

面试过程中,问到JVM一脸懵逼,在github看了一些文章,感觉质量不错,整理了一下希望大家不吝赐教。
目前主流的jdk采用解释与编译混合执行的模式,其JIT技术采用分层编译,极大地提升了Java的执行速度
刚学习Java的时候,提到Java是一次编写,到处运行”(Write once, run anywhere),当时只是粗略记住了,那么怎么实现的呢?
1.如何实现跨平台?
首先,计算机工程领域任何问题,都可以通过增加一个中间层来解决。Java的中间码就是“字节码(Bytecode)”,Java所有的指令有200个左右一个字节可以存储256种不同指令的信息。代码执行过程中,JVM将字节码解释执行,屏蔽对底层操作系统的依赖,JVM也可以将字节码编译执行,如果是热点代码,会通过JIT动态地编译为机器码,提高执行效率。
2.字节码的执行流程
字节码必须通过类加载到JVM环境中,才可以执行。执行有三种模式:
1.解释执行
2.JIT编译执行
3.JIT编译与解释混合(大多数主流JVM采用的方案)
混合执行模式的优势在于解释器在启动时先解释执行,省去编译时间。随着时间推进,JVM通过热点代码统计分析,识别高频方法的调用、循环体、公共模块等,基于强大的JIT动态编译技术,将热点代码转换成机器码,直接交给CPU执行。JIT作用就是将字节码动态地编译成可以直接发送给处理器指令执行的机器码。
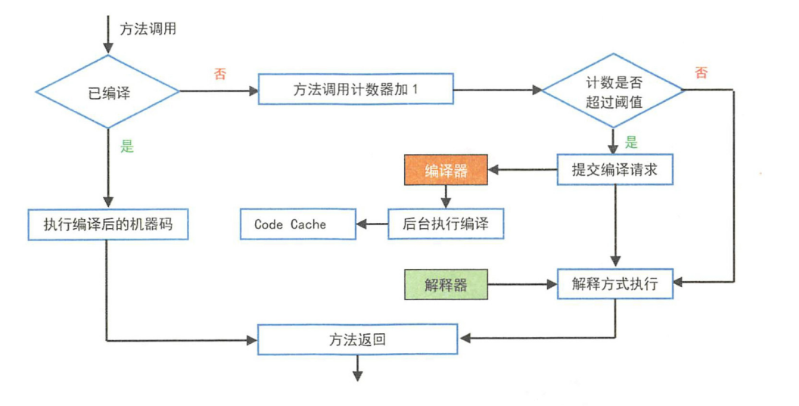
即时编译流程
3.类怎么加载的(双亲委派机制)
首先,低层次的当前类加载器,不能覆盖更高层次类加载器已将加载的类。如果低层次的类想加载一个未知类,要非常礼貌的向上级询问:请问这个类已经加载了吗? 被询问的高层次类加载器会自问两个问题:
- 我是否已经加载过此类?
- 如果没有可否加载此类
如果回答都是否定的,才可以加载这个未知类。
4.JVM调优的原则
- GC的时间足够小
- GC的次数足够少
- 发生Full GC的周期足够长
前两个是相悖的,要想GC时间小必须要一个更小的堆,要保证GC的次数足够少,必须保证更大的堆,只能取其平衡
(1)针对JVM堆的设置,通过 -Xms -Xmx 限定其最小值和最大值,为了防止,垃圾收集器在最小最大之间收缩堆而产生额外的时间,通常把最大最小设为相同的值
(2) 年轻代和老年代将根据默认的比例(1:2)分配堆内存,可以通过调整二者之间的比率NewRadio调整二者的大小。
(3)年轻代和老年代设置多大才算合理?
没有固定答案。
整个JVM内存大小 = 年轻代大小 + 老年代大小 + 持久代大小。
持久代大小一般为64M,增大年轻代后,将会减小老年代的大。此值对系统性能影响较大,Sun官方推荐将年轻代调整为整个堆的 3/8
(4)配置较好的机器上(多核,大内存),可以为老年代选择并行收集算法 -XX:+UseParallelOldGC ,默认为 Serial 收集
(5) 线程堆栈的设置:每个线程默认会开启1M的堆栈。用于存放栈帧、调用参数、局部变量等,减小这个值能生成更多的的线程,但操作系统对一个进程内的线程数有限制,不能无限生成,一般在3000~5000左右
5. 对象分配规则
- 对象优先分配在Eden区,如果Eden区没有足够的空间时,虚拟机执行一次Minor GC.
- 大对象直接进入老年代(大对象是指需要大量连续内存空间的对象)。避免在Eden区和Survior区之间发生大量的内存拷贝
- 长期存活的对象进入老年代。虚拟机为每个对象定义了一个年龄计数器,对象经过一次Monior GC对象会进入Survivor区,之后每经过一次Minor GC那么对象年龄增加1,直到达到阀值后进入老年代
- 动态判断对象的年龄。如果Survivor区中有相同年龄的对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象直接进入老年代。
- 空间分配担保。每次进行Monitor GC时,JVM会计算Survivor区移动至老年区的对象的平均大小,如果这个值大于老年区的剩余值的大小则进行一次 Full GC,如果小于就检查HandlerPromonitorFailure设置,如果true则只进行Monitor GC,false则进行Full GC

 浙公网安备 33010602011771号
浙公网安备 33010602011771号