
javaSE之I/O流
Java里\r和\n的区别https://blog.csdn.net/shimengran107/article/details/76923090
File文件类
java.io.File是文件和目录路径名的抽象表示形式,使用File类方法可以对文件或文件夹进行创建、删除、获取、判断是否存在,以及遍历文件夹、获取文件大小。
File类与系统无关,任何的操作系统都可以使用这个类中的方法
常量(只有static的)
- pathSeparator:不同路径之间的分隔符,Windows里是';',Linux里是':'。
- pathSeparator = "" + pathSeparatorChar
- separator:文件名称分隔符,Windows里是'\',Linux里是'/'。
- separator = "" + separator
所以有时候不能一下子写完路径,得把分隔符用File.separator代替
绝对路径和相对路径
绝对路径是完整的、以盘符开始的路径;
相对路径是简化的、相对当前项目的根目录(不是“父目录”),若在根目录下则不以分隔符开头
API学法
- 看类的静态变量
- 看类的构造方法和其参数
- 看常用方法
构造方法
- File(String pathname)构造方法,pathname是字符串的路径名称,只是把字符串封装成File对象,不考虑路径的真假情况。可以是文件结尾,也可以是文件夹结尾;可以是相对路径,也可以是绝对路径;路径可以存在,也可以不存在。(IDEA里输pathname会自动把一个杠改成两个杠)
- File(String parent, String child),从用法上来说除了两个字符串拼起来,parent后缀和child前缀有无斜杠都不用管了
- File(File parent, String child),为什么没有两个参数都是File的,我不知道。
- toString()重写,会打印出路径
常用方法
- getters
- public String getAbsolutePath():绝对路径
- public String getPath():返回构造的时候给的路径(双字符串构造就返回字符串相连,文件+字符串构造就返回文件.getPath()+字符串),绝对或者相对。重写的toString()返回的就是getPath()
- public String getName():返回表示的文件或目录的名称
- public long length():返回由此File表示的文件的长度,注意单位是字节、文件夹没有大小所以返回0、不存在的文件大小也是0
IDEA自动补全:在方法内写变量+".var"自动补全成相应局部变量的声明
-
判断方法
- public boolean exists():文件/文件夹是否实际存在
- isFile()
- isDirectory():这两个方法若路径不存在则都返回false
-
创建/删除
- public boolean createNewFile():还没有文件则创建该新文件并返回true,已有文件则返回false。注意直属目录必须存在,否则会抛出IOException
- public boolean mkdir():创建单级空文件夹,直属目录不存在抛出IOException
- public boolean mkdirs():可以创建单级文件夹,也可以创建多级文件夹,当然就不会抛出异常。注意即使名字有扩展名用这个方法创建出来也是文件夹而不是文件
- public boolean delete():文件/文件夹删除成功返回true,文件夹里有文件就不会删除、File构造时给的路径不存在也不会删除,返回false。delete()是直接在硬盘上删除,不走回收站,所以要谨慎删除。
-
遍历
- public String[] list():返回String数组,表示File目录中的所有子文件或目录
- public File[] listFiles():返回File数组,表示File目录中的所有子文件或目录。
路径不存在或者不是目录而是文件,都会抛出空指针异常。
递归打印多级目录
import java.io.File;
public class TestFile {
public static void main(String[] args) {
File f = new File("C:\\Users\\ltc\\Desktop");
printAllFiles(f);
}
public static void printAllFiles(File file) {
for (File listFile : file.listFiles()) {
if(listFile.isFile())
System.out.println(listFile);
else{
System.out.println(listFile);
printAllFiles(listFile);
}
}
}
}
文件搜索-过滤器
给上面的程序加一条需求:只要.java结尾的文件
每个打印之前判断listFile.getName()是否endsWith(".java"),也可以用toString(),不想考虑大小写就在中间夹一个.toLowerCase()
也可以使用过滤器来实现这个过程
- File[] listFiles(FileFilter filter)
- File[] listFiles(FileNameFilter filter)
java.io.FileFilter是用于过滤抽象文件名(即过滤File对象)的过滤器,是接口,只有一个抽象public boolean accept (File pathname)方法,作用是测试pathname是否应该包含在某个路径名列表中(路径名是否被过滤器所接受)。
java.io.FileNameFilter是用于过滤抽象文件名(即过滤File对象)的过滤器,是接口,只有一个抽象public boolean accept (File dir, String name)方法。
两个过滤器接口都没有实现类,需要自己重写方法实现成类。分这么小也许就是之前学的“接口隔离”原则的体现吧。哦,一个接口里只有一个抽象方法,也方便写成lambda表达式。
public static FileFilter ff = new FileFilter() {
@Override
public boolean accept(File pathname) {
return pathname.getName().endsWith(".txt") || pathname.isDirectory;
//过滤掉不以.txt结尾的文件
}
};
public static void printAllFiles(File file) {
for (File listFile : file.listFiles(ff)) {
//给listFiles()传入过滤器
//对象只用一次,可以写成匿名内部类,进而再改成lambda表达式
// for (File listFile : file.listFiles((pathname) -> pathname.getName().endsWith(".txt") || pathname.isDirectory())) {
