
apply函数对行/列运算
apply(X,MARGIN,FUN,...) 对矩阵、数据库、数组按行或列进行迭代计算,返回向量或数组或值列表。 apply系列函数有效替代R中比较慢的for循环。
X: 输入的数组、矩阵,如果是数据框会自动转换成矩阵
MARGIN:按行计算或按列计算,1表示按行,2表示按列。
FUN:调用的函数
...: 可选项,为函数FUN提供额外参数。即如果一个函数有多个参数,那么...就是传入除第一个参数意外的其他参数。
例子:
df<-data.frame(x=c("A","B","C","A","C"),'2010'=c(1,3,4,4,3),'2011'=c(3,5,2,8,9),check.names=FALSE)
df_rowsum<-apply(df[,2:3],1,sum) #对2、3列,采用按行计算。
df_colsum<-apply(df[,2:3],2,sum) # 采用按列计算



给apply的调用函数传参的情形如apply(counts,2,max,na.rm=TRUE)
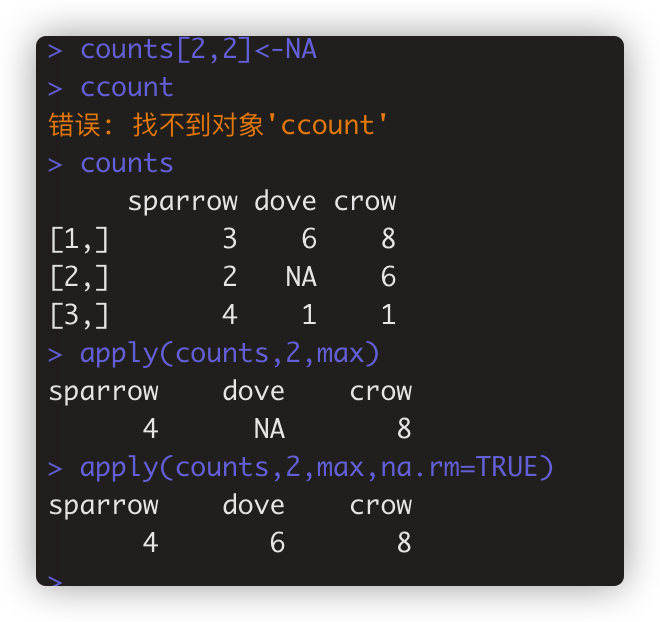
