BERT详解--慢慢来
BERT的理解需要分为三个部分:
- Attention
- Transformer
- BERT
所以本文从这三个步骤,BERT详解慢慢来
Attention
(学习自:https://edu.csdn.net/course/play/27575/370647?spm=1002.2009.3001.4024)
RNN类模型的机制,决定了RNN类模型的输出必然小于等于其输入的参数
比如输入4个词,经过翻译模型之后,最多得到4个词
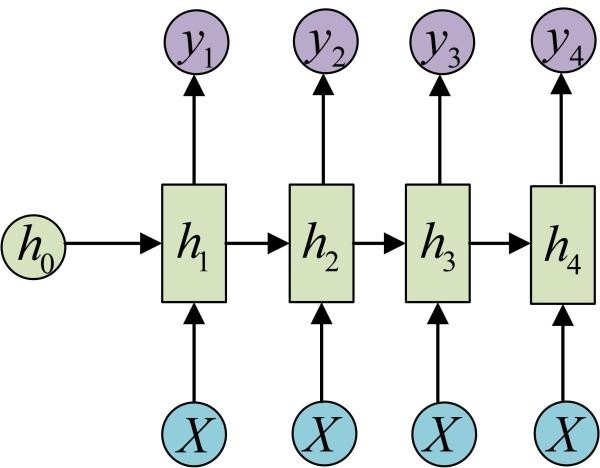
因此,为了解决这样的问题,
衍生出了Encoder-Decoder的方法
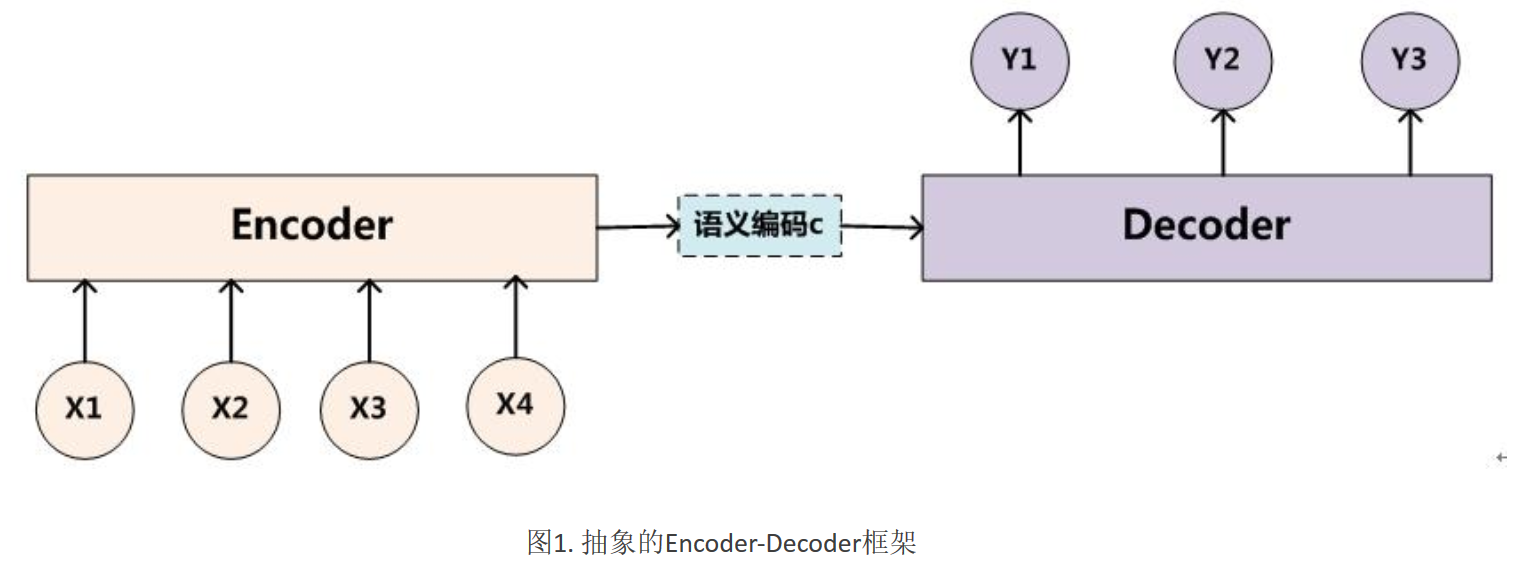
通过encoder对输入进行编码,成为一个隐向量,再对隐向量进行解码,指定想要输出的维度
就不会受到输入维度的限制了
很显然,该方法的问题非常的明显,当句子长度过长的时候
句子的信息会在编码的过程中损失掉很多
导致在解码中无法还原
由此,诞生了注意力机制,细化了还原语义的过程
(注意力机制学习自:
1.https://zhuanlan.zhihu.com/p/47063917,
2.https://www.cnblogs.com/Libo-Master/p/7884958.html)
Decoder驱动的Attention
还是以带有Decoder的模型为例,
为了使得中间隐层向量的解码带有注意力,而不是一视同仁地统一解码,
所以需要某种计算机制来生成一种记录训练过程中语义倾向的值,如图中所示的效果:

(1) 利用RNN得到隐状态
(2) 计算当前位置的输入与隐状态的关联性(点乘,加权点乘等方法均可)
(3) 隐层加权求和
详细带公式总结请点击本链接看原博(本博客分享物理意义抽象理解)
这样的操作,会使得:
当前输出位置得到比较重要的输入位置的权重,在预测输出时相应的会占较大的比重
就和人一样,会集中注意力去关注想关注的东西了。
当然,单纯的去理解公式,可能还是比较抽象,
结合第二篇博客
以Tom chase Jerry为例子:
假如不使用注意力机制,究竟是Jerry还是Tom该被翻译成杰瑞,会没有一个明显的倾向
通过注意力机制输出之后会得到下面类似的输出:
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小
原博里对其中的计算有较为清楚的描述,实际就是一个累加的计算,但是却取得了很好的效果
对于每一个单词,在翻译成对应的文字时,都会有一个对应的注意力进行指导,使得效果大大提升
Self Attention
既然Attention机制这么好用,那可不可以直接去掉RNN的Decoder使用Attention呢?