if(listFile.isFile())
System.out.println(listFile);
else{
printAllFiles(listFile);
//对目录继续递归调用
}
}
}
相当于把原来可能要分散写的多个判断集中、抽象成一个方法,并且save通用的逻辑(判断是否加入文件名字符串数组/文件数组)
基本I/O流
硬盘永久存储,内存临时存储。
I for input表示读取,从硬盘读取到内存中;O for output表示写入,把内存中的数据写入到硬盘中保存。(文件形式)
流是数据,分为字符流和字节流。一个字符是两个字节,一个字节是8个二进制位。
四个顶层父类:
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流 InputStream |
字节输出流 OutputStream |
| 字符流 | 字符输入流 Reader |
字符输出流 Writer |
字节流:InputStream和OutputStream
一切文件都以二进制的一个个字节存储,故字节流可以传输任意文件数据。(包括图片、视频、音频等只能拆成字节而不能拆成字符的文件。)操作流时要明确,底层传输的始终是二进制数据。
顾名思义Stream是字节流的意思,但是java.io.OutputStream跟java.util.stream没有继承关系。
字节输出流:OutputStream
是一个抽象类,write(int b)是抽象方法,无法创建对象。
| Modifier and Type | Method and Description |
|---|---|
void |
close() 关闭此输出流并释放与此流相关联的任何系统资源。 |
void |
flush() 刷新此输出流并强制任何缓冲的输出字节被写出。 |
void |
write(byte[] b) 将 b.length字节从指定的字节数组写入此输出流。 |
void |
write(byte[] b, int off, int len) 从指定的字节数组写入 len个字节,从偏移 off开始输出到此输出流。 |
abstract void |
write(int b) 将指定的字节写入此输出流。 |
OutputStream是表示输出字节流的所有类的超类(父类),定义了一些子类共性的成员方法,
流close()之后在调用读写方法会报IOException: Stream closed
的直接子类FileOutputStream
OutputStream的子类,文件输出字节流
| Constructor and Description |
|---|
FileOutputStream(File file) 创建文件输出流以写入由指定的 File对象表示的文件。 |
FileOutputStream(File file, boolean append) 创建文件输出流以写入由指定的 File对象表示的文件。 |
FileOutputStream(FileDescriptor fdObj) 创建文件输出流以写入指定的文件描述符,表示与文件系统中实际文件的现有连接。 |
FileOutputStream(String name) 创建文件输出流以指定的名称写入文件。 |
FileOutputStream(String name, boolean append) 创建文件输出流以指定的名称写入文件。 |
构造方法的作用:
- 创建一个FileOutputStream对象
- 会根据构造方法中传递的文件/文件路径,创建一个空的文件
- 会把FileOutputStream对象指定给创建好的文件
注意:这里IDEA里运行程序,创建文件是在项目根目录下;而cmd会在src下。因为.java文件在src里,javac编译又把.class生成在.java同目录下,创建文件用的是“相对地址”,不加前缀的话就是在同目录下。所以说,IDEA里以项目根目录为准,而cmd运行时以.class文件所在目录为准。
写入数据的原理:java程序->java虚拟机->操作系统->操作系统调用写数据的方法->把数据写入到文件中
所以说,JVM是不知道怎么分页的
字节输出流的使用步骤(重点):
- 创建一个FileOutputStream对象,构造方法中传入数据的目的地
- 调用FileOutputStream对象的方法write()把数据写入到文件中
- 释放资源(使用流会占用一定的内存,使用完毕要把流占用的内存清空,提高程序效率)
构造方法会抛出FileNotFoundException,write()会抛出IOExcetion。
可以文件资源管理器里的文件悬浮框里看到文件的“大小”,只写进去一个字节,大小就是1 字节。
写数据的时候会先把传入的参数转成二进制,再把二进制数据写进文件里(Windows自带计算器里有“程序员”功能选项,可以转换进制)
任意的文本编辑器(记事本,notepad++等等)在打开文件的时候都会查询编码表,把字节转换为字符表示。0~127查询ASCII表,对其他值查询系统默认编码表,比如中文系统的GBK。
一次写入多个字节
write(int b)是写入单个字节,一次写入多个字节的方法:
- write(byte[])将b.length个字节从指定的字节数组写入此输出流。
- write(byte[] b, int off, int len)从指定的字节数组写入len字节,从偏移量off开始输出到此输出流。把字节数组的一部分写入到文件中。
如果当前一个字节是整数(0~127),那么就查询ASCII表显示;如果当前字节是负数,那么和下一个字节两个字节组成一个中文显示,查询GBK。
原以为不能方便地通过字节数组写入中文字符,因为不知道拆成的两个字节分别能表示什么字符。然而String类有一个方法叫getBytes(),可以把字符串转换成字节数组。
UTF-8里3个字节是一个中文字符,GBK里两个字节是一个中文字符。
重建文件->追加写/续写
使用两个参数的构造方法
- FileOutputStream(String name, boolean append)
- FileOutputStream(File file, boolean append)
boolean append是追加写开关:开则追加,关则覆盖。需要注意的是,不带append参数的new会直接重建文件,先不带一次再带一次相当于不带。
'\r'与'\n'
换行就用换行符。在这里,换行符是"\r\n",但是实际用写"\r"、"\n"都是换行。关于单独一个"\r",cmd里输出的和IDEA控制台、到文件的输出流表现不同,cmd里的"\r"是回到本行开头开始写,遇到写过的内容覆盖,IDEA控制台和文件输出流则表现为换行。
| \r | \n | \r\n | \n\r | |
|---|---|---|---|---|
| IDEA控制台print() | 清除本行、回到本行开头 | 换行 | 换行 | 换行 |
| IDEA 文件write() | 换行 | 换行 | 换行 | 换两行 |
