


python3在极端网络波动下的智能判断下载

作者: 孔扎根
简介: 工作13余载,现任高级爬虫工程师,在工作中积累了丰富的数据库、ETL及python开发方面的经验。
座佑铭:美的东西都喜欢, 好的东西都想要, 美好的东西是我追求的目标
Python是一种跨平台的计算机编程语言。是一种面向对象的动态类型语言,Python的设计哲学是“优雅”、“明确”、“简单”,随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
本篇文章产生的背景是源于公司的一个项目"数字大屏",从公司的服务器下载图片后, 对图像进行处理, 本篇记录了其中的一个小知识点, 在极端网络波动下的图片智能下载处理,我们知道网络稳定顺畅时一切下载都很顺利, 程序结束的很完美,你开心我也开心^_^哈哈。但是图片往往都比较大,当偶尔网络极其慢的时候下载一张图片可能需要很久的时间,而此时业务还要求你不能等太长时间, 怎么办呢? 此时我们可能就希望你不要再下载了, 中断吧……, 我再想想其它法…^_^.
别瞎叨叨了, 说正事...
在使用python3下载图片时, 常用的方法有urlretrieve和requests两种, 但是不管哪种方法在网速极慢的情况下, 都会出现图片下载卡住现象。那如何解决呢? 小编总结了几种常用的图片下载方法及中断下载的方法, 记录了一段寻找最佳方法的心路历程。
方法一、socket: 设置默认超时
正常网速时下载情况是什么样子呢?
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # __author__:kzg import datetime import os from urllib.request import urlretrieve
# 函数运行计时器 def count_time(func): def int_time(*args, **kwargs): start_time = datetime.datetime.now() # 程序开始时间 func(*args, **kwargs) over_time = datetime.datetime.now() # 程序结束时间 total_time = (over_time-start_time).total_seconds() print("download picture used time %s seconds" % total_time) return int_time
# 下载回调函数, 计算下载进度 def callbackinfo(down, block, size): ''' 回调函数: down:已经下载的数据块 block:数据块的大小 size:远程文件的大小 ''' per = 100.0 * (down * block) / size if per > 100: per = 100 print('%.2f%%' % per)
# 图片下载 @count_time def downpic(url, filename): try: print("Start Down %s" % url) if os.path.exists(filename): os.remove(filename) urlretrieve(url, filename, callbackinfo) except socket.timeout as ex: print(ex) url = "http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20" filename = r'C:\blueprint-face-detection\scripts\mv.jpg' downpic(url, filename) 结果: Start Down http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20 0.00% 7.01% 14.02% 21.03% 28.04% 35.05% 42.06% 49.07% 56.08% 63.09% 70.10% 77.11% 84.12% 91.13% 98.14% 100.00% download picture used time 0.165558 seconds
结论: 网速较快时下载完全没问题, 仅用零点几秒。
如果把图片下载速度降低, 那下载完图片的整体时间会拉长, 如果网速特别低,那下载完图片的时候会无限延长。
那试试在限制网速的情况下, 下载图片会出现什么现象呢, 如结论所说的那样吗?
