
python之路之正则表达式
匹配格式
^ 匹配字符串的开头
$ 匹配字符串的结尾
. 除了换行符外的所有字符
[...] 用来表示一组字符,,单独列出:[amk]匹配'a','m'或'k'
[^..] 不在[]中的字符:[^abc]匹配除了a,b,c之外的字符
* 匹配0个或多个
+ 匹配1个或多个
? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
{n,} 精确匹配n个前面的表达式
{n,m} 匹配n到m次由前面的正则表达式定义的片段,贪婪方式
a|b 匹配a或b
() 匹配括号内的表达式,也表示一个组
\w 匹配字母数字
\W 匹配非字母数字
\s 匹配任意空白符
\S 匹配任意非空白符
\d 匹配任意数字
\D 匹配任意非数字
\A 匹配字符串开始
\Z 匹配字符串结束,如果存在换行,只匹配换行前的结束字符串
\z 匹配字符串结束
\G 匹配最后匹配完成的位置
\b 匹配一个单词的边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界,'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'
\n 匹配一个换行符
\t 匹配一个制表符
\1..\9 匹配第n个分组的子表达式
正则表达式常用5种操作:
re.match(pattern,string) #从字符串的开头开始匹配,匹配必须与字符串的开头一致,返回一个匹配值
re.search(pattern,string) #从字符串的任意位置匹配,返回一个匹配值
re.split() #按匹配分隔字符串,默认为空格
re.findall(pattern,string) #找到所有的匹配,返回列表
re.sub(pattern,repl,string,count) #找到所有匹配,并替换掉
一:match的使用方法:从字符串的开头开始匹配
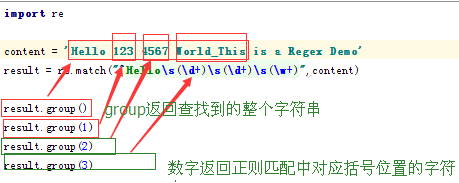
贪婪匹配:.* 使自己尽量获取最多的值
与非贪婪匹配:.*? 使大家都可以获取最多的值

匹配模式:
S可以使.匹配新行,即使.可以匹配任意字符
import re content = """Hello 1234567 World_This is a Regex Demo""" result = re.match("^He.*?(\d+).*?Demo$",content,re.S) print(result.group()) print(result.group(1)) 结果: vHello 1234567 World_This is a Regex Demo 1234567
match的缺点:从字符串的开头匹配,开头必须一致

二、search:在字符串的任意位置查找,返回一个匹配值
import re content = """Extra strings Hello 1234567 World_This is a Regex Demo Exit""" result = re.search("He.*?(\d+).*?Demo",content) print(result.group()) print(result.group(1)) 结果: Hello 1234567 World_This is a Regex Demo 1234567
三、sub:查找并替换

其它链接:http://blog.csdn.net/whycadi/article/details/2011046
https://www.cnblogs.com/whaozl/p/5462865.html


