12-01 17:25 BioinformaticsMaster 阅读(1165) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号