2、使用charles限制网速, 设置为下载1k/s, 上传10k/s
1、设置一下charles吧

2、设置socket的默认超时时间为10秒
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __author__:kzg
import datetime
import os
import socket
from urllib.request import urlretrieve
# 函数运行计时器
def count_time(func):
def int_time(*args, **kwargs):
start_time = datetime.datetime.now() # 程序开始时间
func(*args, **kwargs)
over_time = datetime.datetime.now() # 程序结束时间
total_time = (over_time-start_time).total_seconds()
print("download picture used time %s seconds" % total_time)
return int_time
# 下载回调函数, 计算下载进度
def callbackinfo(down, block, size):
'''
回调函数:
down:已经下载的数据块
block:数据块的大小
size:远程文件的大小
'''
per = 100.0 * (down * block) / size
if per > 100:
per = 100
print('%.2f%%' % per)
# 图片下载
@count_time
def downpic(url, filename):
try:
print("Start Down %s" % url)
if os.path.exists(filename):
os.remove(filename)
urlretrieve(url, filename, callbackinfo)
except socket.timeout as ex:
print(ex)
url = "http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20"
filename = r'C:\blueprint-face-detection\scripts\mv.jpg'
# 设置10秒超时
socket.setdefaulttimeout(10)
downpic(url, filename)
结果: Start Down http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20 timed out download picture used time 10.013625 seconds
结论: 正如期望的那样, 10秒种后socket超时报出错误,urlretrieve下载过程被迫中断,进而捕获错误信息打印出来。
又重试了3次, 每次都好使, 好高兴 ^_^
那再猜想一下, 如果把网速提高一些呢, 应该更没问题了!!!, 下载速度设置为10k/s, 上传10k/s 。
看图:
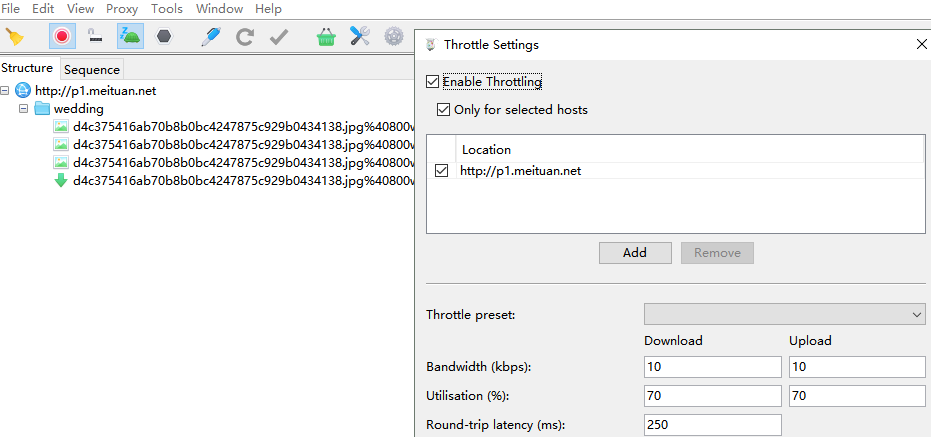
运行一下:

完啦, 擦擦擦, 这是什么情况, 网速提高了, 10秒钟早过了, 按说下载应该结束才对, 这都过半分钟了咋还在运行呢?
经过多次尝试发现下载速度超过4k/s时, socket设置defaulttime好像就不起作用了, 图片下载不能被中断, 由此可见想用此方法在任何情况下完全做到强制中断图片下载是不行的。
那咱办呀,要不要在一颗树上吊死呀,那就个换个方法试试呗。
方法二、线程
一说到线程, 想到最多的可能就是父子线程了,主线程结束子线程也跟着结束,听着感觉很完美, 这个咱也会呀,啥不说了, 上代码看看效果吧。
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# __author__:kzg
import threading
import os, datetime, time
from urllib.request import urlretrieve
# 回调函数
def callbackinfo(down, block, size):
'''
回调函数:
down:已经下载的数据块
block:数据块的大小
size:远程文件的大小
'''
per = 100.0 * (down * block) / size
if per > 100:
per = 100
print('%.2f%%' % per)
# 计时器
def count_time(func):
def int_time(*args, **kwargs):
start_time = datetime.datetime.now() # 程序开始时间
func(*args, **kwargs)
