
javaSE之集合
https://www.bilibili.com/video/BV1zD4y1Q7Fw?from=search&seid=18420730958811387818千锋教育
new集合泛型给类型的话,第二个尖括号可以不用写,从1.8开始
集合
内容:
- 集合的概念
- Collection接口
- List接口与实现类
- 泛型和工具类
- Set接口与实现类
- Map接口与实现类
什么是集合(Collection)
- 概念:对象的容器,定义了对多个对象进行操作的常用方法,类似数组的功能。
- 和数组的区别:
- 数组程度固定,集合长度不固定
- 数组可以存储基本类型和引用类型,集合只能存储引用类型(
List<int>类型参数不能为基元类型)
- 集合所有类或接口都在
java.util.*目录
Collection体系集合
interface Collection:该体系的根接口,代表一组对象,称为“集合”。Collection接口的父接口是Iterable
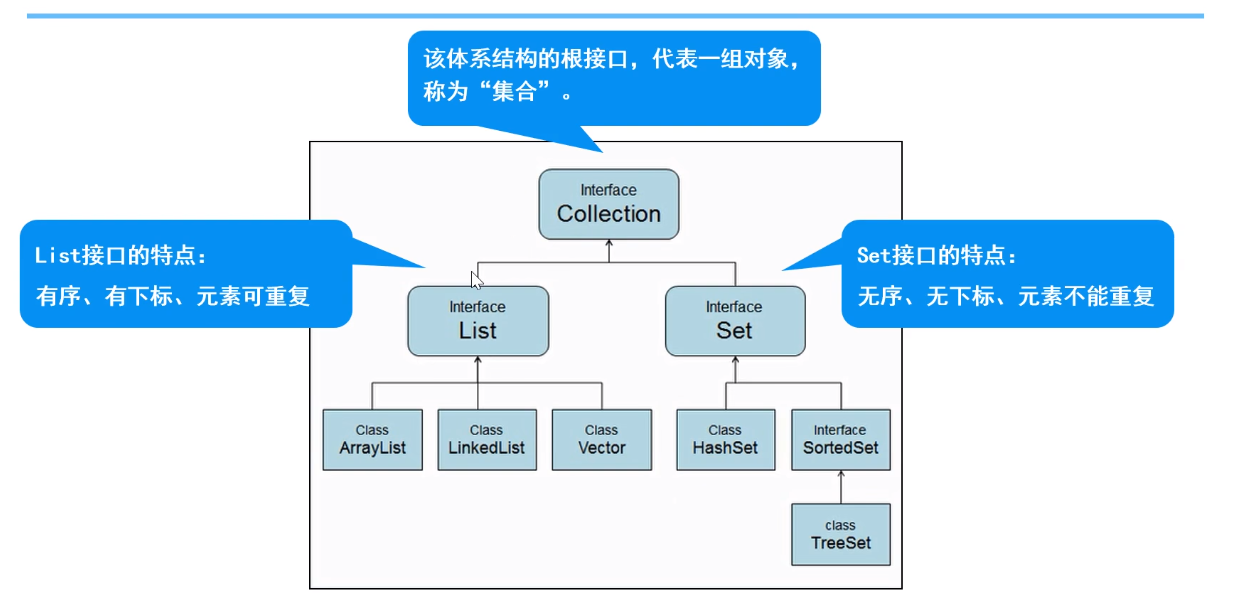
然而就继承关系来说,实际上比如ArrayList的直接父类是AbstractList,再父类是AbstractCollection,然后才是实现Collection接口。图上画的倒也没错,但只是Collection系继承/实现网的一部分。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
public abstract class AbstractCollection<E> implements Collection<E> {
//爷爷类AbstractCollection里面重写了toString()方法,使得我们看到集合类的println()都比较直观
public interface List<E> extends Collection<E> {
public interface Collection<E> extends Iterable<E> {
ArrayList和Interface之间的
Collection根接口的使用
- 特点:代表一组任意类型的对象,实例化成List就可重复、有下标,实例化成Set就不可重复没有下标
- 方法:
| Modifier and Type | Method and Description |
|---|---|
boolean |
add(E e)确保此集合包含指定的元素(可选操作)。 |
boolean |
addAll(Collection<? extends E> c)将指定集合中的所有元素添加到此集合(可选操作)。 |
void |
clear()从此集合中删除所有元素(可选操作)。 |
boolean |
contains(Object o)如果此集合包含指定的元素,则返回 true 。 |
boolean |
containsAll(Collection<?> c)如果此集合包含指定 集合中的所有元素,则返回true。 |
boolean |
equals(Object o)将指定的对象与此集合进行比较以获得相等性。 |
int |
hashCode()返回此集合的哈希码值。 |
boolean |
isEmpty()如果此集合不包含元素,则返回 true 。 |
Iterator<E> |
iterator()返回此集合中的元素的迭代器。 |
default Stream<E> |
parallelStream()返回可能并行的 Stream与此集合作为其来源。 |
boolean |
remove(Object o)从该集合中删除指定元素的单个实例(如果存在)(可选操作)。 |
boolean |
removeAll(Collection<?> c)删除指定集合中包含的所有此集合的元素(可选操作)。 |
default boolean |
removeIf(Predicate<? super E> filter)删除满足给定谓词的此集合的所有元素。 |
boolean |
retainAll(Collection<?> c)仅保留此集合中包含在指定集合中的元素(可选操作)。 |
int |
size()返回此集合中的元素数。 |
default Spliterator<E> |
spliterator()创建一个Spliterator在这个集合中的元素。 |
default Stream<E> |
stream()返回以此集合作为源的顺序 Stream 。 |
Object[] |
toArray()返回一个包含此集合中所有元素的数组。 |
<T> T[] |
toArray(T[] a)返回包含此集合中所有元素的数组; 返回的数组的运行时类型是指定数组的运行时类型。 |
boolean remove(Object o);
Removes a single instance of the specified element from this collection, if it is present (optional operation). More formally, removes an element e such that Objects.equals(o, e), if this collection contains one or more such elements. Returns true if this collection contained the specified element (or equivalently, if this collection changed as a result of the call).