答案是肯定的, 本节学习自:https://zhuanlan.zhihu.com/p/48508221
Self Attention就是这么一个机制,由他继而衍生了transformer和BERT
先上公式:
(1) 初始化QKV矩阵
开始的时候,每个单词都会生成3个向量QKV
这三个向量都是长度为64的向量(例子与transformer的例子契合方便说明问题)
其中X是单词的word embedding形式长度为512,可以来自于word2vec,
W_{*}是512 * 64的权重矩阵,
\((1, 512)*(512, 64) = (1, 64)\)
应用上述的公式就能初始化出QKV长度为64
(2) 计算score分数
(3) 归一化+softmax
(4) 融合底层的特征信息
QKV均是通过原始的word embedding形式的X得到的,相当于底层的信息
通过矩阵的乘法,能够把需要增强的注意力,进一步增大
具体方法如下公式:
(5)shortcut结构
因为计算的深度增加了,会有梯度问题出现
也就是深度学习中的退化问题
所以在Self Attention中加入了shortcut的结构进一步解决这些问题
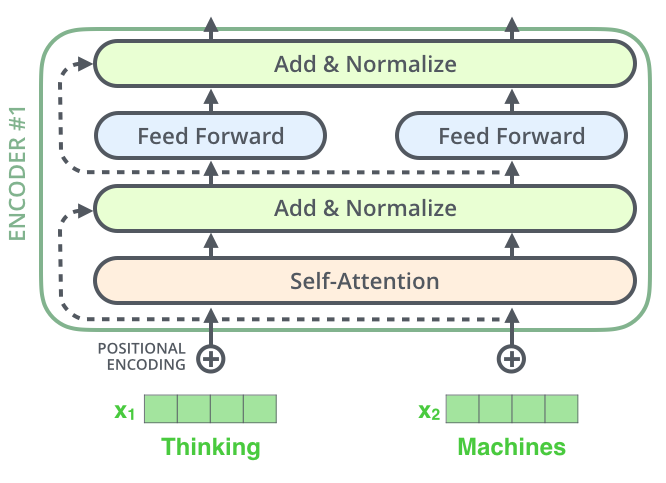
Transformer
理解了上面说的self attention的话,transformer就比较好理解了
本节内容学习自:http://jalammar.github.io/illustrated-transformer/
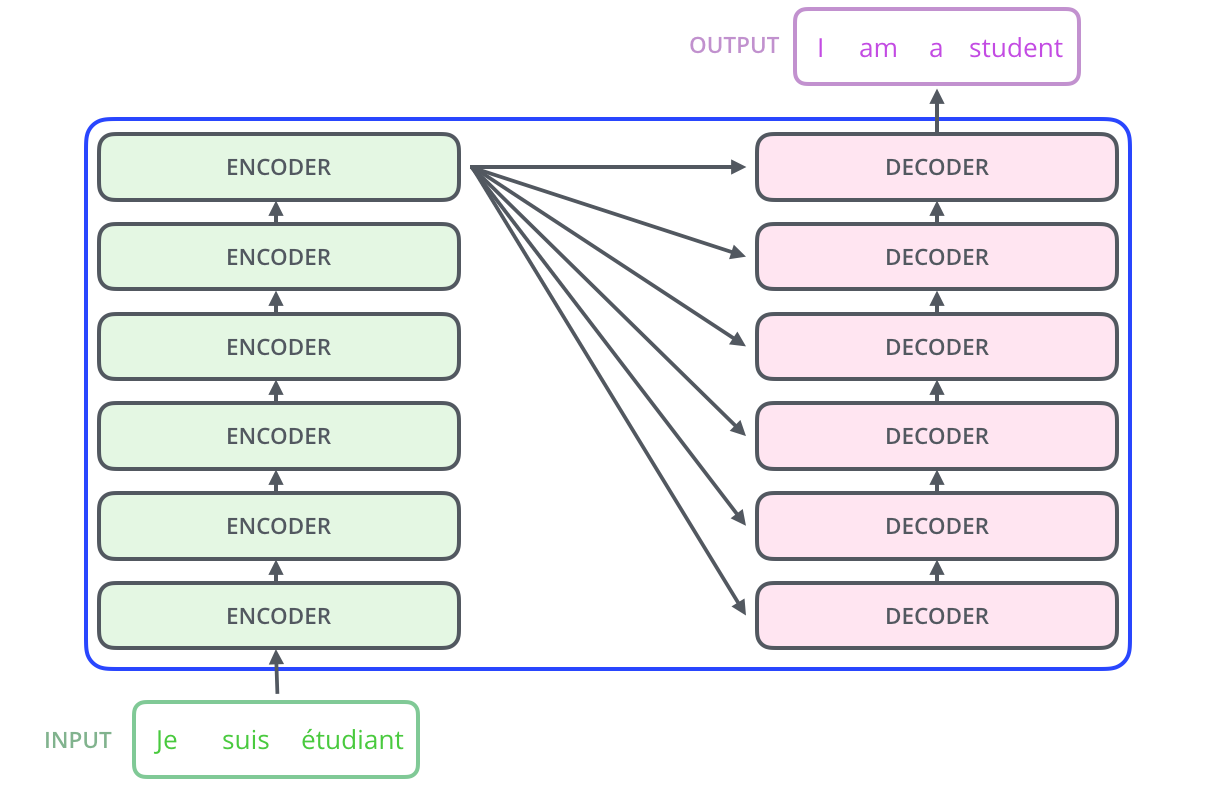
整个transformer由6个encoder和6个decoder组成,图中是以机器翻译为任务来说明工作原理
Transformer的本质上是一个Encoder-Decoder的结构
encoder
每一个encoder的结构如下图所示:
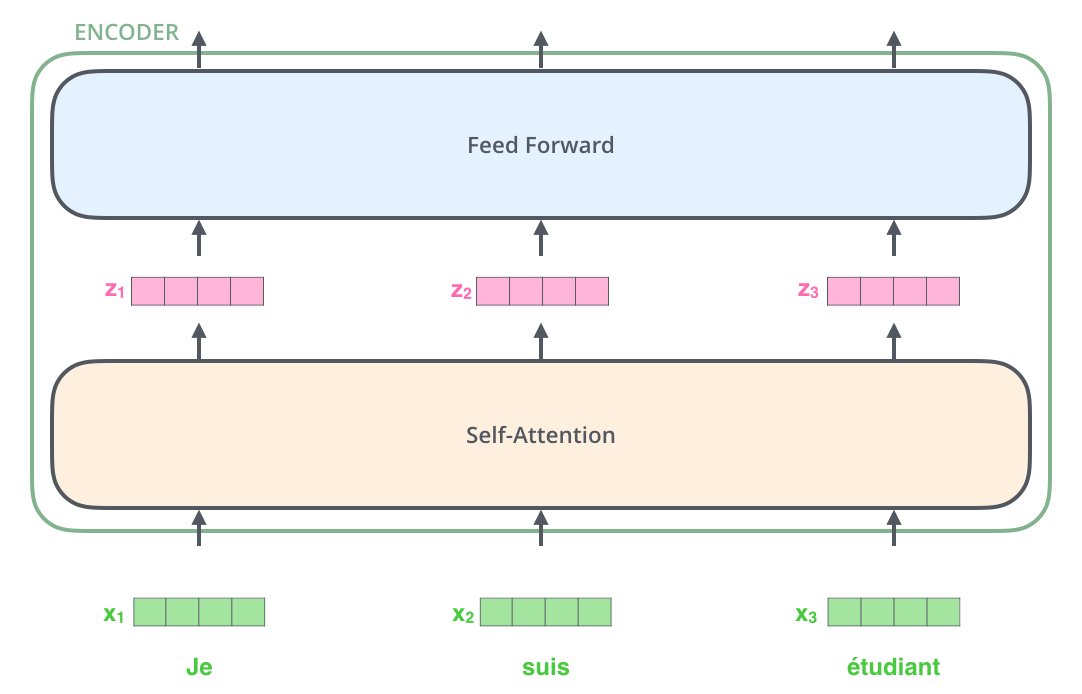
可以清晰的看到,encoder模块是由self attention加上feedforward nerual network(FFNN)组成的