over_time = datetime.datetime.now() # 程序结束时间
total_time = (over_time-start_time).total_seconds()
print("download picture used time %s seconds" % total_time)
return int_time
# 图片下载函数
@count_time
def downpic(url):
print("Start Down %s" % url)
if os.path.exists(filename):
os.remove(filename)
urlretrieve(url, filename, callbackinfo)
# 子线程
def mainFunc(funcname, args):
t = threading.Thread(target=funcname, args=(args,))
t.start()
t.join(10) # 子线程阻塞10秒
url = "http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20"
filename = r'C:\blueprint-face-detection\scripts\mv.jpg'
# 主线程
m = threading.Thread(target=mainFunc, args=(downpic, url))
m.setDaemon(True)
m.start()
m.join() # 10秒后取消子线程阻塞, 主线程不阻塞立即运行后面程序
print("m is alive? ", m.is_alive())
time.sleep(10)
os.remove(filename)
将下载速度分别限制在1k/st和10k/s,结果如下
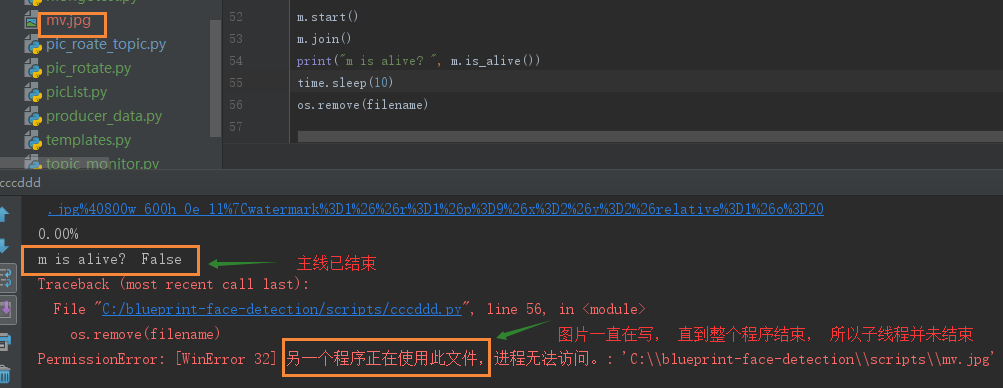
结论: 主线程已经结束, 但子线程并未结束, 图片下载在持续中, 直到整个程序结束后, 下载被中断。所以通过父线程结束子线程也结束的方法来强制图片中断下载是不可行的。
这下可惨啦, 没办法实现了吗? 于是乎在网上找呀找, 终于看到有人也遇到了这类问题, 怎么解决呢? 。。。。 强制中断线程, 听起来很霸气,那咱也跟着试试吧, 上代码。
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # __author__:kzg import threading import os, datetime, time import ctypes import inspect from urllib.request import urlretrieve # 回调函数 def callbackinfo(down, block, size): ''' 回调函数: down:已经下载的数据块 block:数据块的大小 size:远程文件的大小 ''' per = 100.0 * (down * block) / size if per > 100: per = 100 print('%.2f%%' % per) # 计时器 def count_time(func): def int_time(*args, **kwargs): start_time = datetime.datetime.now() # 程序开始时间 func(*args, **kwargs) over_time = datetime.datetime.now() # 程序结束时间 total_time = (over_time-start_time).total_seconds() print("download picture used time %s seconds" % total_time) return int_time # 图片下载函数 @count_time def downpic(url): print("Start Down %s" % url) if os.path.exists(filename): os.remove(filename) urlretrieve(url, filename, callbackinfo) def _async_raise(tid, exctype): """raises the exception, performs cleanup if needed""" tid = ctypes.c_long(tid) if not inspect.isclass(exctype): exctype = type(exctype) res = ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, ctypes.py_object(exctype)) if res == 0: raise ValueError("invalid thread id") elif res != 1: # """if