| cmd里print() | 回到本行开头、覆盖 | 换行 | 换行 | 换行 |
| cmd里write() | 换行 | 换行 | 换行 | 换两行 |
电传打印机打完一行换行,打印头移动时间为避免丢失新来字符,回车(Carriage Return、'\r')是打印头定位在左边界,换行(Line Feed、'\n')是换行;但电脑不需要两个字符且浪费存储空间,所以产生了分歧。
对于不同的操作系统:
-
Unix 系统中:每行结尾只有 "<换行>",即 "\n";
-
Windows 系统中:每行结尾是 "<回车><换行>",即 "\r\n";
-
Mac 系统中:每行结尾是 "<回车>",即 "\r"。
字节输入流:InputStream
也是个抽象类、所有字节输入流的超类,也有close(),以及读取单个字节的abstract read()和读取多个字节存在b中的read(byte[] b)、读取到部分数组中的read(byte[] b, int off, int len)。
| Modifier and Type | Method and Description |
|---|---|
int |
available() 返回从该输入流中可以读取(或跳过)的字节数的估计值,而不会被下一次调用此输入流的方法阻塞。 |
void |
close() 关闭此输入流并释放与流相关联的任何系统资源。 |
void |
mark(int readlimit) 标记此输入流中的当前位置。 |
boolean |
markSupported() 测试这个输入流是否支持 mark和 reset方法。 |
abstract int |
read() 从输入流读取数据的下一个字节。 |
int |
read(byte[] b) 从输入流读取一些字节数,并将它们存储到缓冲区 b 。 |
int |
read(byte[] b, int off, int len) 从输入流读取最多 len字节的数据到一个字节数组。 |
void |
reset() 将此流重新定位到上次在此输入流上调用 mark方法时的位置。 |
long |
skip(long n) 跳过并丢弃来自此字节流的n字节数据。 |
的直接子类FileInputStream
构造方法(File file / String name)作用:
- 创建FileInputStream对象
- 把新创建的对象指定给构造方法中要读取的文件
也会抛FileNotFoundException
读取数据的原理:java程序->JVM->操作系统->操作系统调用读取数据的方法->读取文件
字节输入流的使用步骤(重点):
- 创建FileInputStream对象
- 使用FileInputStream对象中的方法read读取文件
- 释放资源
int read()方法读到文件末尾EOF会返回-1,每调用一次会把指针后移一个字节,类似迭代器的next(),到了EOF之后再读都会读到-1。
不知道循环使用多少次用while,已知循环多少次用for循环。
循环读取所有字节是while((len=fis.read())!=-1)
(不知道为什么读取一个字节的方法要返回一个int值)
读取单个字节加(char)强转成字符,就可以看到原本的字符。但是如果原字符不是单字节,就不行了。
字节输入流一次读取多个字节
int read(byte[] b)把指定文件各字节读到字节数组b中,b满为止。
如果已经到了文件尾,就不会再覆盖b了,继续读下去b会仍然是最后读到的一组字节。这么说也不对,因为最后读到不一定是整组,b也可能是最后读到的半组字节和没有覆盖掉的前一组字节的剩余部分。
throws把异常加到方法签名上相当于把异常给JVM处理,默认应该这样做,当想要在抛出异常前后加逻辑的时候才选try/catch。
返回值是读取到的字节个数,int read(byte[] b)里可以表现出来:当且仅当b长度为0时会返回0,只读到EOF时会返回-1,正常情况读满字节数组b会返回数组长度,读到一半遇到EOF了的话读到几个字节返回几。
之前想为啥无参read()明明只读一个字节却要返回两个字节的int,上一段说的跟这个没关系,因为返回的int需要装read()到的字节,当然是int的两个字节装read()到的一个字节。
以数组读入可以起到缓冲作用,缓冲可以减少整个文件的读取时间。
数组长度一般定义为1024(1kb)或1024的整数倍,不知道文件多大所以也套个循环,
while(len=fis.read(bytes)!=-1){
System.out.print(new String(bytes, 0, len);
}
字节数组转为字符串
Arrays.toString(bytes)是写出字节数组,String的重载构造方法new String(bytes)可以恢复原本的字符串。
练习:字节流复制任意文件
import java.io.*;
public class TestIO {
public static void main(String[] args) throws IOException {
CopyFileWithStream("C:\\Users\\ltc\\Desktop\\java笔记\\[U2KK4I9YC{K[FR_QGVOSK1.png");
}
private static void CopyFileWithStream(String original) throws IOException {
CopyFileWithStream(original, ".");
return;
}
private static void CopyFileWithStream(String original, String dest) throws IOException {
File file = new File(original);
FileInputStream fileInputStream = new FileInputStream(file);
File newFile = new File(dest, file.getName());
FileOutputStream fileOutputStream = new FileOutputStream(newFile);
int len;
byte[] bytes = new byte[1024];
while((len=fileInputStream.read(bytes))!=-1)
fileOutputStream.write(bytes);
fileOutputStream.close();
fileInputStream.close();
//一般都先关写后关读
}
}
然而这种方法自己写也没意义,java.nio.file包里有一个Files类的copy方法。
字符流:Reader和Writer
字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。(弹幕说有乱码??实验了一下除非new String(bytes)输出在控制台上,否则中文直接字节数组读写到另一个文件是不会出乱码的,咋有人傻到读了字节片直接转成字符打印的,这肯定是前面课都没听,翻到api里有这方法就直接随便用了,要么就是智障)