- Multi-head attention
self attention已经在上一节介绍过了
为了提升精度和效率,这里还使用了Multi-head attention
他是n个self attention的ensembling,模块的结构如下图所示:
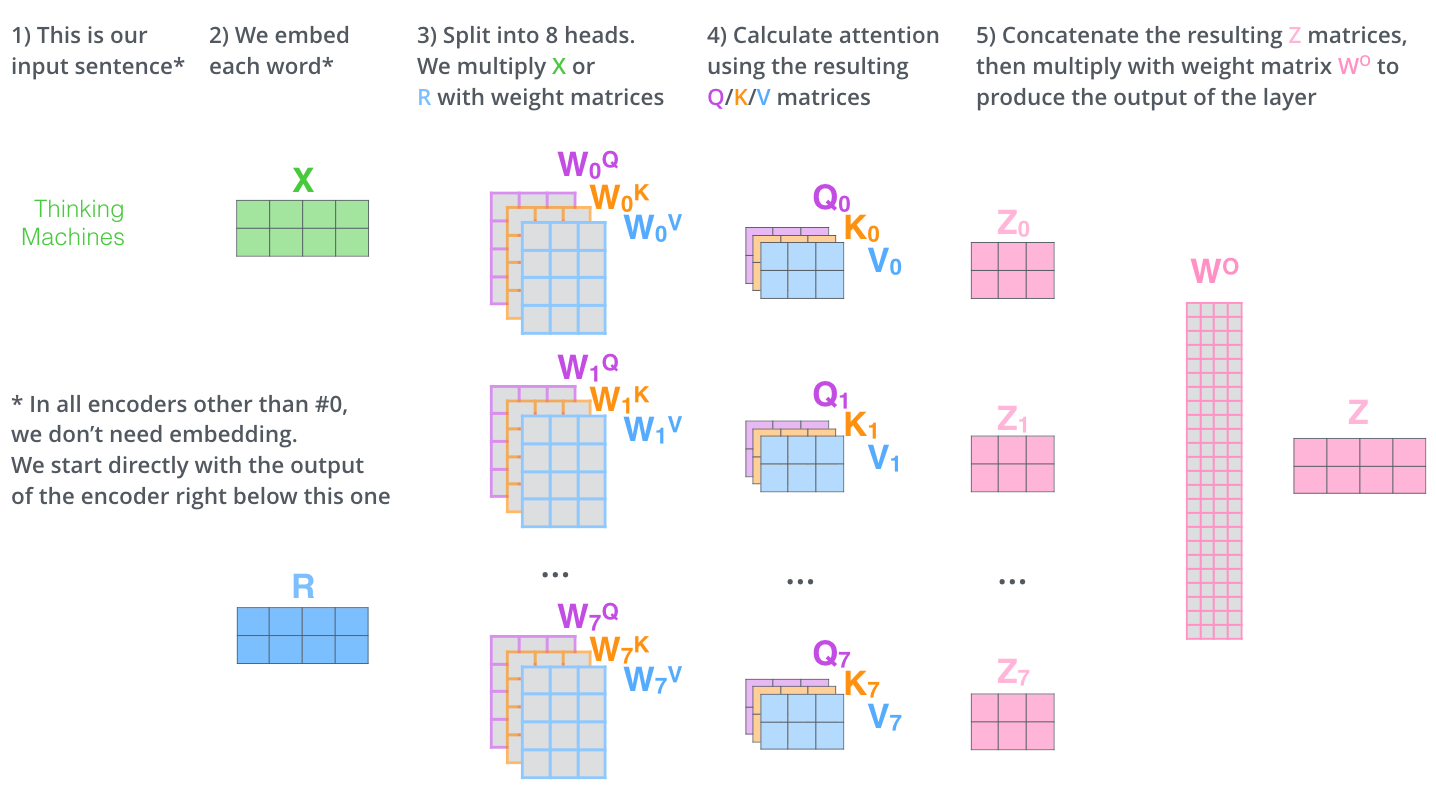
图中是以8个self attention为例说明的,
将8个注意力concatenate在一起组成多头注意力机制 - FFNN
FFNN模块由一个Relu和一个线性激活组成,公式如下:
相当于做了一个后接的映射激活
decoder
- encoder-decoder attention
用到的策略的名称叫做encoder-decoder attention,
用原博中的两个gif就能解释,首先通过最末尾的一个encoder保留KV,初始化Q得到decoder的第一个输出
