Django全文搜索框架haystack 和 drf_haystack
DRF和django的全文搜索的安装配置基本一致,DRF使用drf_haystack,django使用django-haystack。只有路由、视图类等方面有不同,即1、安装和配置;2、指明要索引的字段和;3、编辑search_indexes.py文件;基本操作是一致的。
1、安装和配置
# 安装
pip install whoosh
pip install jieba
pip install django-haystack
pip install drf_haystack
配置:
# 在INSTALL_APPS里加上 haystack (加在最后)
INSTALLED_APPS = [
...
'haystack',
...
]
# 增加搜索引擎配置(有solr,whoosh,elastic search),这里选择whoosh
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'),
},
}
#或者
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://192.168.xxx.:9200/', # Elasticsearch服务器ip地址,端口号固定为9200
'INDEX_NAME': 'tensquare', # Elasticsearch建立的索引库的名称
},
}
# 配置自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
# 配置搜索结果的分页器的每页数量(rest-framework里面用不到)
# HAYSTACK_SEARCH_RESULTS_PER_PAGE = 10
如果想使用jieba分词:
1、新建ChineseAnalyzer.py文件,建在和whoosh_cn_backend.py相同的目录内
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
2、将 haystack.backends.whoosh_backend.py 文件复制出来,找一个地方放,改名为 whoosh_cn_backend.py,其实和whoosh_backend.py放同一个目录也可以
3、向whoosh_cn_backend.py添加from jieba.analyse import ChineseAnalyzer
4、将whoosh_cn_backend.py中所有的 StemmingAnalyzer 改为 ChineseAnalyser
5、把 HAYSTACK_CONNECTIONS 里面的路径改一下即可。
我的改完之后是:
HAYSTACK_CONNECTIONS = {
'default': {
# 'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'ENGINE': 'extra_apps.whoosh_cn_backend.WhooshEngine',
'PATH': os.path.join(os.path.dirname(__file__), 'whoosh_index'),
},
}
2、指明要索引的字段
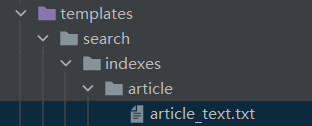
创建上图所示路径及文件
# 创建文件 templates/search/indexes/myapp/note_text.txt
# myapp是想要建立索引的app,note是你要建立缩印的那个模型名字(小写)
# txt文件内容:将title、content、和id三个字段添加到索引
{{ object.title }}
{{ object.content }}
{{ object.id }}
3、编辑search_indexes.py文件
# 在app中新建search_indexes.py文件,并编辑以下内容
from haystack import indexes
from .models import Article
class ArticleIndex(indexes.SearchIndex, indexes.Indexable):
"""
Article索引数据模型类
"""
text = indexes.CharField(document=True, use_template=True)
id = indexes.IntegerField(model_attr='id')
title = indexes.CharField(model_attr='title')
content = indexes.CharField(model_attr='content')
# 下面的createtime字段并没有在上面加索引,写上是因为后面的过滤filter和排序order_by用到
# 注意:这里修改的话一定要重新建立索引,才能生效。python manage.py rebuild_index
createtime = indexes.DateTimeField(model_attr='createtime')
def get_model(self):
"""返回建立索引的模型类"""
return Article
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
return self.get_model().objects.all()
配置完成后别忘了通过通过python manage.py rebuild_index 命令,生成我们的索引文件
DRF
前三步完成后进行DRF中的序列化器、路由和视图的操作
4、编辑索引的serializer序列化器
# 在serializer.py文件中进行编辑
class ArticleIndexSerializer(HaystackSerializer):
"""
Article索引结果数据序列化器
"""
class Meta:
index_classes = [ArticleIndex]
fields = ('text', 'id', 'title', 'content', 'createtime')
# 这里可以写ignore_fields来忽略搜索那个字段
5、编辑视图
class ArticleSearchViewSet(HaystackViewSet):
"""
Article搜索
"""
index_models = [Article]
serializer_class = ArticleIndexSerializer
6、别忘了编辑路由
router.register('articles/search', views.ArticleSearchViewSet, base_name='articles_search')
Django
前三步完成后,进行Django中视图和路由操作
4、编辑路由
路由:
# 要注意路由中没有as_view
path('articles/search/', views.MySearchView()),
5、编辑视图
视图:
# 导入:
from haystack.views import SearchView
class MySearchView(SearchView):
'''重写SearchView类'''
# 指明每页显示 3个
results_per_page = 3
# 重写 父类 create_response == >JsonResponse
def create_response(self):
# 搜索引擎 给我的数据
context = self.get_context()
page = context.get('page')
object_list = page.object_list
data_list = []
all_pages = context['page'].paginator.num_pages
for article in object_list:
data_list.append({
'id': article.object.id,
'title': article.object.title,
'createtime': article.object.createtime,
'content': article.object.content,
'text': context.get('query'), # 所查询的关键字
# 'all_pages': context['page'].paginator.num_pages, # 总页数
# 'count': context['page'].paginator.count # 每页个数
})
# 因为前端向后端要前一页和后一页的地址,所以手动传给前端
text = context.get('query')
if int(page.number) < int(all_pages):
# next = f'http://127.0.0.1:8000/article/-1/channel/?page={str(int(page.number) + 1)}'
next = f'http://127.0.0.1:8080/search.html?keyword={text}&page={str(int(page.number) + 1)}'
else:
next = None
if int(page.number) > 1:
previous = f'http://127.0.0.1:8080/search.html?keyword={text}&page={str(int(page.number) - 1)}'
else:
previous = None
# return JsonResponse(data_list, safe=False)
return JsonResponse({'count': len(context), 'next': next, 'previous': previous, 'results': data_list})
提醒:
默认传参的关键字是q,即q=利物浦,才可以,想不使用q则需要自定义,如何进行自定义,我也不晓得。。。谁知道了拜托教教我,谢啦
参考了:https://blog.csdn.net/smartwu_sir/article/details/80209907

 浙公网安备 33010602011771号
浙公网安备 33010602011771号