当需要把中文输出到控制台上的时候需要用字符流。
字符输入流:Reader
的直接子类FileReader
用于读取字符文件的便捷类
类似InputStream的read()返回的int型要装读到的字节,FileReader读到的int型也装的是读到的字符。int有4个字节所以不用怕utf-8用3个字节装中文
也可以read(字符数组),以字符数组作缓冲区,输出的时候也是用new String()包装一下(可以加int offset 和 int count两个参数 )
字符输出流:Writer
| Modifier and Type | Method and Description |
|---|---|
Writer |
append(char c) 将指定的字符附加到此作者。 |
Writer |
append(CharSequence csq) 将指定的字符序列附加到此作者。 |
Writer |
append(CharSequence csq, int start, int end) 将指定字符序列的子序列附加到此作者。 |
abstract void |
close() 关闭流,会先刷新。 |
abstract void |
flush() 刷新流。 |
void |
write(char[] cbuf) 写入一个字符数组。 |
abstract void |
write(char[] cbuf, int off, int len) 写入字符数组的一部分。 |
void |
write(int c) 写一个字符 |
void |
write(String str) 写一个字符串 |
void |
write(String str, int off, int len) 写一个字符串的一部分。 |
的直接子类FileWriter
作用:把内存中的字符数据写入到文件中
Writer子类的write()方法有一个字符转换为字节的过程,一个字符肯定占整数个字节所以单纯转换就行了?
字符输出流的使用步骤(重点):
- 创建FileWriter对象,构造方法中绑定要写入数据的目的地(加一个boolean append参数续写开关)
- 使用FileWriter中的方法write(),把数据写入到内存缓冲区中(字符转换为字节的过程)
- 使用FileWriter中的方法flush(),把内存缓冲区中的数据刷新到文件中
- 释放资源(会先把内存缓冲区中的数据刷新到文件中,所以第三步是可以省略的,只要不忘记关掉Writer)
为什么FileOutputStream就不用内存缓冲区,FileWriter就要用呢?
因为FileOutputStream的finalize()方法里有flush(),死亡时会自动刷新缓冲区,而FileWriter甚至没有finalize()方法;所谓关闭流以节省资源是在其死亡之前,所以finalize()并不能帮我们save关闭流的labor。
https://blog.csdn.net/a4171175/article/details/90749839
异常处理,JDK7和9的新特性
如果读写流读写时出现异常,跟在后面的关闭流语句就不能再执行了,所以需要try/catch把关闭流语句写在finally块里。(这里不用throws而选择try/catch/finally是必要的,因为throws如上所说会导致资源浪费)
而如果finally块中没有return,即使catch到异常,finally块以后的语句也还会执行,也就是说为了保证流不用了就被关闭,try/catch是必要的,finally可以不加。
创建流失败的话,关闭流语句就无可关闭,所以声明流变量要提到try块前面,而且因为使用变量时要求变量已被初始化,起码需要在进try块之前给流一个null值。但是让一个null进行close()还会有空指针异常。
实验表明,try/catch是优先于throws的。
import java.io.*;
public class TestWriter {
public static void main(String[] args) throws IOException{
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter("Z:\\a.txt");
fileWriter.write(1);
} catch (IOException e) {
e.printStackTrace();
}
finally {
if(fileWriter != null)
fileWriter.close();//throws IOException
}
}
}
JDK1.7新特性:在try后面可以增加一个(),在括号中可以定义流对象,那么这个流对象的作用域就在try中有效,try中的代码执行完毕会自动把流对象释放,不用写finally了。
JDK9新特性:在try前面定义流对象,在try后()中直接引入流对象的名称(变量名),也是自动释放。因为声明+定义不在try块里,所以需要另外try/catch或者throws。
属性集:Properties,唯一和IO流结合的集合
- java.lang.Object
-
- java.util.Dictionary<K,V> (此类已过时。新的实现应该实现Map接口,而不是扩展这个类。)
-
- java.util.Hashtable<Object,Object> (被HashMap取代的那个)
-
- java.util.Properties
双列集合操作
Properties集合是一个双列集合,key和value默认都是字符串(字节经过编码),Properties有一些操作字符串的特有方法(相比于使用泛型的Hashtable、Map)
- Object setProperty(String key, String value)调用Hashtable的put方法
- String getProperty(String key),相当于Map集合的get(key)方法
- Set<String> stringPropertyNames(),相当于Map集合的keySet()方法
- Set<Map.Entry<Object, Object>> entrySet(),不知从几反正11有的,调用了Map的entrySet()
第一次听到“双列集合”这个说法
持久化属性操作
Properties表示一个持久化的属性集,是唯一和IO流结合的集合。
store()
可以用store()把集合中的临时数据持久化写入到硬盘中存储。
- void store(OutputStream out, String comments)
- void store(Writer writer, String comments)
参数:
- OutputStream out:字节输出流,不能写入中文
- Writer writer:字符输出流,可以写中文
- String comments:注释,用来解释说明保存的文件是做什么用的,不能使用中文,因为会产生乱码,默认是Unicode编码,而IDEA里可以看到默认是GBK,一般使用""空字符串