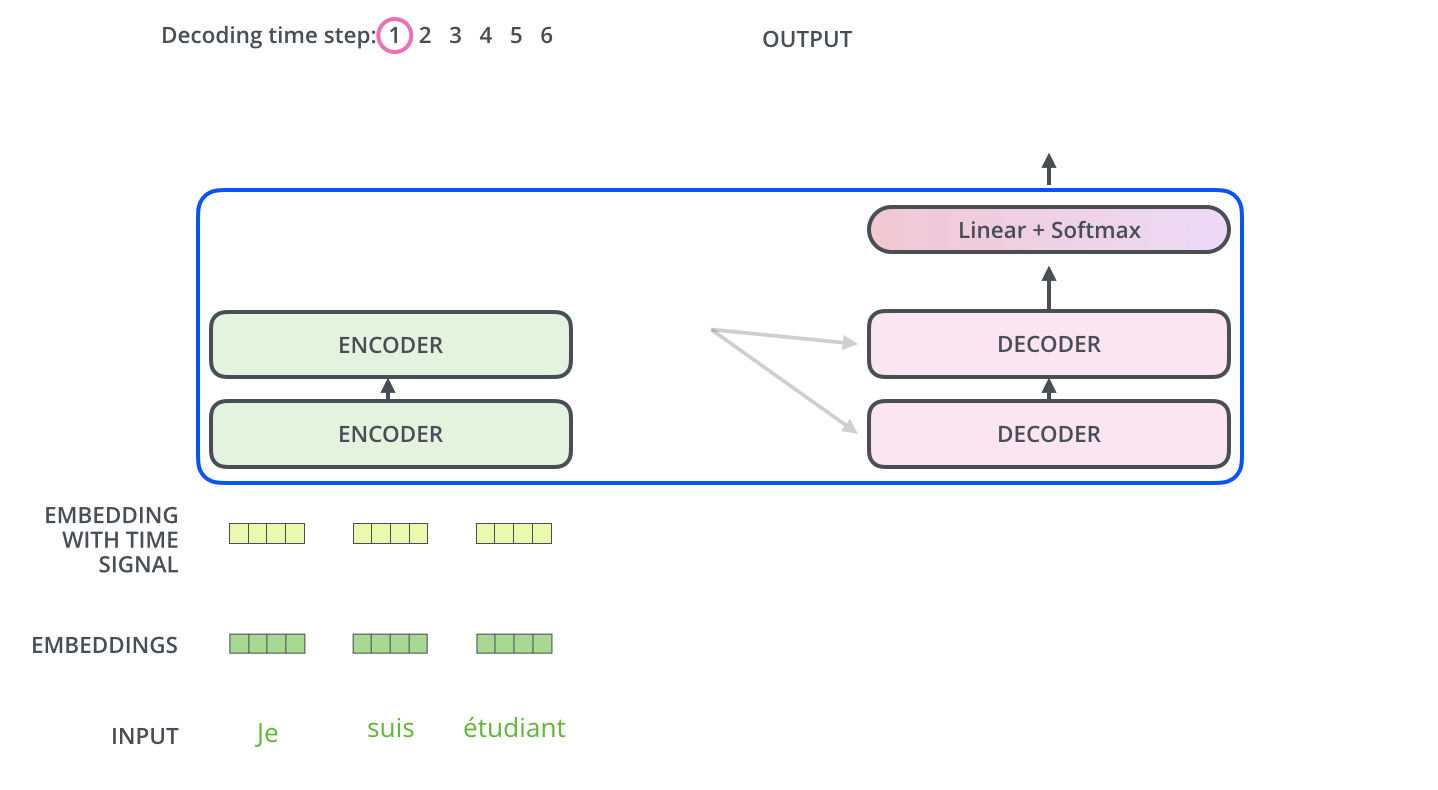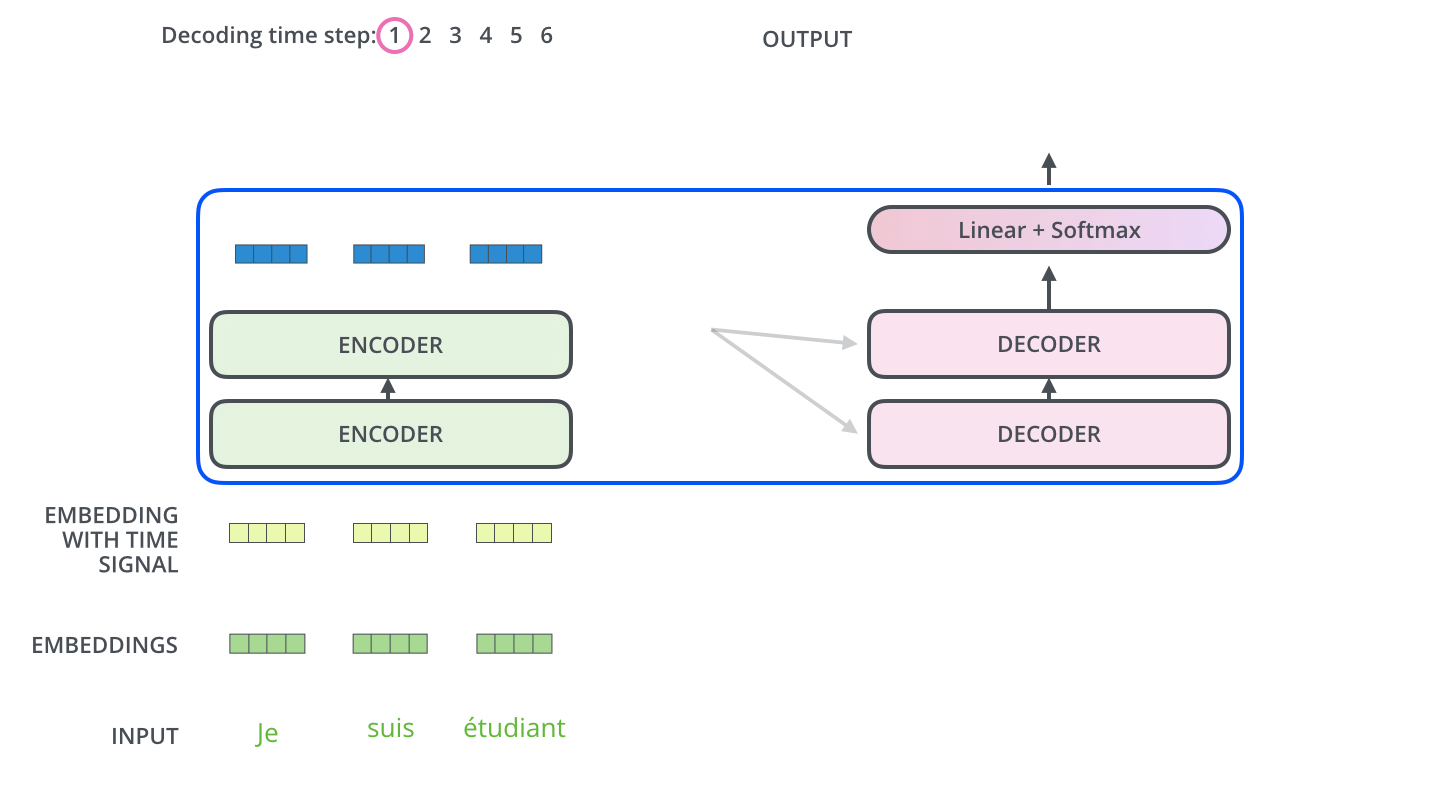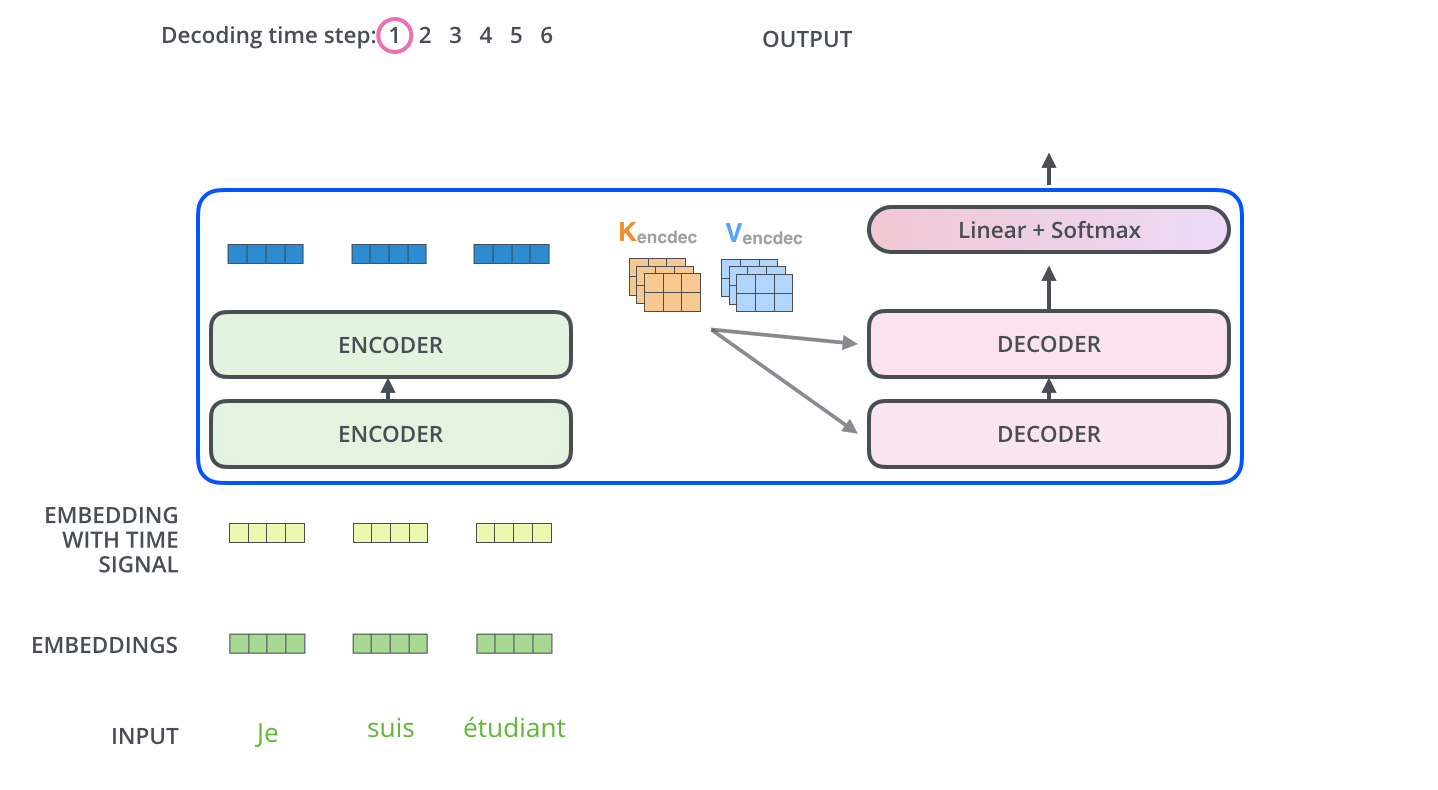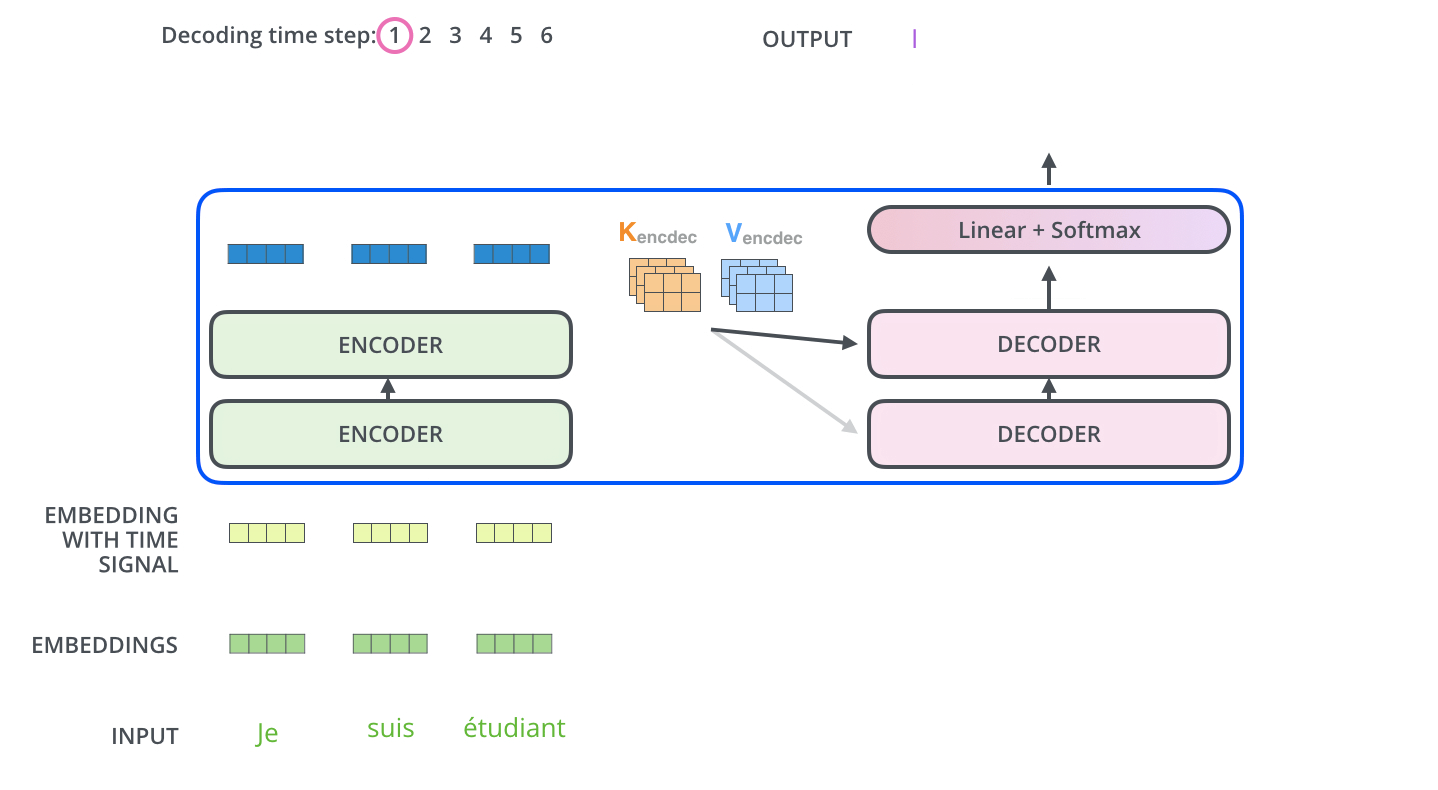
图示中的I就是decoder的第一个输出,
接下来这个输出当做下一个decoder的Q,然后再获取之前的encoder的KV,继续做self attention
如下图所示
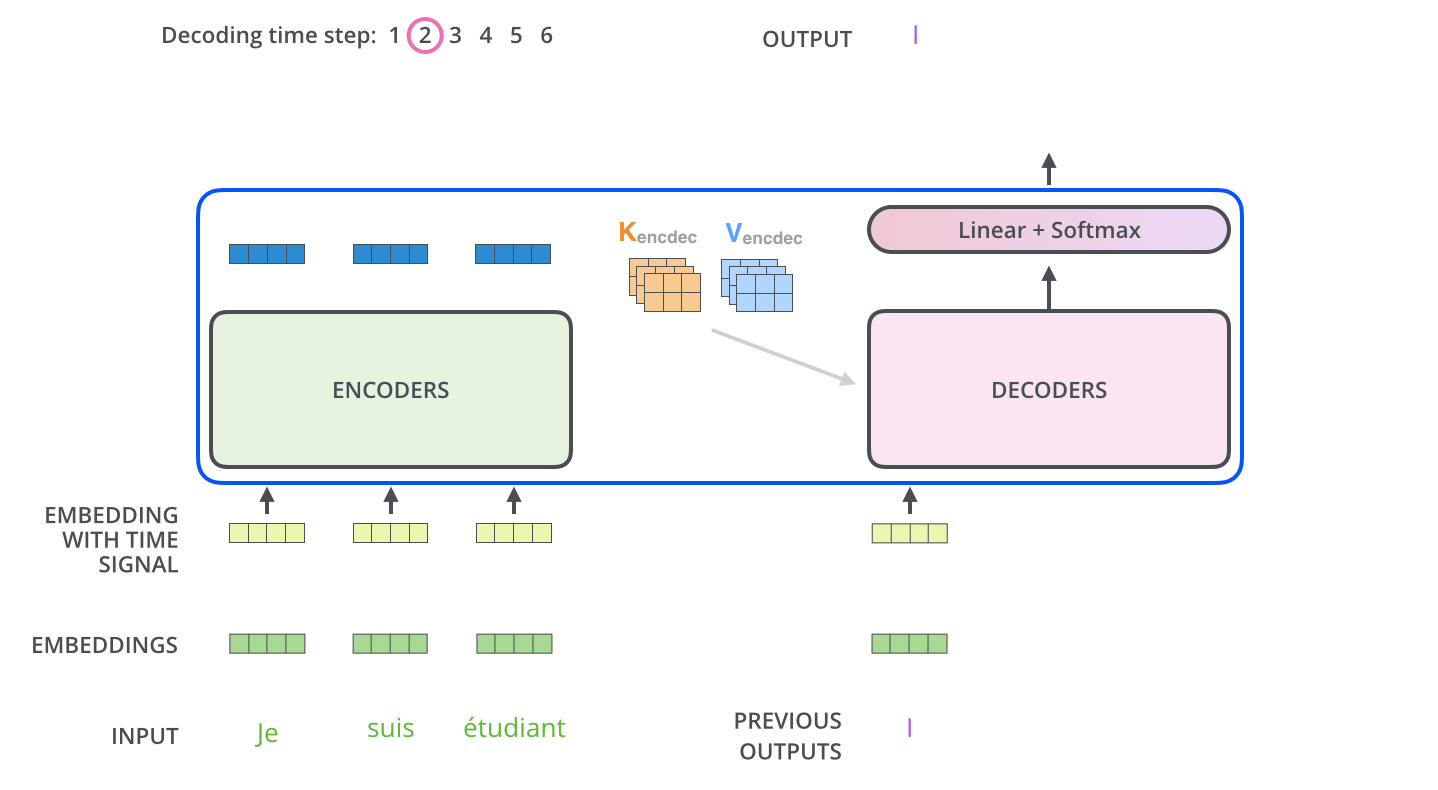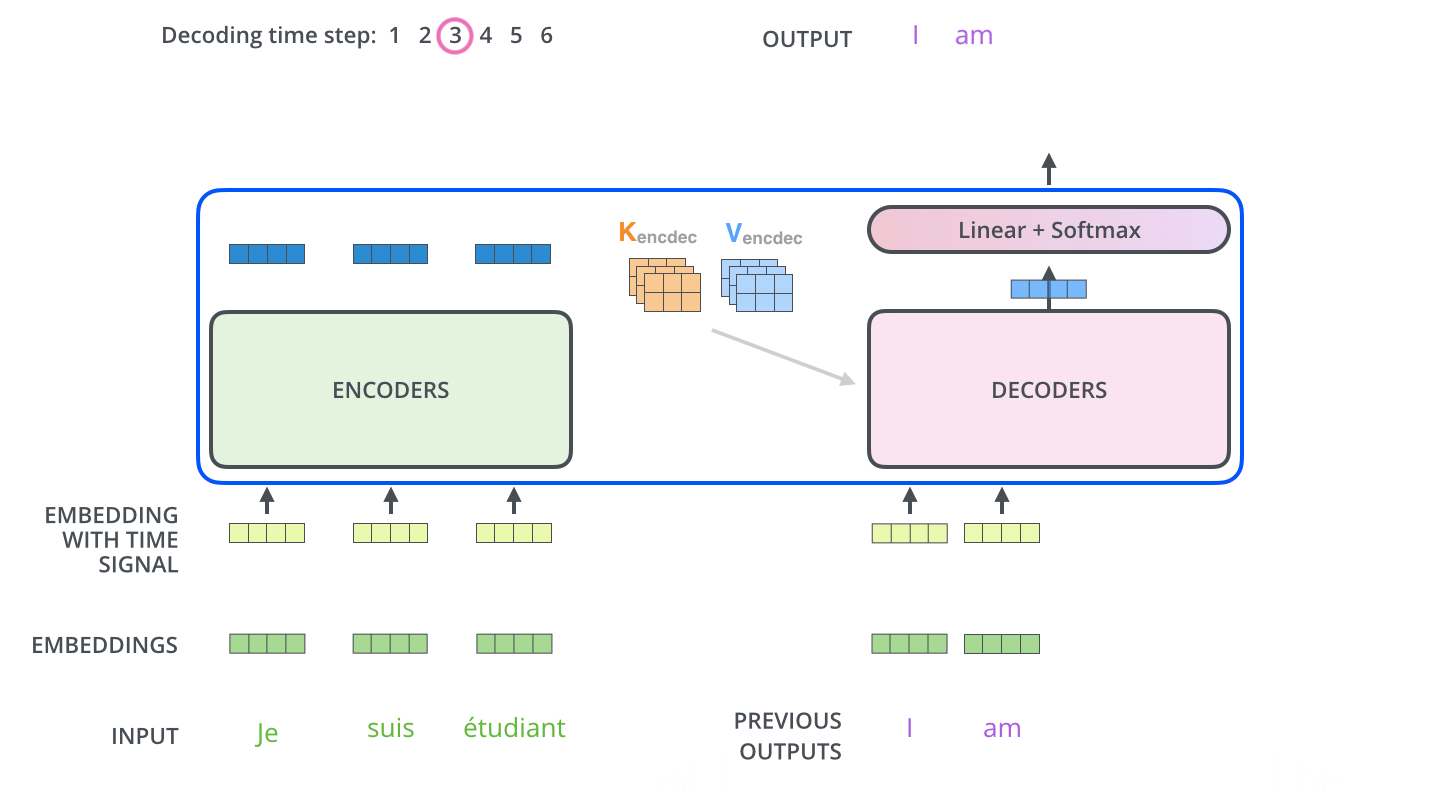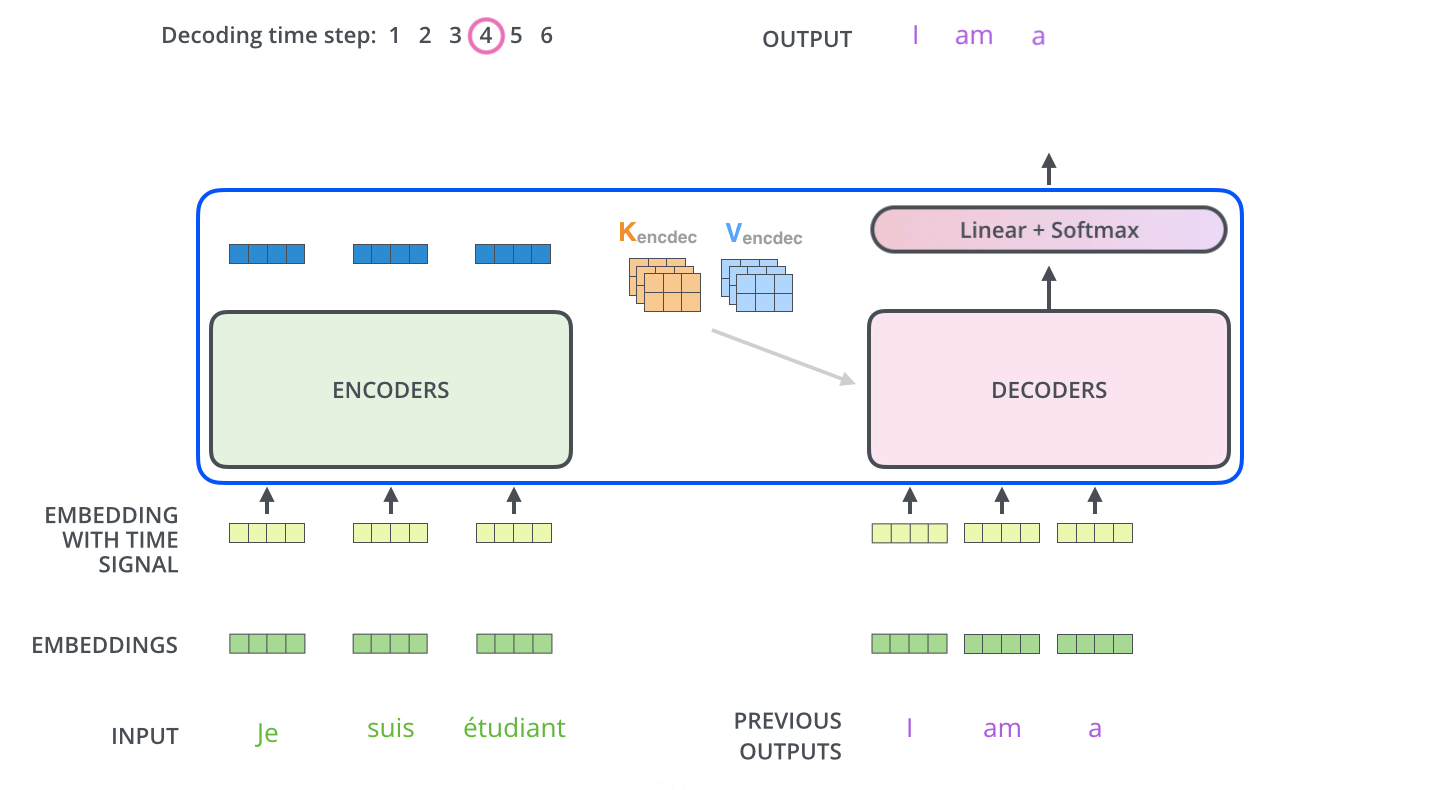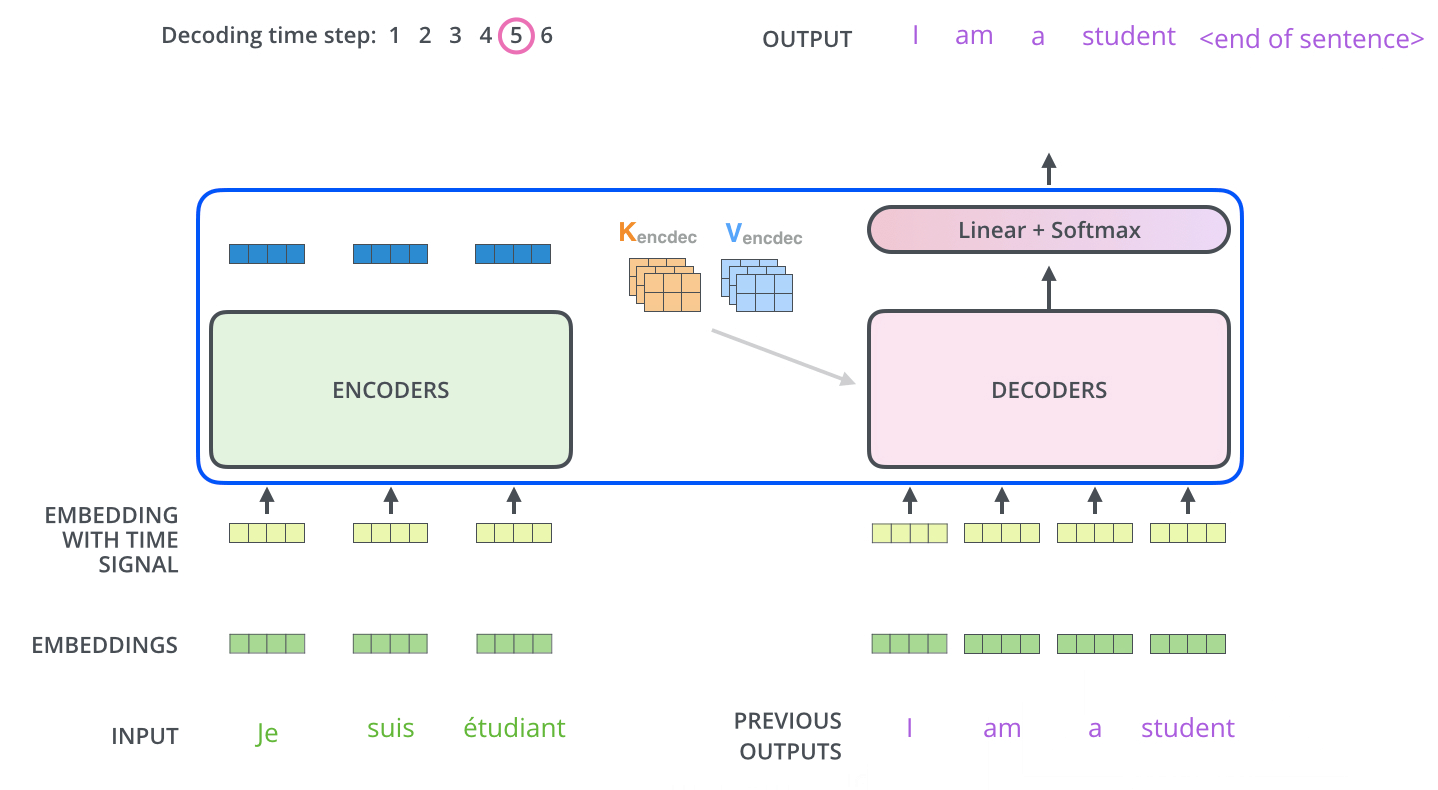
这样一来就能够通过transformer得到对应的一个不带位置编码的输出
一句话总结就是:
encoder-decoder attention中,Q来自于decoder的上一个输出,KV来自于encoder的输出 - position embedding
通过之前的分析会发现,transformer没有捕捉序列的能力
因为只是单纯的对每个单词计算了自身的注意力,然后求和
那么单词之间的顺序即便发生改变,对于计算也不会有影响
这肯定是不对的,比如我吃饭和饭吃我,表达的含义肯定不同
为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding)的特征。
具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
position embedding的公式如下:
一句话总结就是:
作者在开源的源码中有现成的工具包可以计算
最后的最后还有一个线性激活和映射到概率的softmax得到最终Transformer的结果
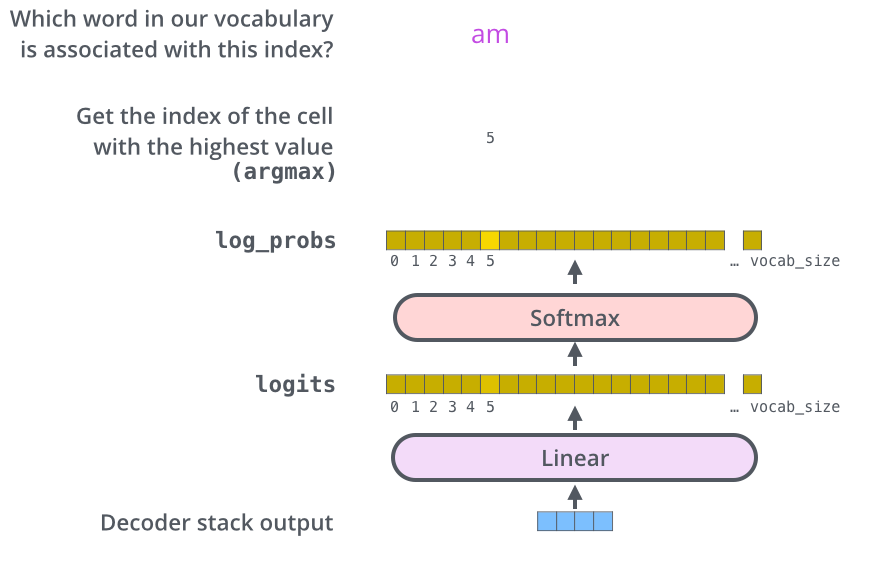
Transformer的一些思考
-
单词之间的距离为1