比如collection.remove(new 对象),因为新建的对象和集合原有的对象哈希码不equal,所以删不掉
想要通过元素对象某些属性值分别相等来删除元素,就需要在所属类重写equals方法,这样重写以后对于List类也可以用list.indexOf(new 对象())了
所以说,Integer之类的类也重写过equals了
迭代器Iterator接口
专门用于迭代Collection中的元素,当然迭代元素也可以用增强for
| Modifier and Type | Method and Description |
|---|---|
default void |
forEachRemaining(Consumer<? super E> action) 对每个剩余元素执行给定的操作,直到所有元素都被处理或动作引发异常。 |
boolean |
hasNext() 如果迭代具有更多元素,则返回 true 。 |
E |
next() 返回迭代中的下一个元素。 |
default void |
remove() 从底层集合中删除此迭代器返回的最后一个元素(可选操作)。 |
iterator.remove()和collection.remove(o)会有并发修改异常
增强for循环的底层实现
https://blog.csdn.net/weixin_41799019/article/details/98112586
增强for循环其实是一个语法糖,反编译可以知道其实现是通过迭代器,所以也有迭代器的坑,就是迭代过程中调用集合.remove()会有java.util.ConcurrentModificationException
要删除不能用增强for,还得用迭代器
另外,增强for循环的应用范围是实现了Iterable接口,Collection体系都实现了
List子接口
-
特点:有序、有下标、元素可重复
-
方法(declared):
void add(int index, Object o);//在index位置插入对象o boolean addAll(int index, Collection c);//将一个集合中的元素添加到此集列表中的index位置 Object get(int index);//返回集合中指定位置的元素 Object set(int index, Object o);//用指定元素替换列表中指定位置的元素 List subList(int fromIndex, in toIndex);//返回fromIndex和toIndex之间的部分视图
ListIterator接口
| Modifier and Type | Method and Description |
|---|---|
void |
add(E e) 将指定的元素插入列表(可选操作)。 |
boolean |
hasNext() 返回 true如果遍历正向列表,列表迭代器有多个元素。 |
boolean |
hasPrevious() 返回 true如果遍历反向列表,列表迭代器有多个元素。 |
E |
next() 返回列表中的下一个元素,并且前进光标位置。 |
int |
nextIndex() 返回随后调用 next()返回的元素的索引。 |
E |
previous() 返回列表中的上一个元素,并向后移动光标位置。 |
int |
previousIndex() 返回由后续调用 previous()返回的元素的索引。 |
void |
remove() 从列表中删除由 next()或 previous()返回的最后一个元素(可选操作)。 |
void |
set(E e) 用 指定的元素替换由 next()或 previous()返回的最后一个元素(可选操作)。 |
add
void add(E e)
将指定的元素插入列表(可选操作)。 该元素将被返回的元素之前立即插入next() ,如果有的话,那会被返回的元素之后previous() ,如果有的话。 (如果列表不包含元素,则新元素将成为列表中的唯一元素。)新元素插入隐式游标之前:后续调用next将不受影响,后续调用previous将返回新元素。 (此呼叫将增加一个呼叫将返回的值为nextIndex或previousIndex )。
List实现类
-
ArrayList(重点)/ə'reɪ/
数组结构实现,所以查询快、增删慢
JDK1.2版本开始,运行效率快但线程不安全
-
Vector
数组结构实现,查询快,增删慢
JDK1.0开始。运行效率慢、线程安全
-
LinkedList
双向链表实现,增删快,查询慢
ArrayList源码(jdk11)
-
DEFAULT_CAPACITY,数组默认容量10,如果集合中没有添加元素,数组容量还是0
-
transient Object[] elementData,元素数组
-
DEFAULTCAPACITY_EMPTY_ELEMENTDATA,new ArrayList()用到的空集{}
-
size,包含元素个数
-