用字节流把中文写进文件里会看到中文GBK编码被拆成两个两个字节(每两个字节是以\u打头的4位16进制数字Unicode16进制编码),但是如果再用字节流读回来输出到控制台就会发现又变回中文了
使用步骤:
- 创建Properties集合对象,添加数据
- 创建字节输出流/字符输出流对象,构造方法中绑定要输出的目的地
- 使用Properties集合中的方法store,把集合中的临时数据持久化写到硬盘中存储
- 释放资源
load()
可以用load()把硬盘中保存的文件(键值对)读取到集合中使用。
- void load(InputStream inStream)
- void load(Reader reader)
参数:
- InputStream inStream:字节输入流,不能读取含有中文的键值对(load()传字节输入流的时候看不懂中文字符,只能看懂字节)
- Reader reader:字符输入流,能读取含有中文的键值对
使用步骤:
- 创建Properties集合对象
- 使用Properties集合对象中的方法load读取保存键值对的文件
- 遍历Properties集合
注意:
- 存储键值对的文件中,键与值默认的连接符号可以使用=,空格或其他符号
- 存储键值对的文件中,可以使用#进行注释,被注释的部分不会被读取
- 存储键值对的文件中,键与值默认都是字符串,不用再加引号
缓冲流:Buffered...可以包装基本流
缓冲流也叫高效流,是对四个基本的流的增强,所以也是四个,分别是它们的子类。
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流 BufferedInputStream |
字节输出流 BufferedOutputStream |
| 字符流 | 字符输入流 BufferedReader |
字符输出流 BufferedWriter |
类似之前读、写方法传字节数组/字符数组也起到缓冲作用。
Writer自己的缓冲区和BufferedWriter的缓冲区有什么不同?
BufferedOutputStream
extends FilterOutputStream extends OutputStream
变量:
- protected byte[] buf 存储数据的内部缓冲区
- protected int count 缓冲区中的有效字节数
构造方法:
- BufferedOutputStream(OutputStream out) 创建一个新的缓冲输出流,以将数据写入指定的底层输出流
- BufferedOutputStream(OutputStream out, int size) 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
参数:
- OutputStream out:字节输出流,可以传递FileOutputStream,缓冲流会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率
- int size:指定缓冲流内部缓冲区的大小,默认8192
使用步骤(重点):
- 创建一个FileOutputStream对象,构造方法中绑定要输出的目的地
- 创建缓冲流BufferedFileOutputStream对象,构造方法中传递FileOutputStream对象
- 使用BufferedFileOutputStream对象中的方法write,把数据写入到内部缓冲区中
- 使用BufferedFileOutputStream对象中的方法flush,把内部缓冲区中的数据刷新到文件中
- 释放资源(类似FileOutputStream,会先调用flush方法刷新数据,第4步可以省略)
BufferedIntputStream
extends FilterInputStream extends InputStream
构造方法也是包装一个InputStream、可以选择指定缓冲区大小
使用步骤(重点):
- 创建一个FileInputStream对象,构造方法中绑定要输出的目的地
- 创建缓冲流BufferedFileInputStream对象,构造方法中传递FileInputStream对象
- 使用BufferedFileInputStream对象中的方法read,把数据写入到内部缓冲区中
- 释放资源
BufferedWriter
extends Writer
使用步骤(重点):
- 创建一个FileWriter对象,构造方法中绑定要输出的目的地
- 创建缓冲流BufferedFileWriter对象,构造方法中传递FileWriter对象
- 使用BufferedFileWriter对象中的方法write,把数据写入到内部缓冲区中
- 使用BufferedFileWriter对象中的方法flush,把内部缓冲区中的数据刷新到文件中
- 释放资源
特有的方法:
void newLine():写入一个行分隔符,会根据操作系统写入不同的行分隔符
System.out是一个PrintStream,继承FilterOutputStream继承OutputStream,System.out.println()就是System.out.nextLine(),然而类似于Collections.asList()的ArrayList和java.util.ArrayList,两者名字相同却不是一个东西。
| Constructor and Description |
|---|
BufferedWriter(Writer out) 创建使用默认大小的输出缓冲区的缓冲字符输出流。 |
BufferedWriter(Writer out, int sz) 创建一个新的缓冲字符输出流,使用给定大小的输出缓冲区。 |
| Modifier and Type | Method and Description |
|---|---|
void |
close() 关闭流,先刷新。 |
void |
flush() 刷新流。 |
void |
newLine() 写一行行分隔符。 |
void |
write(char[] cbuf, int off, int len) 写入字符数组的一部分。 |
void |
write(int c) 写一个字符 |
void |
write(String s, int off, int len) 写一个字符串的一部分。 |
BufferedReader
| 构造器 | 描述 |
|---|---|
BufferedReader(Reader in) |
创建使用默认大小的输入缓冲区的缓冲字符输入流。 |
BufferedReader(Reader in, int sz) |
创建使用指定大小的输入缓冲区的缓冲字符输入流。 |
| 变量和类型 | 方法 | 描述 |
|---|---|---|
Stream<String> |
lines() |
返回 Stream ,其元素是从此 BufferedReader读取的行。 |
void |
mark(int readAheadLimit) |
标记流中的当前位置。 |
boolean |
markSupported() |
判断此流是否支持mark()操作。 |