> sapply(X,FUN,...,simplify=TRUE,USE.NAMES=TRUE)
X 向量
FUN 调用函数
simplify 是否简化输出格式
例子: sapply(iris, mean) # 出现 Warining,是因为Species不是数值列。
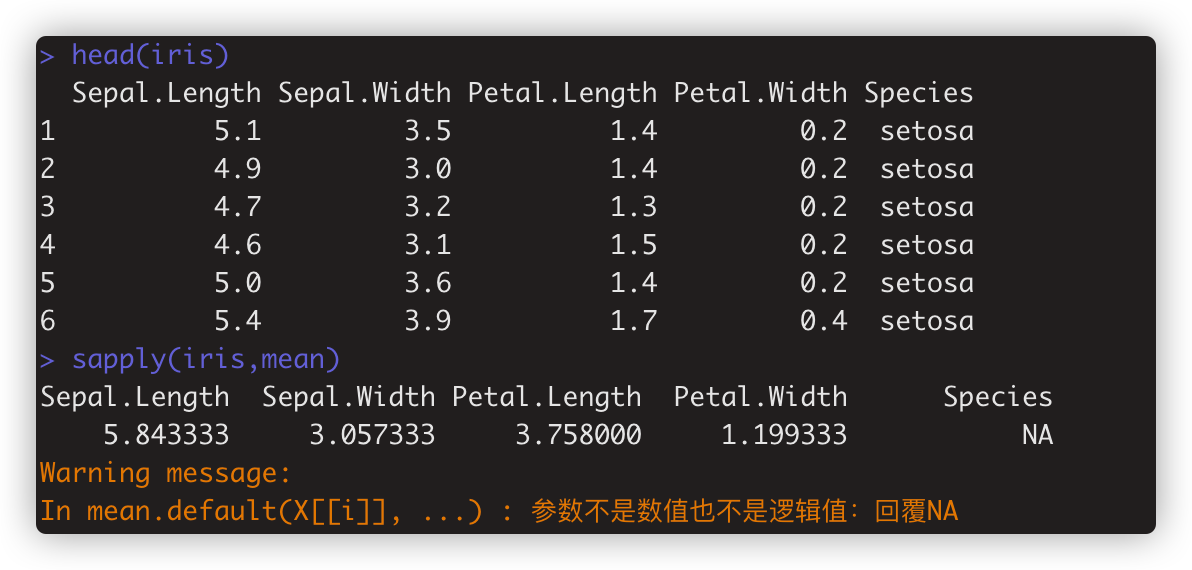
解决方案是判断列的数据类型 sapply(iris, function(x) ifelse(is.numeric(x),mean(x),NA)) # function(x) ifelse(is.numeric(x),mean(x),NA) 是匿名函数

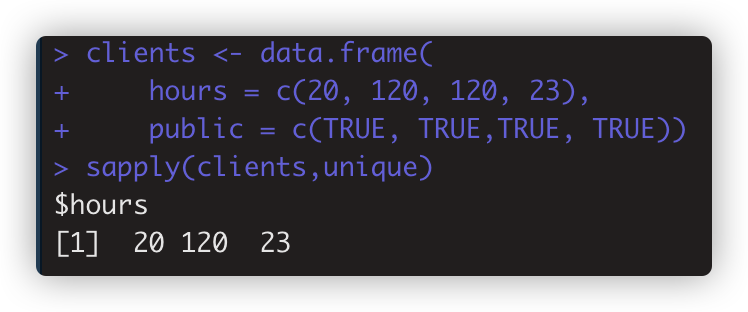
例子2. 对数据框的每列计算
> clients <- data.frame( hours = c(20, 120, 120, 23), +public = c(TRUE, TRUE,TRUE, TRUE))
> sapply(clients,unique)
》 lapply 中l表示list(列表). sapply()是lapply的simplify简化方式。