it returns a number greater than one, you're in trouble, # and you should call it again with exc=NULL to revert the effect""" ctypes.pythonapi.PyThreadState_SetAsyncExc(tid, None) raise SystemError("PyThreadState_SetAsyncExc failed") def stop_thread(thread): _async_raise(thread.ident, SystemExit) url = "http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20" filename = r'C:\blueprint-face-detection\scripts\mv.jpg' # 开启线程下载图片 t = threading.Thread(target=downpic, args=(url,)) t.start() t.join(10) # 强制结束线程 if t.is_alive(): stop_thread(t) time.sleep(3) print("thread is alive?", t.is_alive()) os.remove(filename)
结论:
下载速度设置为1k/s, 8k/s, 10k/s, 15k/s时, 结果如下,跟预期结果一致(重试几次结果一致)

下载速度设置为3k/s,12k/s时结果如下(重试几次结果一致)
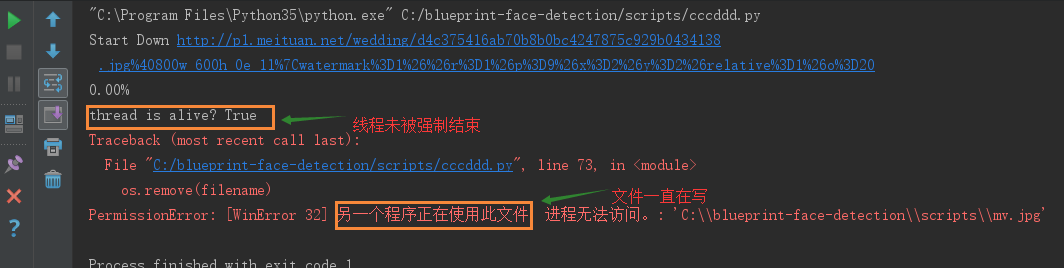
似乎看出点什么了吧, 为什么同一个程序, 不同网速下执行结果不一致呢?因实现网速我们是无法控制的,所以此方法大部分情况下都是可以的, 但也会出现例外。
python下载图片时, 每次下载8k, 下载完就会写入一次文件。
方法三、 request
timeout 仅对连接过程有效,与响应体的下载无关。 timeout 并不是整个下载响应的时间限制,而是如果服务器在 timeout 秒内没有应答,将会引发一个异常(更精确地说,是在 timeout 秒内没有从基础套接字上接收到任何字节的数据)。
换句话说: 如果在timeout时间内没有返回任何字节数据, 则request会报错退出, 如果在timeout时间内收到了任何字节的数据, 则request会一直下载, 直到响应体被下载完。
1、正常网速下的现象
# -*- coding: utf-8 -*-
import requests
import datetime
url = "http://p1.meituan.net/wedding/d4c375416ab70b8b0bc4247875c929b0434138.jpg%40800w_600h_0e_1l%7Cwatermark%3D1%26%26r%3D1%26p%3D9%26x%3D2%26y%3D2%26relative%3D1%26o%3D20"
filename = r'C:\blueprint-face-detection\scripts\meinv.jpg'
# 计时器
def count_time(func):
def int_time(*args, **kwargs):
start_time = datetime.datetime.now() # 程序开始时间
func(*args, **kwargs)
over_time = datetime.datetime.now() # 程序结束时间
total_time = (over_time-start_time).total_seconds()
print("download picture used time %s seconds" % total_time)
return int_time
@count_time
def downpic(url):
ret = requests.get(url)
print("req status is: ", ret.status_code)
with open(filename, 'wb') as fp:
print("start write picture..")
fp.write(ret.content)
downpic(url)
结果:
req status is: 200
start write picture..
download picture used time 0.26226 seconds
结论: 正常网速下, request请求成功了, 美女0.3秒被成功请出。
1、将网速限制在100k/s,结果如何呢 ?
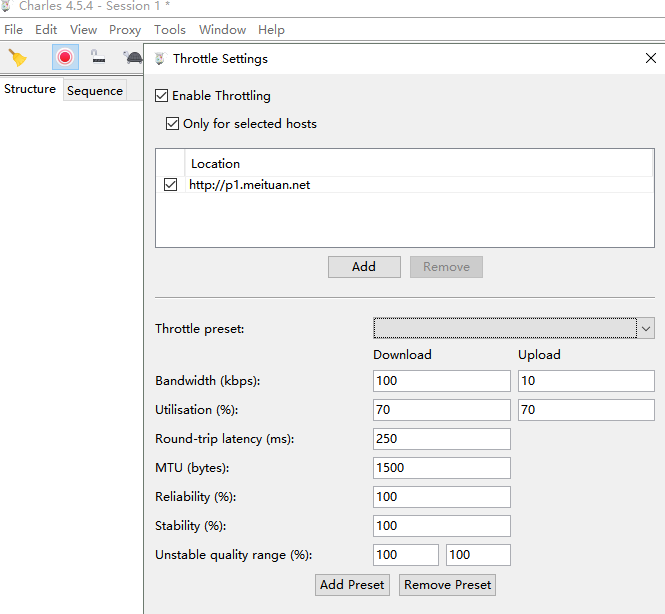

结论: 下载速度为100k/s时, request也成功了, 美女经过15.6秒被成功请出来。
2. 将网速限制在50k/s,结果如何呢?