int |
read() |
读一个字符。 |
int |
read(char[] cbuf, int off, int len) |
将字符读入数组的一部分。 |
String |
readLine() |
读一行文字。 |
boolean |
ready() |
判断此流是否可以读取。 |
void |
reset() |
将流重置为最新标记。 |
long |
skip(long n) |
跳过字符。 |
readLine
public String readLine() throws IOException
读一行文字。 一行被认为是由换行符('\ n'),回车符('\ r'),回车符后紧跟换行符或到达文件结尾的任何一个终止(EOF)。
-
结果
包含行内容的字符串,不包括任何行终止字符(这句话的意思是换行符得自己加);如果在未读取任何字符的情况下到达流末尾,则返回null
-
异常
IOException- 如果发生I / O错误
使用步骤:
- 创建字符缓冲输入流对象,构造方法中传入字符输入流
- 使用字符缓冲输入流对象中的方法read/readLine读取文本
- 释放资源
练习:文本排序
import java.io.*;
import java.util.TreeMap;
public class 语句行排序 {
public static void main(String[] args) throws IOException {
TreeMap<Integer, String> treeMap = new TreeMap();
FileReader fileReader = new FileReader("出师表.txt");
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line = null;
int num = 0;
try(fileReader;bufferedReader) {
while ((line = bufferedReader.readLine()) != null)
if(line != "")
treeMap.put(Integer.valueOf(line.split("\\.")[0]), line);
//注意'.'是java正则表达式一个特殊字符,需要加杠表示元字符,而杠本身也要加杠
} catch (IOException e) {
e.printStackTrace();
} catch (ArrayIndexOutOfBoundsException arrayIndexOutOfBoundsException) {
System.out.println(line);
}
FileWriter fileWriter = new FileWriter("出师表排序.txt");
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
try(fileWriter;bufferedWriter) {
for (Integer integer : treeMap.keySet()) {
bufferedWriter.write(treeMap.get(integer));
bufferedWriter.newLine();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
转换流:InputStreamReader和OutputStreamWriter,可以使用非默认字符编码读取字符/写入字节,包装字节流
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码。
比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。(GBK和Unicode、UTF-8)
由之前用字节流复制图片的经验知道,字符和字节之间、图片视频音频等文件和字节之间的关系是类似的编码解码关系。
字符编码(Character Encoding):一套自然语言的字符和二进制数之间的对应规则。
编码表:生活中文字和计算机中二进制的对应规则。
字符集
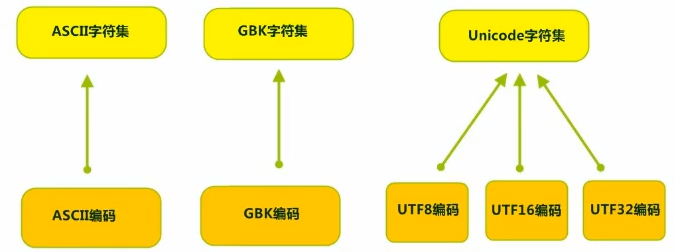
字符集(Charset):也叫编码表。是一个系统(应该认为是一个输入输出系统,而不是一台电脑)支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确地存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。ASCII字符集对应ASCII编码,GBK字符集对应GK编码,Unicode字符集对应UTF-8编码、UTF-16编码、UTF-32编码。
黑马:当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
-
ASCII字符集︰
- ASCll ( American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)
- 基本的ASCII字符集,使用7位 ( bits )表示一个字符,共128字符。ASCII的扩展字符集使用8位( bits )表示一个字符,共256字符,方便支持欧洲常用字符(一般只关注128个正的、不关注256-128个这些负的)。
-
lSO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-8859-1使用单字节编码,兼容ASCIl编码。(所以就是上面的“ASCII的扩展字符集”)
-
GBxxx字符集︰
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312∶简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。(这版只有简体没有繁体,有数字标点字母的全半角、数学符号、罗马希腊字母、日文假名,没有日韩汉字)
- GBK∶最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。(不管Win7、Win10,默认中文都用GBK,以后可能会换到GB18030)
- GB18030∶最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
-
Unicode字符集:
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
- UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCIl字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
编码引出的问题
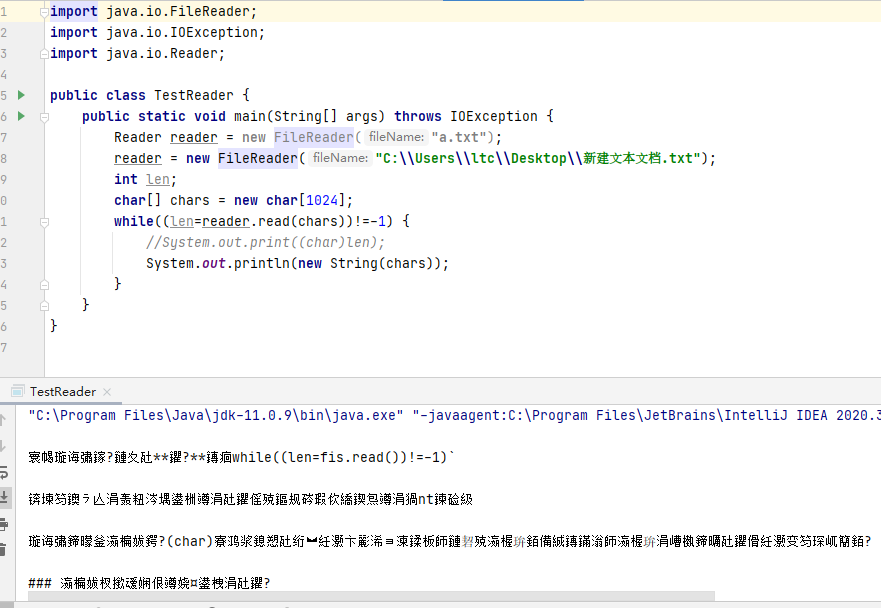
在IDEA中,使用FileReader读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。(读取的字节是没问题的,问题在于转换成字符的时候,怎么显示也是问题)