add(e)添加元素,modCount是记录ArrayList发生“结构变化”的次数,调用重载的add(e, elementData, size)。
这实际上是一步拆成两步,注释说是为了要限制方法字节码长度 which helps when add(E) is called in a C1-compiled loop,不太懂什么C1-compiled。https://blog.csdn.net/newbie0107/article/details/103111982说是虚拟机把java代码编译成本地代码的时候,编译还分了层之类的,等学JVM再看吧。
add(e, elementData, size)里面先就先判断size到没到elementData.length,如果到了就调用grow()赋值给elementData,grow()返回重载grow(size+1),数组扩容方法grow(minCapacity)又返回Arrays工具类的
Arrays.copyOf(elementData, newCapacity(minCapacity))Arrays.copyOf(数组,新数组长度)是复制出一个新数组,多出一截初始化为0。/** * Returns a capacity at least as large as the given minimum capacity. * Returns the current capacity increased by 50% if that suffices. * Will not return a capacity greater than MAX_ARRAY_SIZE unless * the given minimum capacity is greater than MAX_ARRAY_SIZE. * * @param minCapacity the desired minimum capacity * @throws OutOfMemoryError if minCapacity is less than zero */ private int newCapacity(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity <= 0) { if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) return Math.max(DEFAULT_CAPACITY, minCapacity); if (minCapacity < 0) // overflow throw new OutOfMemoryError(); return minCapacity; } return (newCapacity - MAX_ARRAY_SIZE <= 0) ? newCapacity : hugeCapacity(minCapacity); }newCapacity(minCapacity)的逻辑:
- minCapacity不到数组原长1.5倍时返回数组原长1.5倍,有一个MAX_ARRAY_SIZE是Integer最大值-8,超过MAX_ARRAY_SIZE就调用hugeCapacity(minCapacity)方法返回Integer最大值
- minCapacity不小于数组原长1.5倍是判断是不是新建数组,是则返回Math.max(DEFAULT_CAPACITY, minCapacity),不是新建数组就返回minCapacity
关于transient关键字可以在https://www.cnblogs.com/lanxuezaipiao/p/3369962.html看,还跟什么“序列化”有关系,“被修饰的变量不会被序列化”,我现在还没学到。
Vector
面试可能会问到
vector.elements()//返回Enumeration
firstElement()
lastElement()
elementAt()
Enumeration
是jdk1.2之前用来迭代元素的类,操作类似迭代器,后来ArrayList改用Iterator了,Vector没变
LinkedList
存储结构是双向链表
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
泛型
- Java是泛型JDK1.5之后引入的一个新特性,其本质是参数化类型,把类型作为参数传递。也就是说并不预先定死参数变量是什么类型,等传进来。
- 常见形式有泛型类、泛型接口、泛型方法
- 语法:类名/接口名/方法名<T,...> 其中T称为类型占位符,表示一种引用类型,(只有一个的时候)一般都用T。
泛型类中:类型参数 'T' 不能直接实例化
泛型接口中:不能使用泛型创建静态常量
实现泛型接口的类可以还是一个泛型类,也可以不是
泛型方法的<T>加在static和返回值类型之间,调用的时候可以直接以变量形式同时传入类型参数和变量参数,不需要像泛型类、泛型接口一样提前确定类型。
- 好处:
可以代替写很多参数类型的重载方法(提高代码重用性,这一点也能做到)
相比于没有变量本类型参数的重载方法,调用时临时强转,泛型参数类型可以防止参数类型异常,更安全。
迭代器加尖括号限定类型之后,迭代到类型不对的元素会报类型异常
泛型集合
ArrayList