传统的lstm和rnn等是存在文本的长依赖问题的,且输出小于等于输入的个数
transformer在self attention的驱动下,注意力的计算只依赖于单词本身,
所以将单词之间的距离缩短为1,减少计算量的同时,带来的是精度的飞跃 -
attention机制
文本中的注意力和图像邻域的注意力有异曲同工之妙
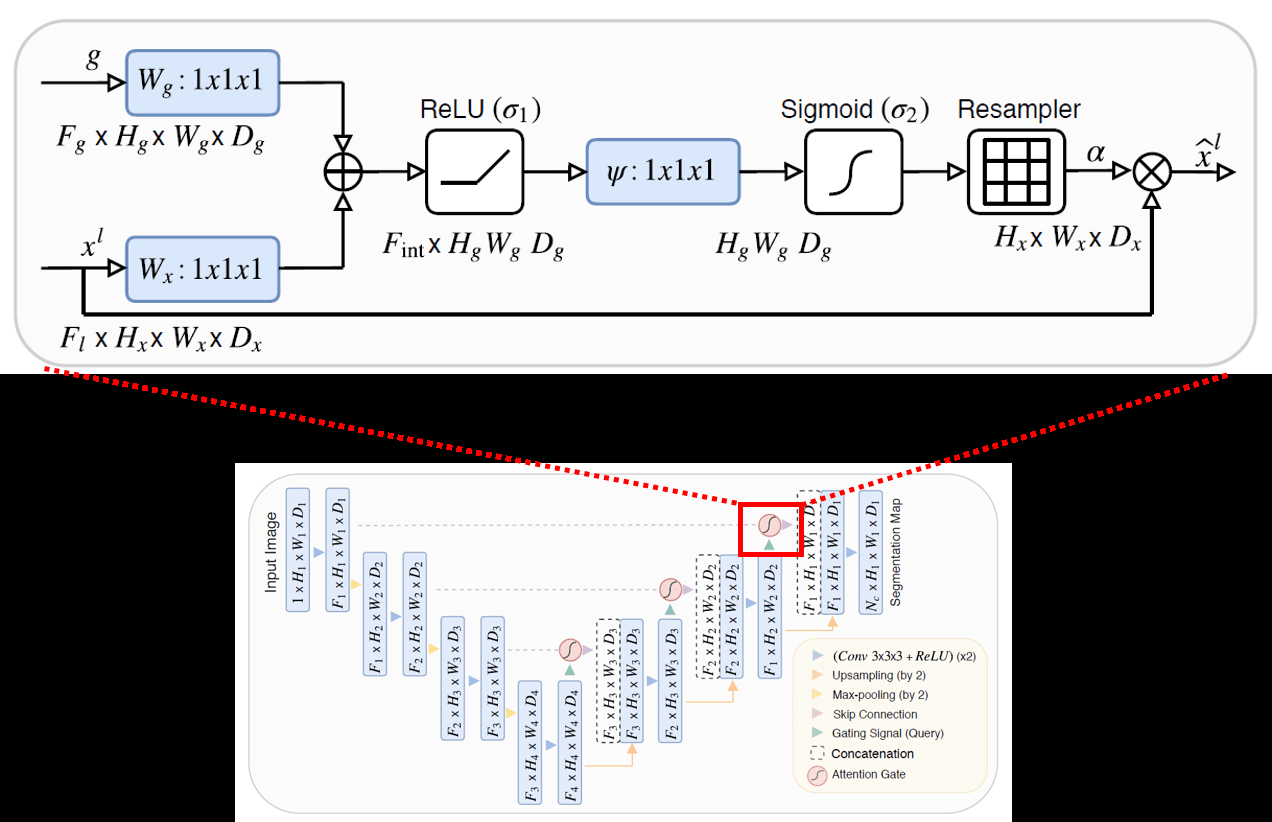
图中所示的是attention-unet的结构,上方的是他的attention机制的说明
可以看到,大致步骤为:
- 原始feature map与同层的短接feature map融合
- relu+sigmoid得到新的feature map
- 新的feature map融合底层的短接feature map作为当前的注意力指导分割进行
而本节中的self attentin模块儿
QKV三个向量都是从X衍生的底层语义,QK运算得到分数加上映射激活相当于提取高级语义,再与低级语义进行注意力的增强
有get到其中的相同之处吗?