OutputStreamWriter
FileWriter往底下走直接调用字节输出流FileOutputStream,不能更改存储编码。
java.io.InputStreamWriter extends Writer,Writer的方法都可以使用
OutputStreamWriter是字符流通向字节流的桥梁,可以查询默认码表把字符转换为字节,也可以查询指定码表把字符转换为字节,最后都是调用FileOutputStream输出字节。
构造方法:
- OutputStreamWriter(OutputStream out) 创建使用默认字符编码的OutputStreamWriter
- OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定字符集的OutputStreamWriter(???一个字符集不是可以对应多个编码方案吗。。。这里说的charset就是前面说编码方案的意思)
参数:
- OutputStream out:字节输入流,可以用来写转换之后的字节到文件中
- String charsetName:指定的编码表名称,不区分大小写,不指定就默认使用GBK
使用步骤:
- 创建OutputStreamWriter对象,构造方法中传入字节输出流和指定的编码表名称
- 使用OutputStreamWriter对象中的方法write,把字符转换为字节存储在缓冲区中(编码过程)
- 使用OutputStreamWriter对象中的方法flush(),把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
- 释放资源
InputStreamReader
InputStreamReader是字节流通向字符流的桥梁,它使用指定的charset读取字节并将其解码为字符。它使用的字符集可以通过名称指定,也可以明确指定,或者可以接受平台的默认字符集。(相比之下其子类FileReader使用IDE默认的编码方式读取字节并将其解码为字符)
java.io.InputStreamReader extends Reader可以用Reader的所有方法
InputStreamReader可以查询IDE默认码表和指定文件的码表
构造方法:
- InputStreamReader(InputStream in) 创建一个使用默认字符集的InputStreamReader
- InputStreamReader(InputStream in, String charsetName) 创建使用指定字符集的InputStreamReader
参数:
- InputStream in 字节输入流,用来读取文件中保存的字节
- String charsetName 指定的编码表名称,不区分大小写
使用步骤:
- 创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称
- 使用InputStreamReader对象中的方法read读取文件
- 释放资源
注意事项:
构造方法中指定的编码表名称要和文件的编码相同,否则会发生乱码
练习:转换文件编码
以源文件编码格式读入,把读到的数据以目标编码格式写到目标文件中,记得flush()和close()
序列化流和反序列化流,包装字节流
把对象以流的方式写入到文件中保存称为写对象,也叫对象的序列化
对象中包含的不仅仅是字符,所以要是用字节流。显示在屏幕上当然是字符,但是对象本身存储的时候用的不全是字符。
ObjectOutputStream:对象的序列化流
writeObject(对象)可以把对象编成字节写入到文件中
为了把文件中以字节保存的对象以流的方式读取出来,叫作读对象,也叫对象的反序列化
ObjectInputStream:对象的反序列化流
readObject()返回Object类型的所存储对象,可以强转
序列化流:ObjectOutputStream
java.io.ObjectOutputStream extends OutputStream
构造方法:
- ObjectOutputStream(OutputStream out) 创建写入指定OutputStream的ObjectOutputStream
参数:
- OutputStream:字节输出流
特有的成员方法:
- void writeObject(Object obj)将指定的对象写入ObjectOutputStream
使用步骤:
- 创建ObjectOutputStream对象,构造方法中传入字节输出流
- 使用ObjectOutputStream对象的writeObject方法,把对象写入到文件中
- 释放资源
抛出异常java.io.NotSerializableException:
- 被序列化的类需要实现java.io.Serializable接口,Serializable是一个标记型接口,没有规定任何方法,只用于开启类的序列化/反序列化功能
transient关键字(反序列化后才能表现出来)
static关键字是静态关键字,静态优先于非静态加载到内存中(静态优先于对象进入到内存中),被static修饰的成员变量是不能被序列化的。文件不能获得静态成员变量的值,一个对象经过序列化后静态变量值不变。
也称瞬态关键字,被transient修饰的成员变量也不能被序列化。文件不能获得瞬态成员变量的值,一个对象经过序列化后transient域会变为默认初始值。
反序列化流:ObjectInputStream
java.io.ObjectInputStream extends InputStream
构造方法:
- ObjectInputStream(InputStream in) 创建从指定InputStream读取的ObjectInputStream
参数:
- InputStream in:字节输入流
特有的成员方法:
-
Object readObject() 从ObjectInputStream中读取对象
声明了ClassNotFoundException(找不到类对应的.class文件)
反序列化的前提:
- 类实现Serializable
- 存在类对应的.class文件
使用步骤:
- 创建ObjectInputStream对象,构造方法中传入字节输入流
- 使用ObjectInputStream对象中的readObject方法读取保存对象的文件,可以把读取到的Object类型强转回原类型
- 释放资源
- 使用读取出来的对象(打印)
当JVM反序列化对象时,能找到.class文件,但是.class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号(private static final long serialVersionUID)与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
- 该类没有可访问的无参数构造方法
手动制造这种错误:第一次运行进行序列化,把类修改一下再运行反序列化,就是“可以找到.class文件但serialVersionUID不相等”
