
flume传输日志文件到HDFS过程讲解
Flume定义:
Flume是Cloudera提供的一个高可用的、高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构, 灵活简单。
为什么选用Flume
主要作用: 实时读取服务器本地磁盘的数据, 将数据写入到HDFS
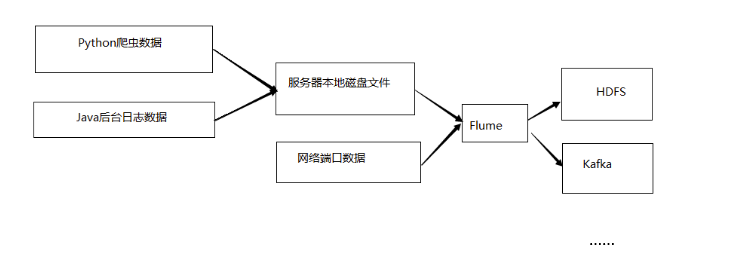
Flume的组织架构
最简单的组织架构, 单agent
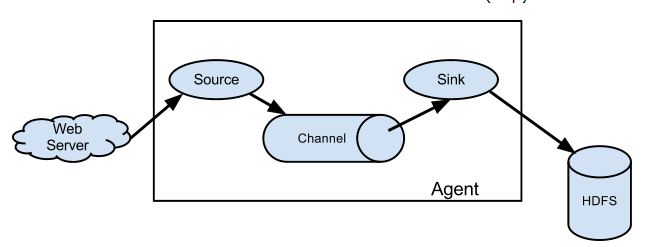
Flume流式处理过程
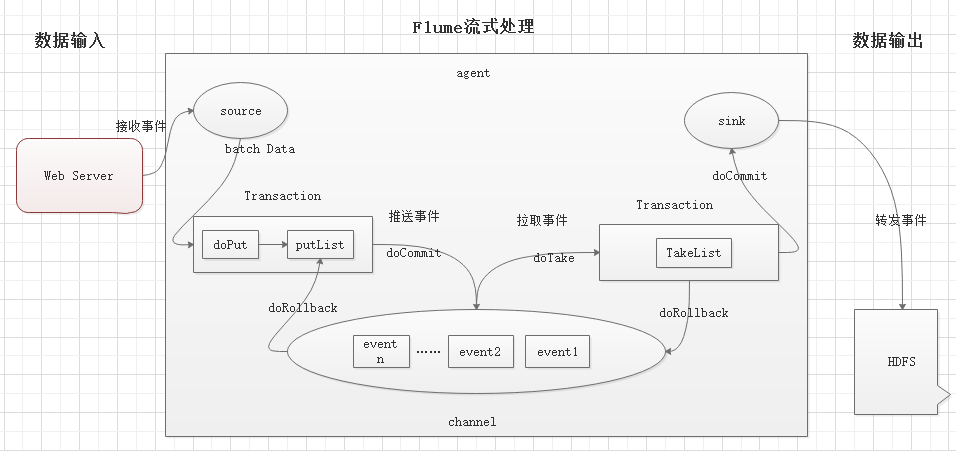
说明:
source: 数据输入端
常见类型: spooling directory, exec, syslog, avro, netcat等
channel:位于source和sink之间的缓冲区
memory: 基于内存缓存, 允许数据有丢失
file: 持久化channel, 系统宕机不会丢失数据
sink: 数据输出端
常见的目的地有: HDFS, Kafka, logger, avro, File, 自定义
Put事务流程:
doPut: 将批数据写入临时缓冲区putList
doCommit: 检查channel内存队列是否足够合并
doRollback: 内存队列空间不足, 回滚数据
Take事务流程:
doTake: 将批数据提取到临时缓冲区takeList
doCommit: 如果数据全部发送成功, 则清空临时缓冲区takeList
doRollback: 如果数据发送过程中出现异常, 则将临时缓冲区takeList中数据返还给channel
多agent
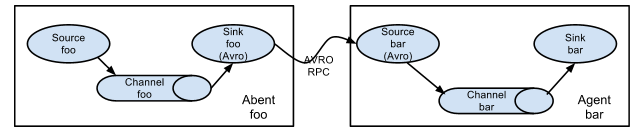
事件流多路传输到一个或多个目标, 通过定义一个流复用器来实现.