子类对象加括号强转为父类对象,和声明的时候父类引用指向子类对象一样,会导致不能调用子类方法。
方法用引用类型而不是对象类型区分命名空间,对象类型具有但引用类型不具有的方法就无法调用。
泛型集合的概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致(当然也有可能要求成都是Object子类)
特点:
- 编译时即可检查,而非运行时抛出异常。
- 访问时,不必类型转换(拆箱)。
- 不同泛型之间引用不能相互赋值,泛型不存在多态。
Set子接口
特点:无序、无下标、元素不可重复
方法:主要是继承Collection
HashSet(重点)
- 哈希表数据结构,基于HashCode实现元素不可重复
- 根据HashCode计算元素存放位置,当存入元素的哈希码相同时,会调用equals进行确认,如结果为true,则拒绝后者存入。
哈希表:数组+链表+红黑树
HashSet的add(E e)存储过程
- 先根据hashcode计算保存的位置,如果此位置为空,则直接保存,如果不为空则执行第二步;
- 再执行equals方法,如果equals方法返回true,则认为是重复、拒绝存储(HashSet作为Set是这样);否则形成链表
所以Integer之类的类型不光重写了equals()方法,还重写了hashcode(),比如Integer就直接返回value,Float的麻烦点
猜想JVM是单核的,一时只能执行一个java程序,所以只要不多线程、自己不故意写冲突的hashcode,就不会出现不同程序的hashcode冲突的情况。但其实hashcode有没有偶尔冲突无所谓,反正冲突了也要再判断equals()。即使对象不同,hashcode也难免冲突,等复习数据结构再看吧。
之所以选31是因为31既是质数可以减少散列冲突,又有31 * i = i<<5-1好算,不过也有人质疑,不过当时这么定的就这样了
所以说equals()和hashcode()是都需要改写的,IDEA里有模板自动一起生成。只重写equals()的话,remove(new 对象)也删不掉,add(new 对象)也不算重复,都要看hashcode()。
TreeSet
- 二叉树实现,基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则compareTo(T t) 如果return this.属性-t.属性,排序会是升序;Comparable规定,实现的大于小于规则必须保证反对称性、传递性,相等要保证对称性。然而只是规定,违反不会出异常。
- 元素类不实现Comparable也行,建TreeMap的时候现new Comparator也行
- 没有compareTo()的话编译的时候检查不出来,运行起来会报ClassCastException类型转换异常
- compareTo()想“先比什么,再比什么”可以用两个比较结果的问号表达式
- TreeMap是通过compareTo()方法来确定是否为重复元素或者remove()里匹配的,hashcode()和equals()都没用了
- 红黑树本质是二叉查找树,通过红黑节点保证左右子树相对平衡,具体这里不需要太懂因为自己实现起来太麻烦
Map
Map接口的特点:
- 用于存储任意键值对(Key-Value)
- 键:无序、无下标、不允许重复(唯一)
- 值:无序、无下标、允许重复
注意到以下用到泛型就不是一个T了,因为键和值都需要泛型,有两个,所以的用K和V
| Modifier and Type | Method and Description |
|---|---|
void |
clear() 从该地图中删除所有的映射(可选操作)。 |
default V |
compute(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) 尝试计算指定键的映射及其当前映射的值(如果没有当前映射, null )。 |
default V |
computeIfAbsent(K key, Function<? super K,? extends V> mappingFunction) 如果指定的键尚未与值相关联(或映射到 null ),则尝试使用给定的映射函数计算其值,并将其输入到此映射中,除非 null 。 |
default V |
computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> remappingFunction) 如果指定的密钥的值存在且非空,则尝试计算给定密钥及其当前映射值的新映射。 |
boolean |
containsKey(Object key) 如果此映射包含指定键的映射,则返回 true 。 |
boolean |
containsValue(Object value) 如果此地图将一个或多个键映射到指定的值,则返回 true 。 |
Set<Map.Entry<K,V>> |
entrySet() 返回此地图中包含的映射的Set视图。Map.Entry<K,V>接口是Map的一个条目,即一个键值对 |
boolean |
equals(Object o) 将指定的对象与此映射进行比较以获得相等性。 |
default void |
forEach(BiConsumer<? super K,? super V> action) 对此映射中的每个条目执行给定的操作,直到所有条目都被处理或操作引发异常。 |