这是我对于处理图像和文本方面的注意力机制的思考和总结
高级特征(或语义)结合底层特征(或语义)可以增加对某些特征的注意力,提升精度
也希望看到这里的大家能有共鸣
BERT
终于到本文的主角BERT,慢慢来
BERT全称Bidirectional Encoder Representation from transformer
可以看到和transformer的渊源很深
而且从全称上也不难看出,BERT是一种基于transformer的双向编码表征
可能稍微有点不准确,想表达的意思是BERT不完成特定任务,
但是作为encode的它,加以改造可以完成很多任务
语言模型
会经常听到语言模型这个词,BERT从某种程度上说可以算是语言模型
这里单独拎出来解释一下,什么是语言模型
参考忆臻大佬的好文:https://zhuanlan.zhihu.com/p/28080127
语言模型是判断“是否为人话的概率”
当然这里只是抛砖引玉,‘人话’可以具象化为其他的任务
- 马尔科夫假设
为了解决參数空间过大的问题。引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。 - n-gram(图片来自:https://zhuanlan.zhihu.com/p/52061158)
简单说来,
语言模型就是词与词之间的联系的一种表征
unigram是用当前词自身出现的概率来表征
bigram是用当前词和前一个词出现的条件概率来表征
trigram是用当前词和附近两个词出现的条件概率来表征
原始博客中有带详细样例的解释,由于篇幅原因,这里就不再赘述。 - 神经网络语言模型
参考:https://zhuanlan.zhihu.com/p/52061158
从特性上可以将 n-gram 语言模型看作是基于词与词共现频次的统计,
而神经网络语言模型则是给每个词分别赋予分布式向量表征,探索它们在高维连续空间中的依赖关系。
实验证明,神经网络的分布式表征以及非线性映射更加适合对自然语言进行建模
一句话总结:
语言模型==特定任务的表征
BERT结构
本部分内容学习自:https://blog.csdn.net/jiaowoshouzi/article/details/89073944?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
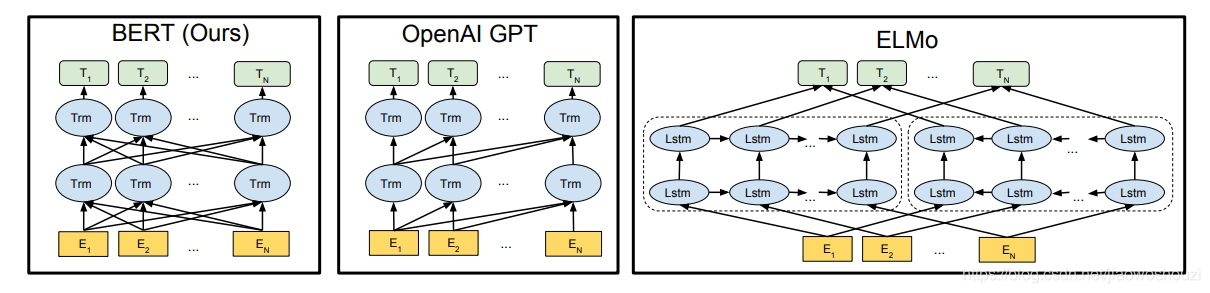
elmo:将上下文当作特征,但是无监督的语料和我们真实的语料还是有区别的,不一定的符合我们特定的任务,是一种双向的特征提取。
openai gpt就做了一个改进,也是通过transformer学习出来一个语言模型,不是固定的,通过任务 finetuning,用transfomer代替elmo的lstm。虽然可以进行fine-tuning,但是有些特殊任务与pretraining输入有出入,单个句子与两个句子不一致的情况,很难解决,还有就是decoder只能看到前面的信息。
bert在多方面的nlp任务变现来看效果都较好,具备较强的泛化能力,对于特定的任务只需要添加一个输出层来进行fine-tuning即可
结构这块儿再说说常用的预训练模型里会提到的几个概念:
比如:
l代表layer,代表transformer层数
h代表hidden,代表了模型输出的维度
a代表multi-head attention的个数
其余的以此类推
BERT输入
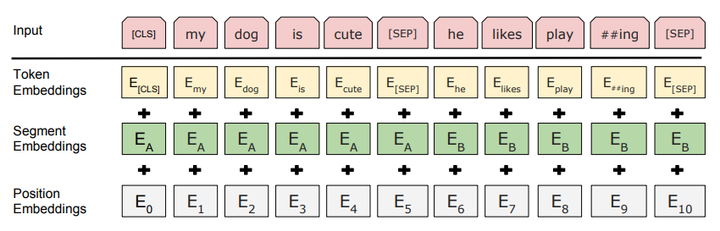
BERT的输入是由三种embedding组成的,分别是:
token embedding:WordPiece tokenization subword
segment embedding:下一句是否是上一句的接续,值为0和1
position embedding:学习出来的embedding向量。这与Transformer不同
预训练模型
BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
- Masked Language Model
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
- 80%的时间是采用[mask],my dog is hairy → my dog is [MASK]
- 10%的时间是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%的时间保持不变,my dog is hairy -> my dog is hairy
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
2. Next Sentence Prediction
选择一些句子对A与B,其中50%的数据B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,
添加这样的预训练的目的是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
推荐阅读:https://blog.csdn.net/jiaowoshouzi/article/details/89073944?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
这里对其中的总结做一遍陈述:
- RNN类LM的视野是单侧可见,从头到当前的节点
- CBOW类的视野是窗口内可见,
- BERT则是除mask可见
其实mask的增加是增大了训练的难度,
但是增加了NSP的训练任务之后,两个任务联合,
上下句之间的联系修正embedding引导训练效果提升
结语
BERT的实现主要是围绕工程化的项目来进行的
因为大部分都是针对其预训练模型来设计封装匹配自己的训练任务
所以如何工程化实现封装BERT是一件迫在眉睫的事情
也是不得不熟练掌握的事情
好在随着时间的推移,
倾向于开箱即用的朋友们有很多福音
诸如keras_bert,bert4keras等包的出现造福了keras用户
bert_pytorch造福了pytorch用户
啥别说了,上手加油干,冲冲冲