lapply(X,FUN,...) , 作用对象x是list列表, 返回值也是list列表
例1 lapply(x,mean) 注:x是列表
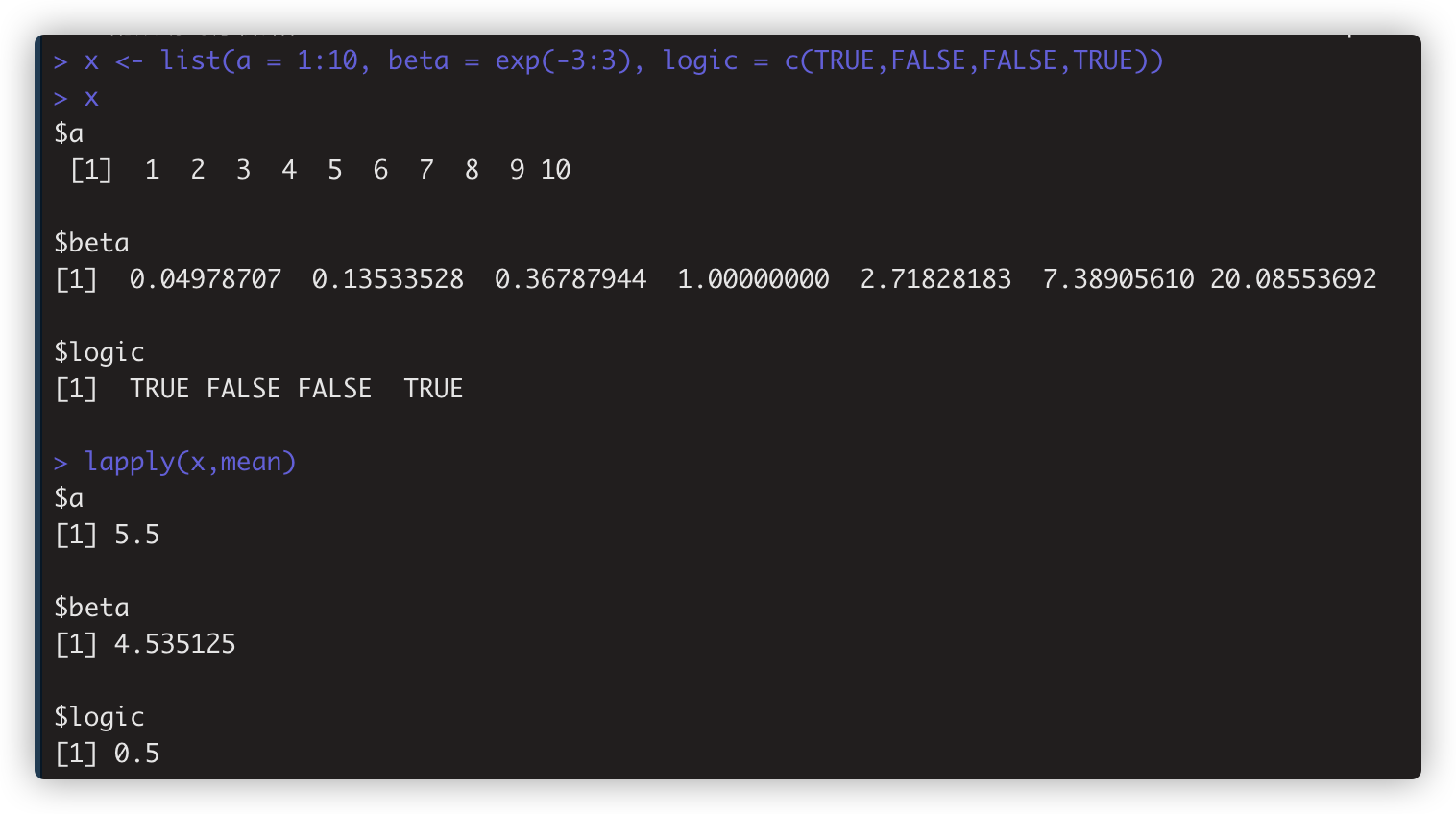
例2 sapply是lapply的简化格式
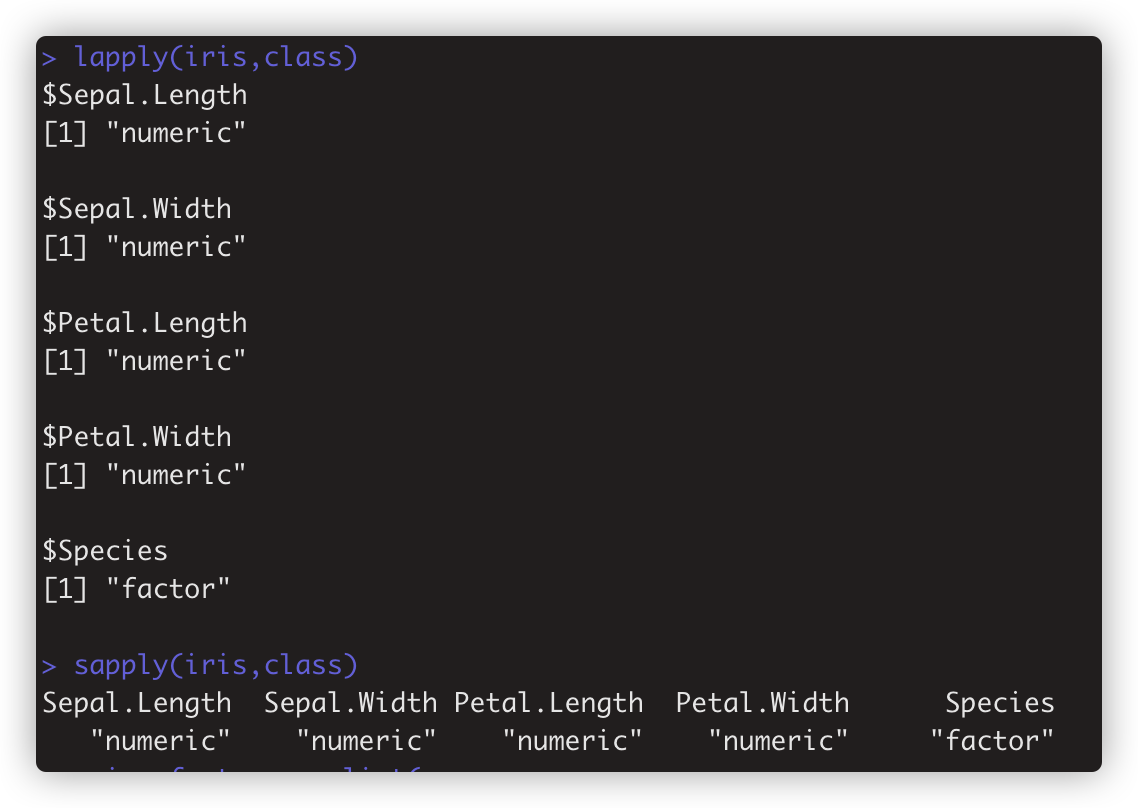
例3 再次说明apply做的事是代替for循环。如
测试数据集
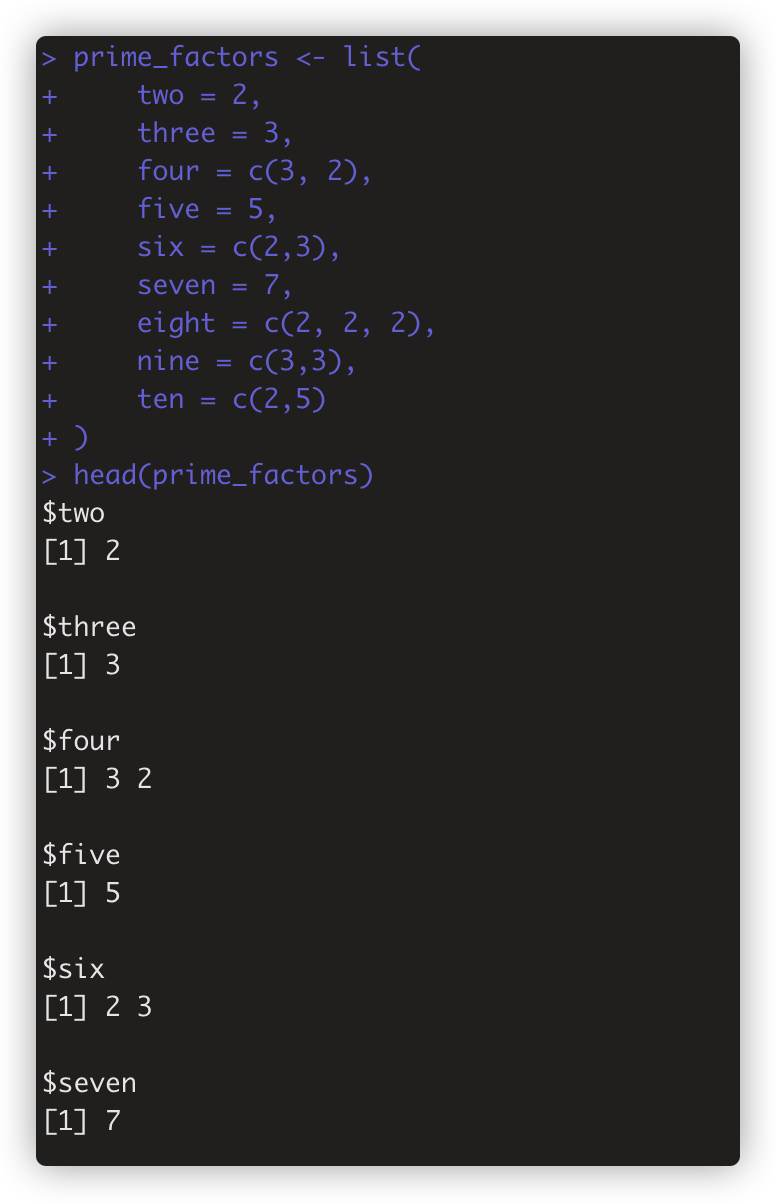
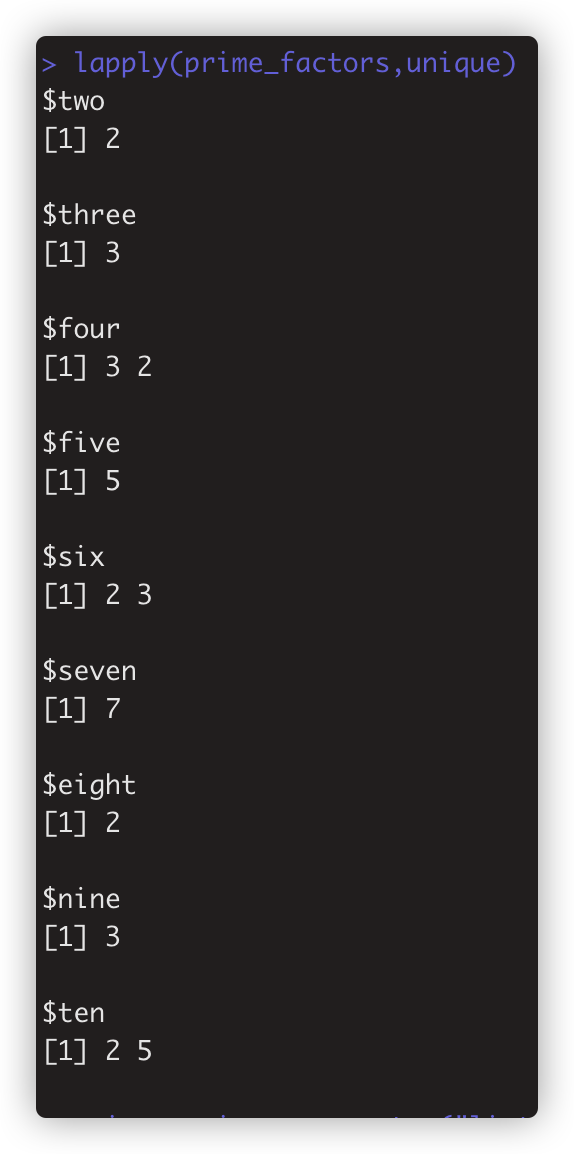
lapply 写法 > lapply(prime_factors,unique)
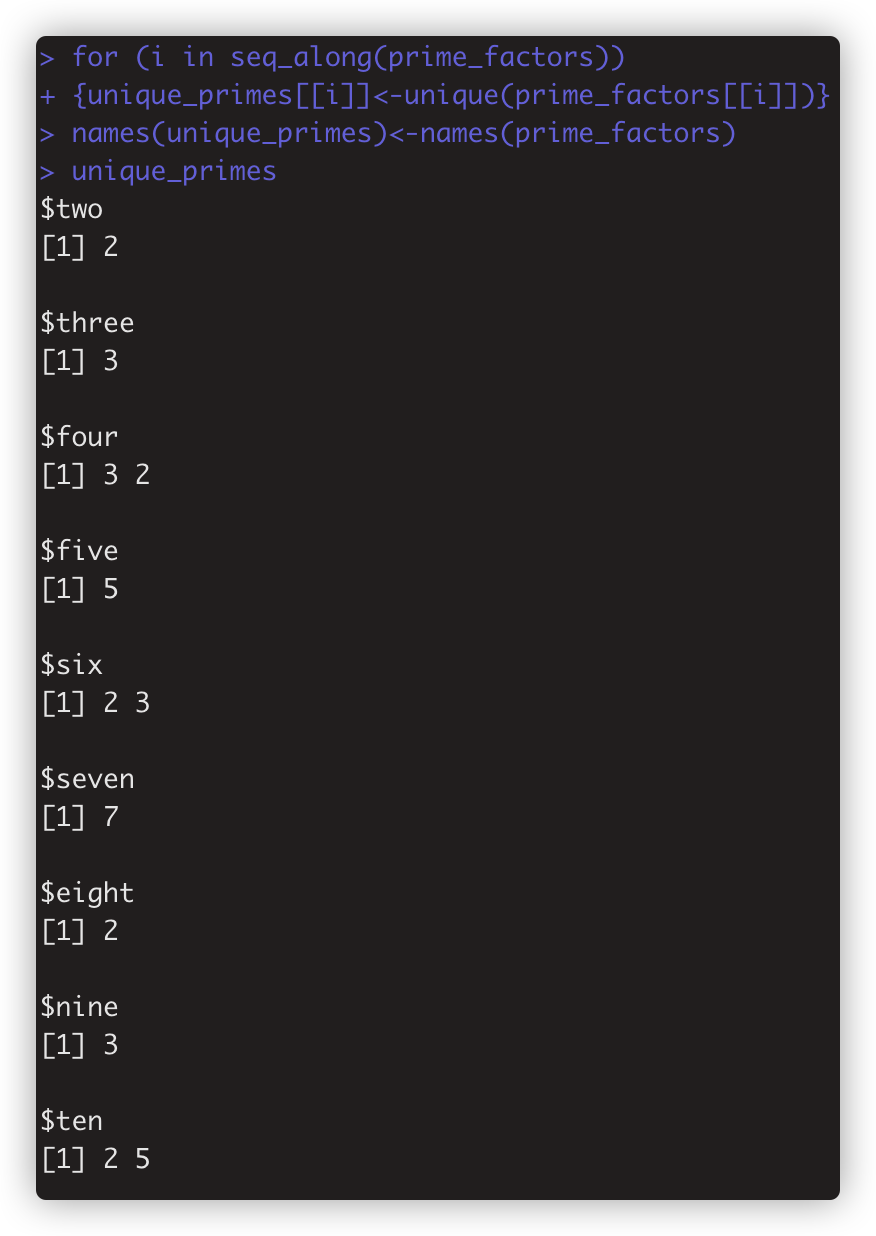
for循环写法 for (i in seq_along(prime_factors))
{unique_primes[[i]]<-unique(prime_factors[[i]])}