V |
get(Object key) 返回到指定键所映射的值,或 null如果此映射包含该键的映射。 |
default V |
getOrDefault(Object key, V defaultValue) 返回到指定键所映射的值,或 defaultValue如果此映射包含该键的映射。 |
int |
hashCode() 返回此地图的哈希码值。 |
boolean |
isEmpty() 如果此地图不包含键值映射,则返回 true 。 |
Set<K> |
keySet() 返回此地图中包含的键的Set视图。返回所有一个Set,装着所有的key |
default V |
merge(K key, V value, BiFunction<? super V,? super V,? extends V> remappingFunction) 如果指定的键尚未与值相关联或与null相关联,则将其与给定的非空值相关联。 |
V |
put(K key, V value) 将指定的值与该映射中的指定键相关联(可选操作)。key重复则覆盖原值。 |
void |
putAll(Map<? extends K,? extends V> m) 将指定地图的所有映射复制到此映射(可选操作)。 |
default V |
putIfAbsent(K key, V value) 如果指定的键尚未与某个值相关联(或映射到 null )将其与给定值相关联并返回 null ,否则返回当前值。 |
V |
remove(Object key) 如果存在(从可选的操作),从该地图中删除一个键的映射。 |
default boolean |
remove(Object key, Object value) 仅当指定的密钥当前映射到指定的值时删除该条目。 |
default V |
replace(K key, V value) 只有当目标映射到某个值时,才能替换指定键的条目。 |
default boolean |
replace(K key, V oldValue, V newValue) 仅当当前映射到指定的值时,才能替换指定键的条目。 |
default void |
replaceAll(BiFunction<? super K,? super V,? extends V> function) 将每个条目的值替换为对该条目调用给定函数的结果,直到所有条目都被处理或该函数抛出异常。 |
int |
size() 返回此地图中键值映射的数量。 |
Collection<V> |
values() 返回此地图中包含的值的Collection视图。 |
遍历访问键值对,entrySet()比keySet()+get(key)效率高,get(key)每个value都要查找一下
HashMap(重点)
-
JDK1.2版本加入,线程不安全所以只能运行在单线程,运行效率快;允许用null作为key或是value
-
初始容量是16,默认加载因子0.75(非空比重达到加载因子时扩容)的空HashMap
-
存储结构:数组+链表(JDK1.8之后+红黑树)
-
key不重复跟HashSet一样是用的hashcode()和equals()
-
域
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable { static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; static final int MAXIMUM_CAPACITY = 1 << 30; static final float DEFAULT_LOAD_FACTOR = 0.75f; static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; //JDK1.8之后,当链表长度小于6时调整成链表,链表长度大于8且数组长度大于64时调整成红黑树 static class Node<K,V> implemets Map.Entry<K,V>{ final int hash; final K key; V value; Node<K,V> next; …… transient Node<K,V>[] table;//Mapping数组 transient Set<Map.Entry<K,V>> entrySet;//Entry集合 transient int size; -
构造器
刚new HashMap()还没有put的时候只有loadFactor赋了初始值0.75,table还是null,size还是0
-
put(K key,V value)
源码比较麻烦,总之新put第一个元素进去之后table容量变成16,随便(不是)找了一个位置放进去;每到0.75扩容,每次扩容到原来两倍
jdk1.8之前链表是头插法,1.8之后是尾插法
HashMap和HashSet之间的关系
实际上HashSet里面用的是HashMap
HashSet中add(E e)实际上是map.put(e, new Object());纯用内置map的键来作HashSet,值都是dummy的
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