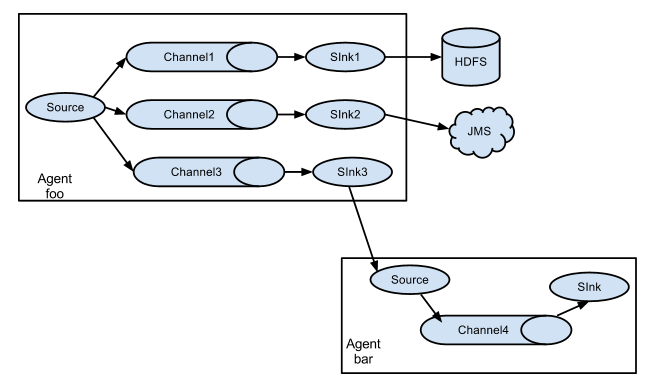
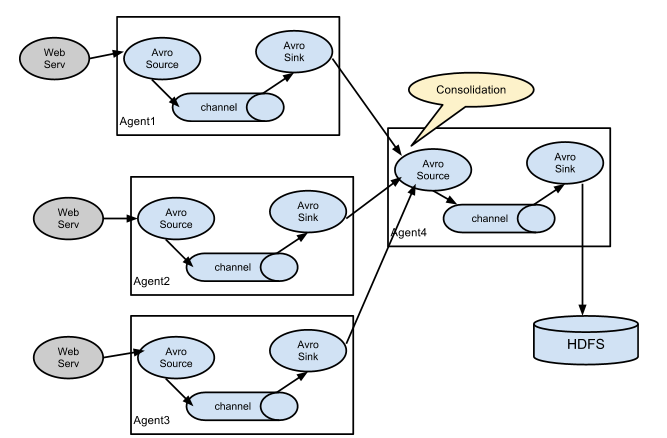
多路日志收集型
Flume安装
Flume官网地址: http://flume.apache.org/
文档地址: http://flume.apache.org/FlumeUserGuide.html
下载地址: http://flume.apache.org/download.html
安装步骤:
1、将apache-flume-1.7.0-bin.tar.gz上传到/opt/software目录下
2、解压到/opt/module目录下
# tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3、将目录apache-flume-1.7.0-bin改为名flume
# mv apache-flume-1.7.0-bin flume
4、将flume-env.sh.template改名为flume-env.sh, 并修改其配置
# mv flume/conf/flume-env.sh.template flume/conf/flume-env.sh
# vi flume/conf/flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_161
5、验证安装是否成功
# flume/bin/flume-ng version
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523
实时读取本地文件到HDFS
1、flume必须持有hadoop相关的包才能将数据输出到hdfs, 将如下包上传到flume/lib下
涉及到的包如下, 以hadoop-2.9.2为例:
commons-configuration-1.6.jar
commons-io-2.4.jar
hadoop-auth-2.9.2.jar
hadoop-common-2.9.2.jar
hadoop-hdfs-2.9.2.jar
hadoop-hdfs-client-2.9.2.jar
htrace-core4-4.1.0-incubating.jar
stax2-api-3.1.4.jar
woodstox-core-5.0.3.jar
2、修改/etc/hosts, 加入hadoop的地址
10.xx.xx.xx hadoo
3、创建配置文件flume-file-hdfs.conf
# cd flume/
# mkdir jobs
# touch jobs/flume-file-hdfs.conf
4、添加内容如下
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source #定义source为可执行命令 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /opt/module/flume/logs/flume.log #执行shell脚本的绝对路径 a1.sources.r1.shell = /bin/bash -c # Describe the sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop:9000/flume/%Y%m%d/%H #上传文件的前缀 a1.sinks.k1.hdfs.filePrefix = logs- #是否按照时间滚动文件 a1.sinks.k1.hdfs.round = true #多少时间单位创建一个新文件夹 a1.sinks.k1.hdfs.roundValue = 1 #时间单位 a1.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a1.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个event才flush一次hdfs a1.sinks.k1.hdfs.batchSize = 100 #文件类型, 是否压缩 a1.sinks.k1.hdfs.fileType = DataStream #多久生成一个新文件 a1.sinks.k1.hdfs.rollInterval = 60 #每个文件的大小 a1.sinks.k1.hdfs.rollSize = 10240 #文件的滚动与event数量无关 a1.sinks.k1.hdfs.rollCount = 0 #最小冗余 a1.sinks.k1.hdfs.minBlockReplicas = 1 # Use a channel which buffers events in memory a1.channels.c1.type = memory # 容量 a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
5、启动flume
# bin/flume-ng agent --conf conf/ --conf-file jobs/flume-file-hdfs.conf --name a1 -Dflume.root.logger=DEBUG,console
6、查看hdfs系统文件是否接收到文件
# hdfs dfs -ls /flume
Found 1 items
drwxr-xr-x - root supergroup 0 2020-04-02 22:37 /flume/20200402
flume传输日志文件到hdfs成功了。
友情提示:
hadoop伪分布部署: https://www.cnblogs.com/kongzhagen/p/6872297.html