names(unique_primes)<-names(prime_factors)
unique_primes
两个写法效果一样
例4。lapply 调用函数传不同数量的参数
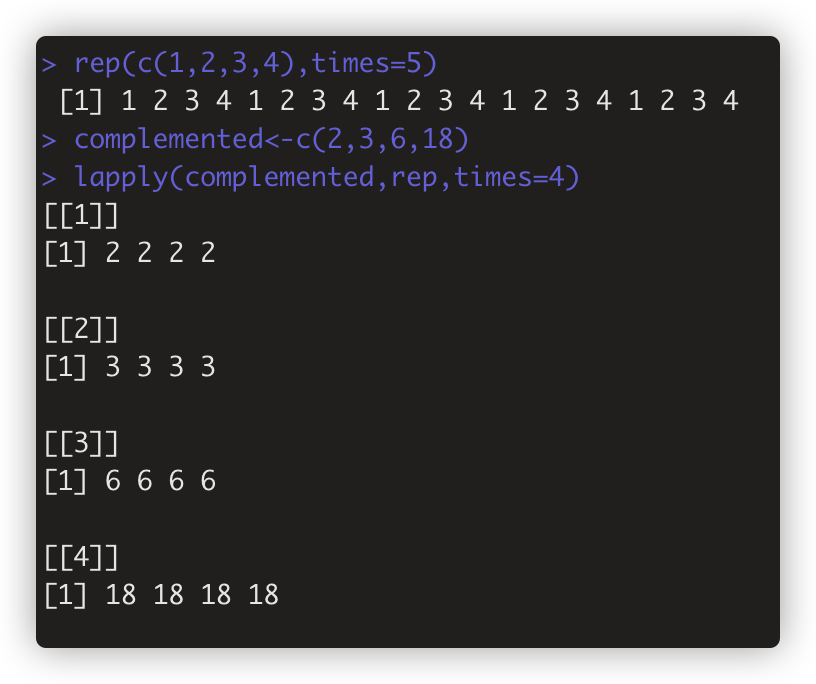
4.1 函数定义第一个参数是向量,第二个参数是标量。此时可以直接作为参数传入。如 rep(c(1,2,3,4),times=5) 这种的,可以> lapply(complemented,rep,times=4)
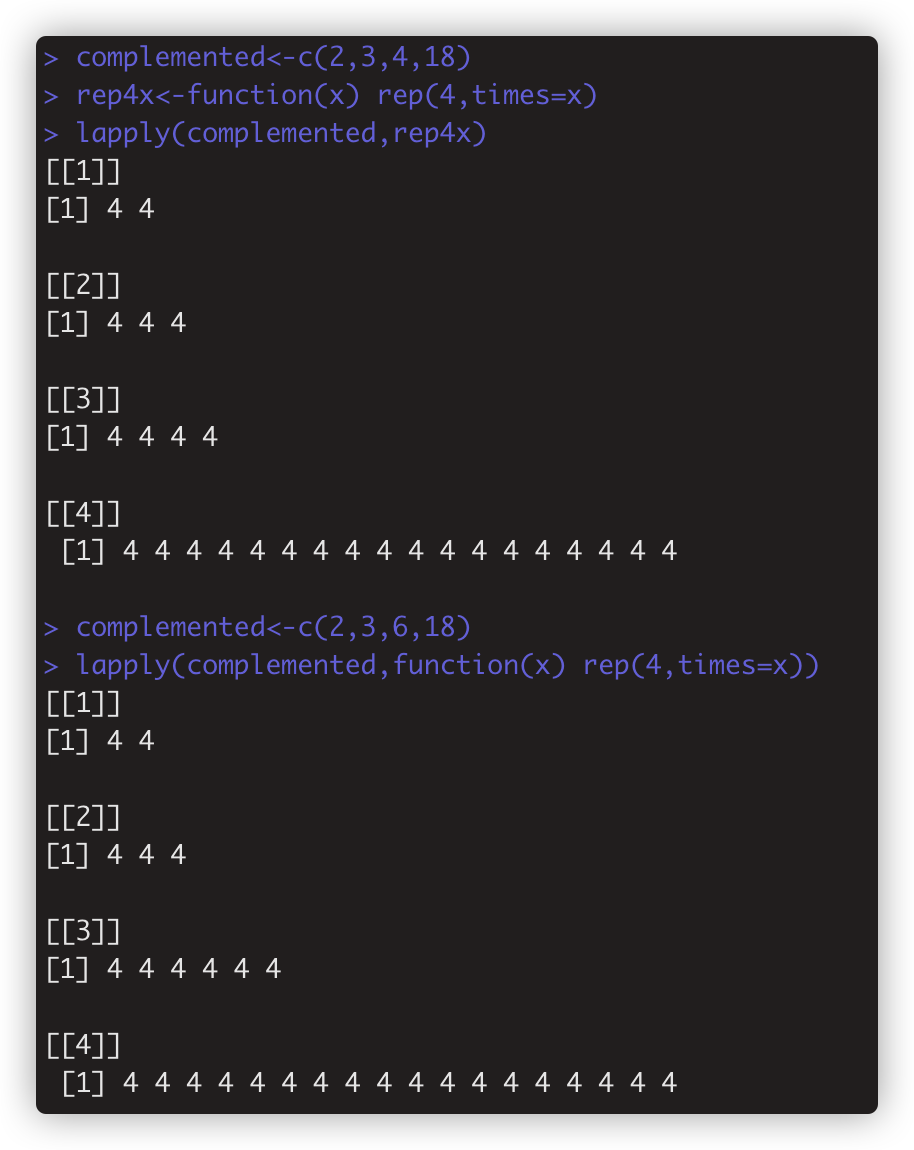
4.2 更泛适合的是定义一个函数封装一下,如rep4x<-function(x) rep(4,times=x),再lapply(complemented,rep4x),
还可以写匿名函数来较简单的实现如lapply(complemented,function(x) rep(4,times=x))
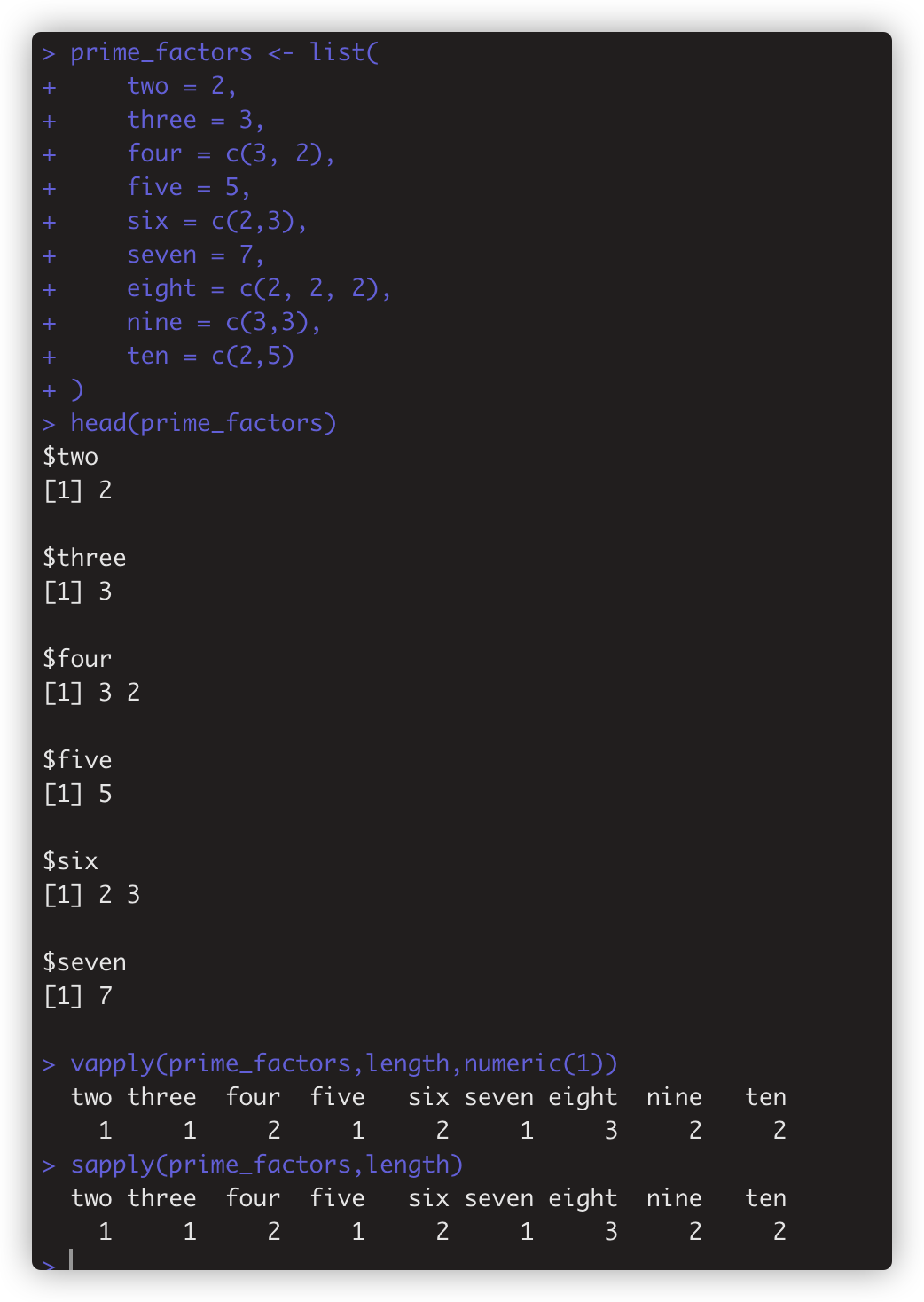