InvalidClassException异常原理
编译器(java.exe)会把.java文件编译生成.class文件。被序列化类实现了Serializable接口,就会根据类的定义(类名/接口名、属性、方法)计算出一个序列号、添加到Person.class文件里
反序列化的时候会使用.class文件中的序列号和反序列化所使用的源文件里的序列号比较,如果不一样就会抛出InvalidClassException,一样就反序列化成功。
只要序列化和反序列化之间改变了类的定义,再编译就会把新的序列号写进.class里,导致冲突。
屏蔽这个问题的方案:为使得无论是否对类的定义进行修改,都不生成新的序列号,可以手动给类添加一个序列号。(强烈建议这么做)
static final long serialVersionUID=序列号L;//前面可以加private
那是不是说不同类的序列号之间可以重复?
看来是的。我自己设了两个序列号相等的类,运行了没问题。
序列化和反序列化过程中的更多细节https://blog.csdn.net/qq_39669058/article/details/114144053
| serialVersionUID | 区分不同类 | 支持相同类的重构 |
|---|---|---|
| 不指定 | YES | NO |
| 指定 | NO | YES |
| 自动生成64位哈希值 | YES | YES |
练习:序列化一个集合对象
当想在文件中保存多个对象的时候,可以把多个对象存储到一个集合中,对集合进行序列化和反序列化
不能保存多个对象到同一个文件中,多次保存的话读也没法读。
我试着像之前的流一样循环,不知道
o=objectInputStream.readObject()怎么判断达到文件末尾
分析:
-
定义一个用于存储对象的ArrayList集合
-
往ArrayList集合中存储对象
-
创建一个序列化流ObjectOutputStream对象
-
使用ObjectOutputStream对象的writeObject方法对集合进行序列化
-
创建一个反序列化ObjectInputStream对象
-
使用ObjectInputStream对象中的方法readObject读取文件中保存的集合
-
把Object类型的集合转换为ArrayList类型(**不知道为什么
System.out.println((ArrayList)objectInputStream.readObject())强转是灰色,猜测意思是用不着;但如果直接用arrayList接readObject又不行。仔细看看又发现,强转的灰色还有悬浮窗说是 **'objectInputStream.readObject()'到'ArrayList'是冗余的
,如果调用add()方法又会自动补全强转到ArrayList。
看了源码,是sout(obj)最后会调obj.toString(),不强转也会因为父类引用指向子类对象而重写方法;而add在Object里压根没有,所以必须强转才能使用方法。这就是多态。)
-
遍历ArrayList集合
-
释放资源
import java.io.*;
import java.util.ArrayList;
public class 序列化一个集合对象 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
ArrayList arrayList = new ArrayList();
for (int i = 0; i < 3; i++) {
arrayList.add(new 序列化.Student("王老"+i, '男'));
}
serializeArrayList(arrayList);
}
private static void serializeArrayList(ArrayList arrayList) throws IOException, ClassNotFoundException {
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("a.txt"));
objectOutputStream.writeObject(arrayList);
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("a.txt"));
// System.out.println(objectInputStream.readObject());
arrayList = (ArrayList) objectInputStream.readObject();
for (int i = 0; i < arrayList.size(); i++) {
System.out.println(arrayList.get(i));
}
objectOutputStream.close();
objectInputStream.close();
}
}
打印流PrintStream
每天都在用,System.out就是一个打印流java.io.PrintStream为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
PrintStream特点:
- 只负责数据的输出,不负责数据的读取
- 与其他输出流不同,永远不会抛出IOException
- 特有的方法:print,println
- print(任意类型变量)
- println(任意类型变量并换行)
构造方法:(写目的地,可以加编码表以及是否自动行刷新参数)
- PrintStream(File file)
- PrintStream(OutputStream out)
- PrintStream(String fileName)
PrintStream extends OutputStream,继承父类成员方法
注意:
- 如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表(97->a)
- 如果使用自己特有的方法(print/println)则写的数据会原样输出(97->97)
改变打印流的流向
System.out默认在控制台输出,用System.setOut方法可以改变输出语句的目的地为参数传递的打印流的目的地
static void setOut(PrintStream out)
import java.io.FileNotFoundException;
import java.io.PrintStream;
public class TestPrintStream {
public static void main(String[] args) throws FileNotFoundException {
PrintStream printStream = new PrintStream("a.txt");
System.setOut(printStream);
//改变打印流的流向
System.out.println("我还在控制台吗?");
printStream.close();
}