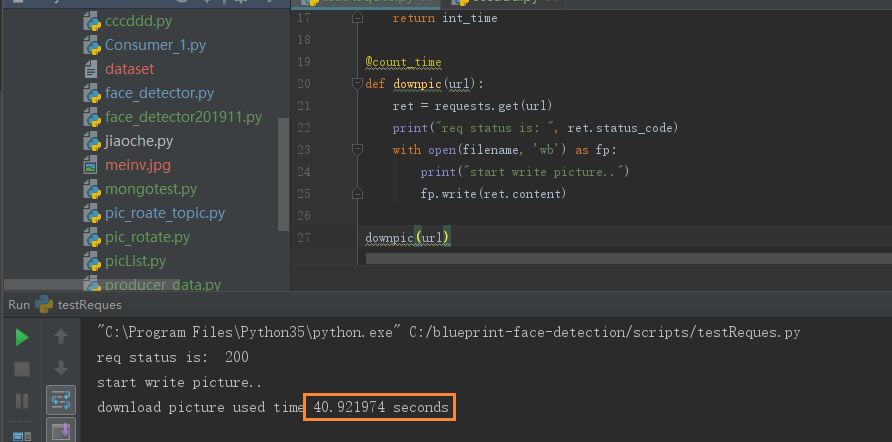
结论: 下载速度为50k/s时, request也成功了, 美女经过40.9秒被成功请出来。 设置timeout=3, 是否会生效呢?
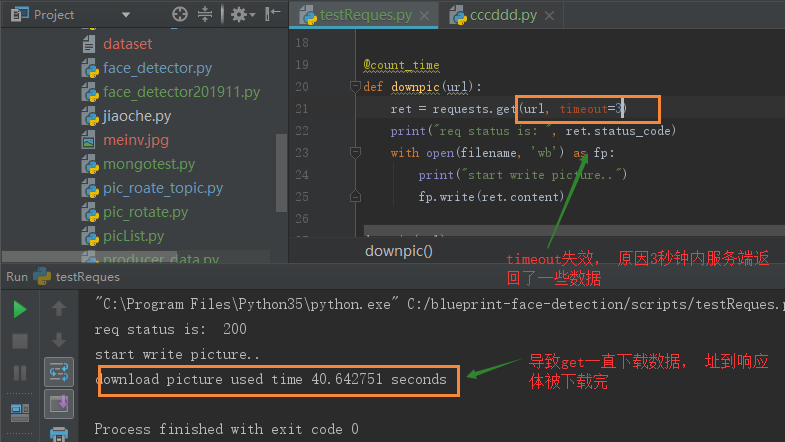
感觉要绝望了,咋整呀? 没有一种方法可以及时中断下载吗?经过不断的尝试终于找到了一个可行的方法。
函数中断 !!! 如果超过设定时间则正在下载的函数被中断, 试一下吧。
# #!/usr/bin/python3 # # -*- coding: utf-8 -*- import requests import datetime from func_timeout import func_set_timeout, FunctionTimedOut url = "http://pic1.win4000.com/wallpaper/5/58b3b56d0a0a7.jpg" @func_set_timeout(10) def downpic(url): ret = requests.get(url) print("Start Down %s" % url) if ret.status_code == 200: with open('meinv.jpg', 'wb') as fp: fp.write(ret.content) print("downLoad pic ok %s" % url) print(datetime.datetime.now()) downpic(url) print(datetime.datetime.now())
运行一下程序, 正常网速时下载一张图片的时间是多少 !
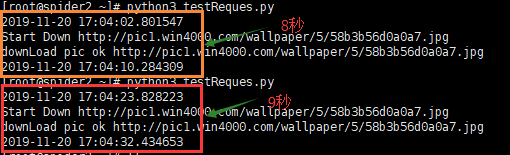
可以看出大概8秒时间可以下载完一张图片, 那我将时间设置为5秒, 那图片下载会被中断,肯定下不完。

正如预料的那样, 5秒钟后图片下载被中断了, 经过多次检查, 图片并没有继续下载, 证明图片下载被中断成功。
哈……