》vapply 应用于列表返回向量vector,输入参数: 列表,调用函数,返回值模版. 如 vapply(prime_factors,length,numeric(1)) 感觉不如 sapply(prime_factors,length) 简练
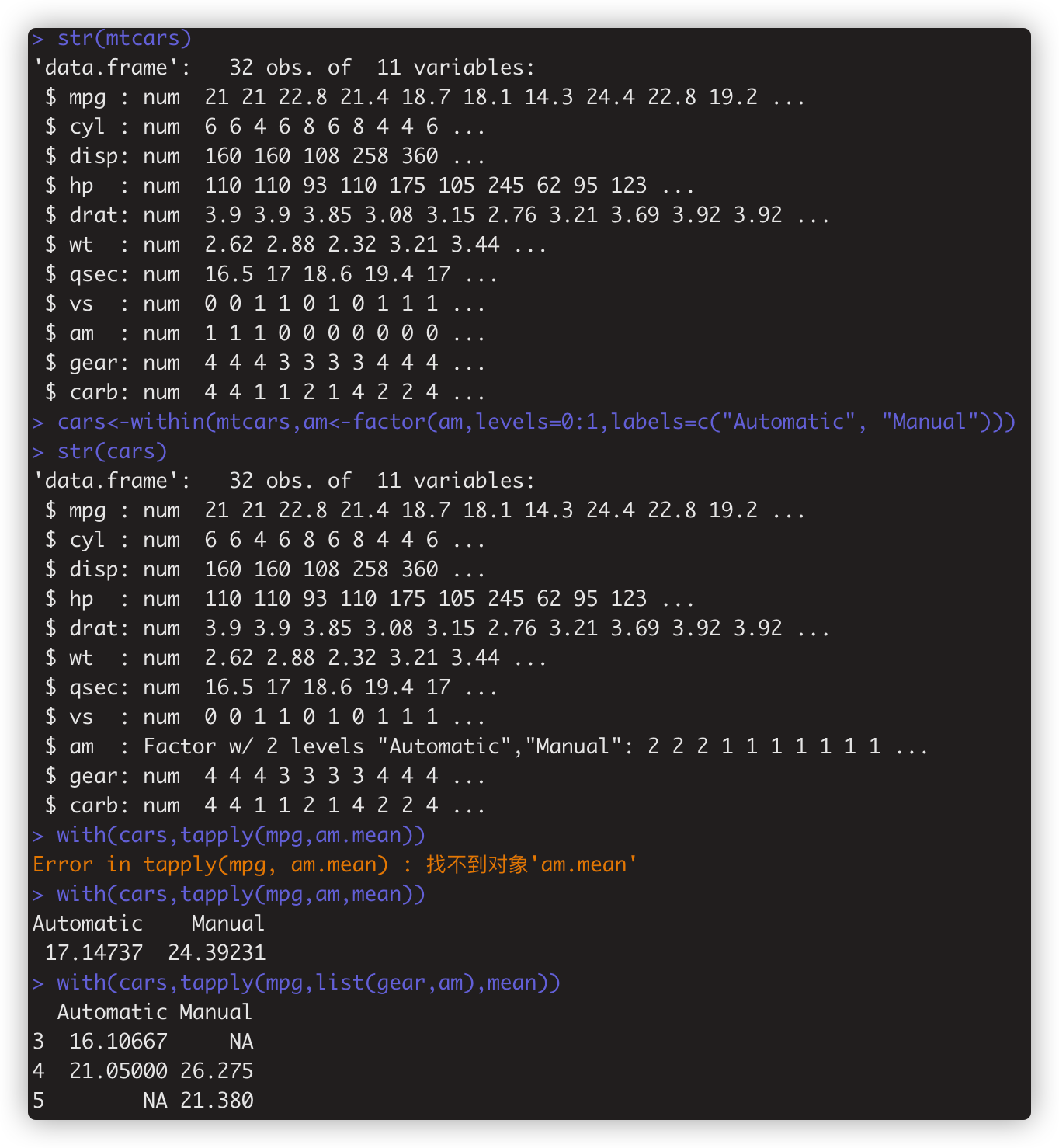
》tapply()函数 常用于处理因子类型数据,t指table. 逻辑如下:
1. 将数据成组,每组对应一个因子水平(或在多重因子的情况下对应一组因子水平的组合)
2. 对每组数据 调用函数
例子1: tapply(iris$Sepal.Length,iris$Species,mean) # 把iris$Sepal.Length 按iris$Species分组,然后计算每组的平均值

例2: with(cars,tapply(mpg,list(gear,am),mean))
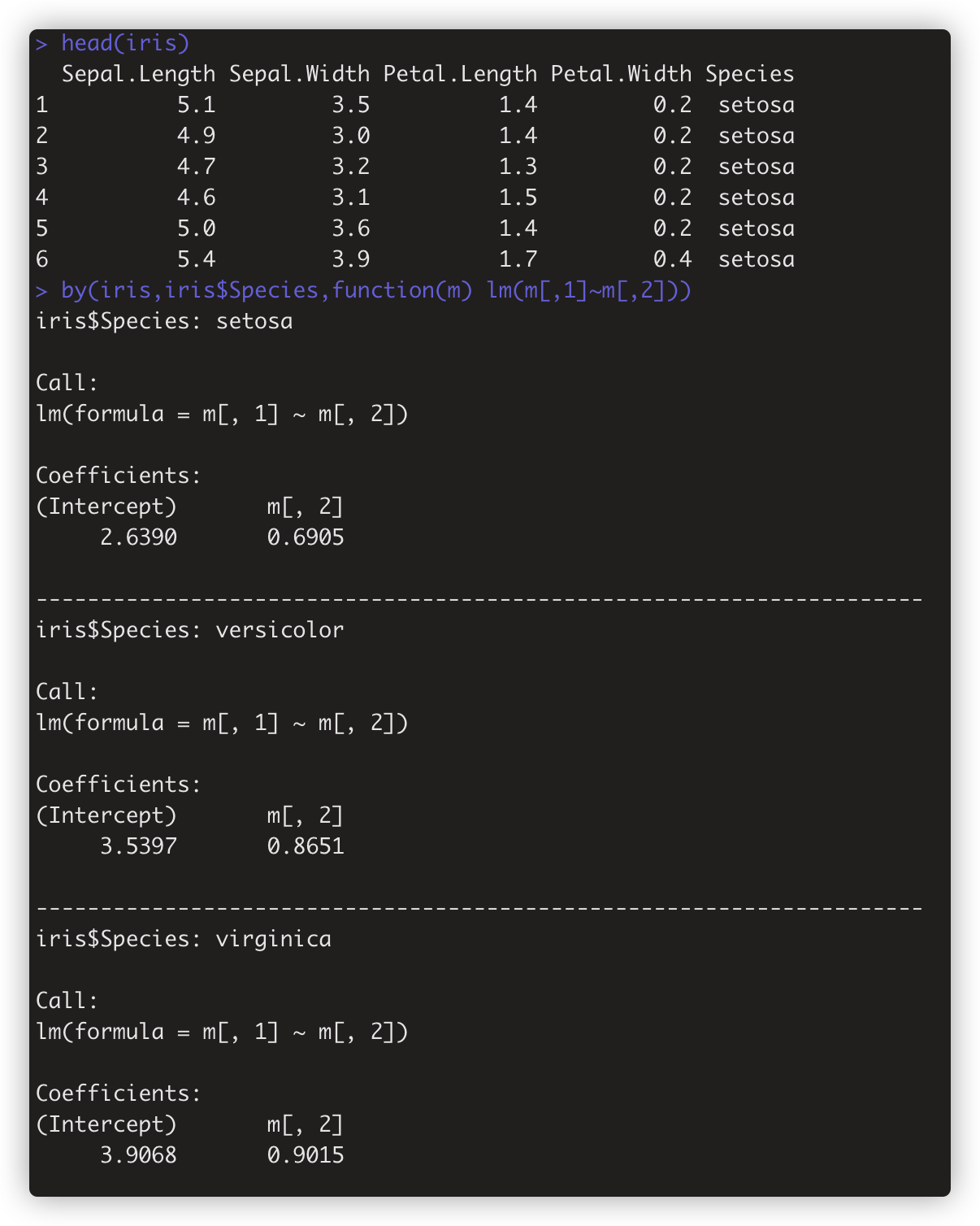
》by()函数 类似tapply, 但by()可以应用于矩阵或数据框,而tapply只能用于向量(第一个参数)。
by()函数,输入参数: 数据集,分组因子,调用函数 . 如 > by(iris,iris$Species,function(m) lm(m[,1]~m[,2]))