Hashtable和Properties
1.0版本的,线程安全、运行效率慢,不允许null作为key或value。开发基本已经不用了,了解就可以了;
然而它有一个子类叫Properties,开发过程中用得比较多,跟“流”关系紧密。它要求key和value都是String,通常用于配置文件的存取。
Hashtable初始容量11,加载因子0.75,elements()是元素枚举,keys()是键枚举
Properties类表示了一个持久的属性集,可保存在流中或从流中加载。
TreeMap
TreeSet的存储结构是红黑树,TreeMap也是红黑树,可以对元素进行自动排序。
排序显然是按照键类的compareTo()方法,因为键唯一,轮不着比值。
TreeMap和TreeSet的关系
TreeSet实现了NavigableSet接口实现了SortedSet接口,而TreeSet内部有一个transient NavigableMap<E,Object> m,new TreeSet()的时候调用TreeSet(new TreeMap<>());,把new的TreeMap对象传给内部的NavigableMap域,因为TreeMap又实现了NavigableMap接口。
所以说,TreeSet是用TreeMap的键来保存TreeSet值的。
Collections工具类
概念:集合工具类,定义了除存取以外的集合常用方法。
public static void reverse(List<?> list);//反转
public static void shuffle(List<?> list);//打乱,每次都不一样
public static void sort(List<T> list);//排序,第二参数可以传新的Comparator,据说底层用的是归并排序
API里还有二分查找、copy(要求dest的长度不小于src的长度)
数组和List互转
集合变成数组:
List有toArray()方法,里面加数组参数,如果数组长度小于等于List长度,直接返回list的数组形式;否则会返回list覆盖数组相应位置的结果,还会多带走一位变成null。
复习:Arrays工具类有个方法Arrays.toString(数组)
数组变成集合:
Arrays.asList(数组);return new ArrayList<>(a);
/**
* Returns a fixed-size list backed by the specified array. (Changes to
* the returned list "write through" to the array.) This method acts
* as bridge between array-based and collection-based APIs, in
* combination with {@link Collection#toArray}. The returned list is
* serializable and implements {@link RandomAccess}.
*
* <p>This method also provides a convenient way to create a fixed-size
* list initialized to contain several elements:
* <pre>
* List<String> stooges = Arrays.asList("Larry", "Moe", "Curly");
* </pre>
*
* @param <T> the class of the objects in the array
* @param a the array by which the list will be backed
* @return a list view of the specified array
*/
@SafeVarargs
@SuppressWarnings("varargs")
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
但是这样得到的ArrayList不支持增删,会报UnsupportedOperationException。(这大概是因为返回的类型其实是List,没有实现增删方法。不对,List接口会被ArrayList实现,UnsupportedOperationException是走别的路抛出的。发现add()方法走的是AbstractList类而不是ArrayList类,AbstractList是ArrayList的父类。。。。)
惊奇地发现,这里的所谓ArrayList竟然是Arrays的内部类,跟外面那个ArrayList不是一个东西,并没有重写自己父类AbstractList的add方法,只是有部分ArrayList的方法它也可以用而已。这就是ArrayList引用不能指向Arrays.asList(数组)的原因。
int[] aa = {1,2,3};
List<int> bb = Arrays.asList(aa);
List
复习:...是可变参数,是用数组实现的,可以不套数组壳子直接装元素
LinkedHashSet
用法和HashSet一模一样,不同在于它有序