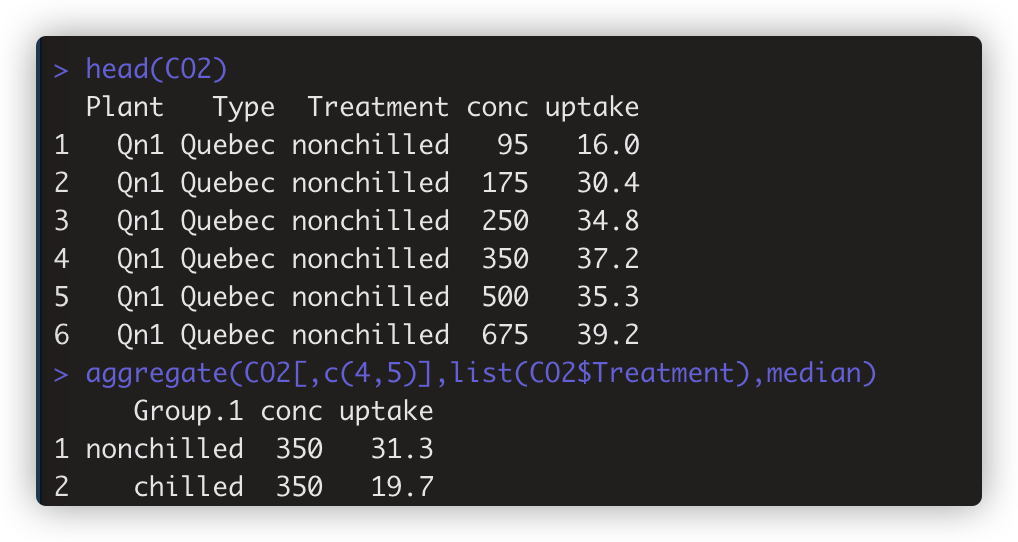
》aggregate()函数对分组中的每个变量应用tapply()函数,如aggregate(CO2[,c(4,5)],list(CO2$Treatment),median)
备注: switch(expr,list) 。如果expr计算结果为整数,且值在1~length(list)之间,则switch函数返回列表对应位置的值,否则没返回值或返回NULL
expr是表达式,值为整数值或字符串
list 列表
如果switch返回字符串,则查找相应变量如> switch("c",a="weizhi1",b="weizhi2",c="weizhi3")

更多的apply函数家族参考:http://showteeth.tech/posts/15576.html
对数据框分组计算,用aggregate函数,~左边表示待操作变量,~右边表示依据。注:依据可以是一个或多个。
例子:
df_melt<-reshape2::melt(df,id.var="x",variable.name="year",value.name="value")
> da_group1<-aggregate(value~year,df_melt,mean) # 数据框df_melt,按year对变量value执行mean计算。
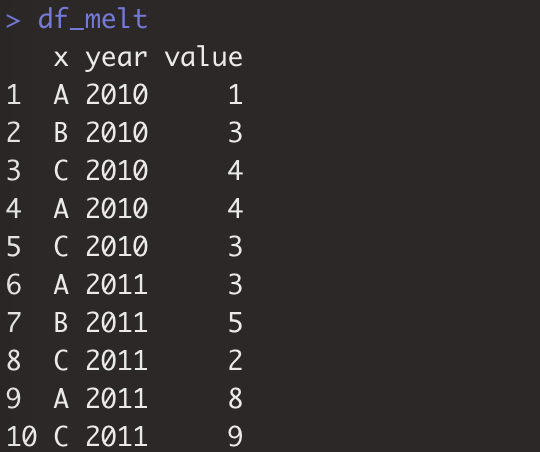

~右边是多个时,则是右边这些变量不同组合情况下的函数操作。
如:> df_group2<-aggregate(value~year+x,df_melt,mean)

~ 左边是多个变量,表示待操作的是多个变量,这些变量分别依据~右侧变量进行函数操作。
如> df_group3<-aggregate(cbind(value,year)~x,df_melt,mean)

对数据框分组计算与aggregate类似但更灵活的是通过dplyr包的groupby()分组,summarise()分组的汇总运算,arrange()分组的变量排序等组合实现与aggregate()类似功能。
常需要搭配%>%这个多步操作连接符。注:groupyby()常和summarise()搭配使用,后者需要前者分组功能。
例子:
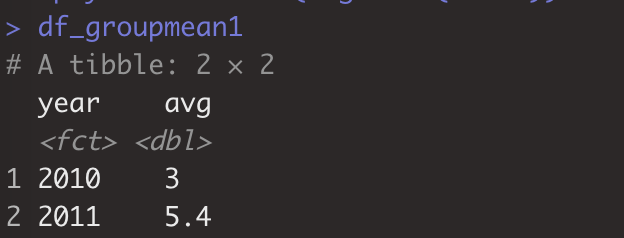
> df_groupmean1<-df_melt%>%dplyr::group_by(year)%>% + dplyr::summarise(avg=mean(value)) #与aggregate(value~year,df_melt,mean)效果一致。
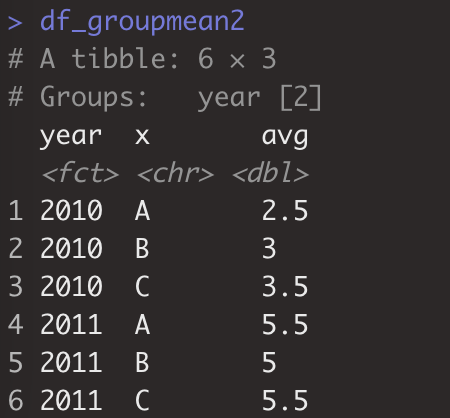
> df_groupmean2<-df_melt%>%dplyr::group_by(year,x)%>%dplyr::summarise(avg=mean(value))#与aggregate(value~year+x,df_melt,mean)效果一致。
本文来自博客园,作者:BioinformaticsMaster,转载请注明原文链接:https://www.cnblogs.com/koujiaodahan/p/15359555.html
posted on 2021-10-01 16:07 BioinformaticsMaster 阅读(824) 评论(0) 编辑 收藏 举报

