


kafka Auto offset commit faild reblance
今天在使用python消费kafka时遇到了一些问题, 特记录一下。
场景一、
特殊情况: 单独写程序只用来生产消费数据
开始时间: 10:42
Topic: t_facedec
Partition: 1
程序启动: 168 启动consumer, 158启动consumer, windows机器producer推数据
运行时长: 15分钟
结果:
1、168的consume暂停,158的consumer一直消费
2、10:46分producer停止后重启推数, 158停止消费又开始消费
3、10:49分停止168、158的consumer并按顺序重启, 168消费一些数据之后158开始一直消费
4、后启动的consumer在消费数据
场景二、
特殊场景: 上线程序, 包含人脸识别处理
开始时间: 11:00
Topic: t_facedec
Partition: 1
1、11:46 启动168的conumer消费, 6分钟后日志如下, 未见异常信息
场景二、
特殊场景: 上线程序, 包含人脸识别处理
开始时间: 11:00
Topic: t_facedec
Partition: 1
1、11:46 启动168的conumer消费, 6分钟后日志如下, 未见异常信息
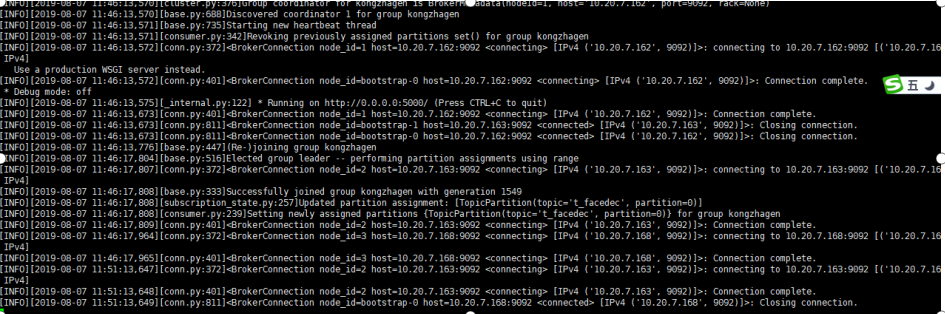
2、 11:53启动158的consumer, 日志如下, 未见异常, 158的consumer加入了组kongzhagen

3、168的consumer发出警告, 心跳失败,因组正在重新平衡

4、windows端启动producer, 168的consumer开始消费数据, 158的consumer没有消费数据
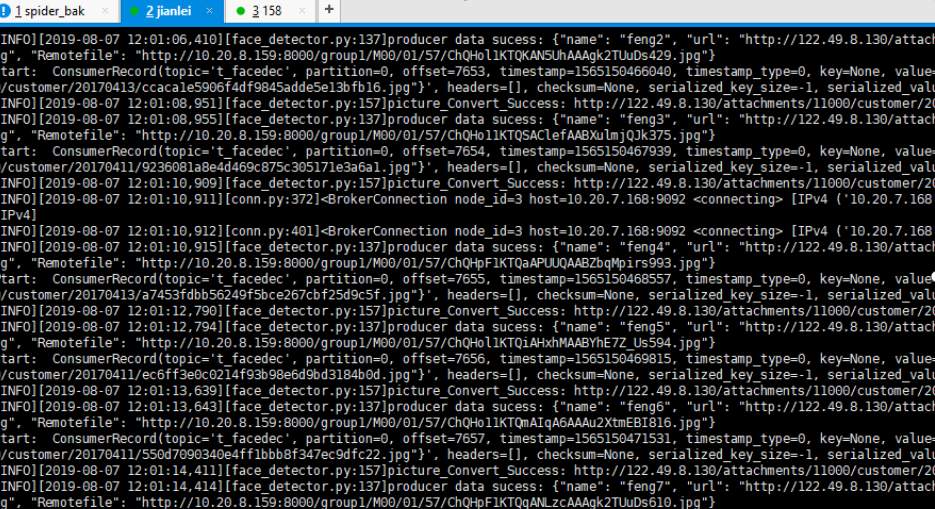
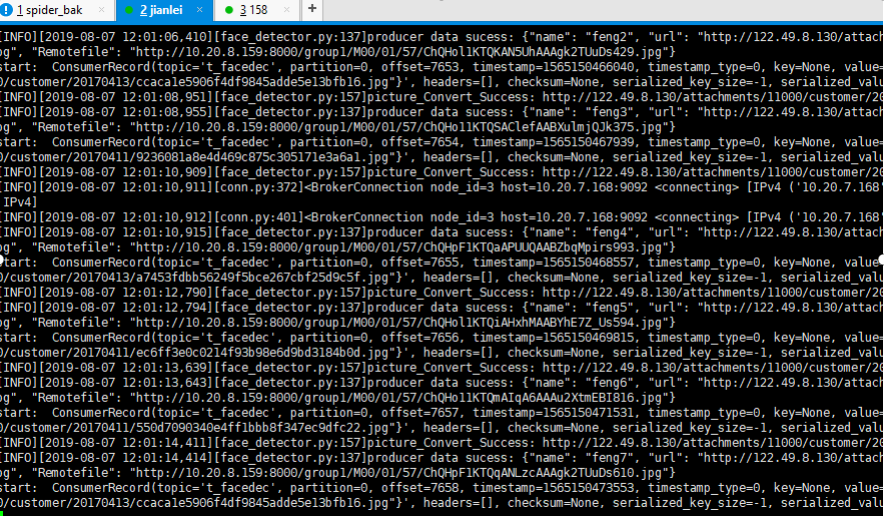
结论: 先启动的consumer会消费数据, 168的consumer关闭后, 158的consumer开始消费
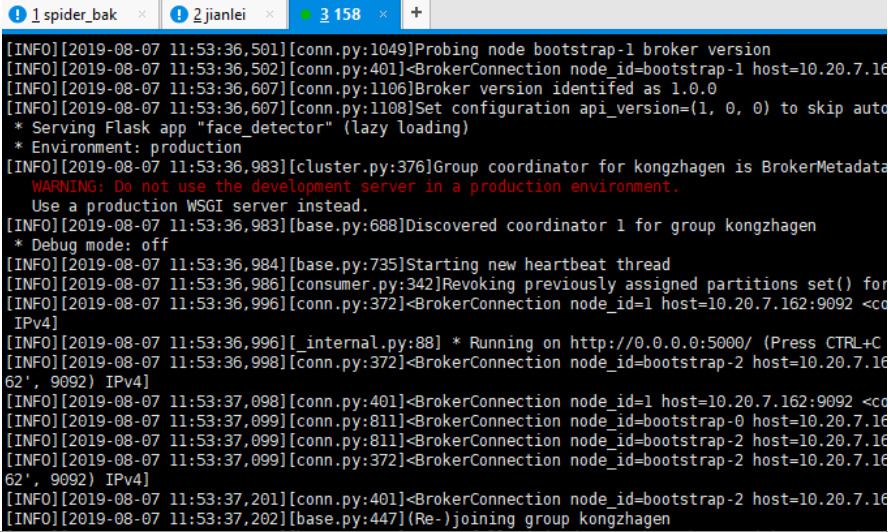
5、半小时后
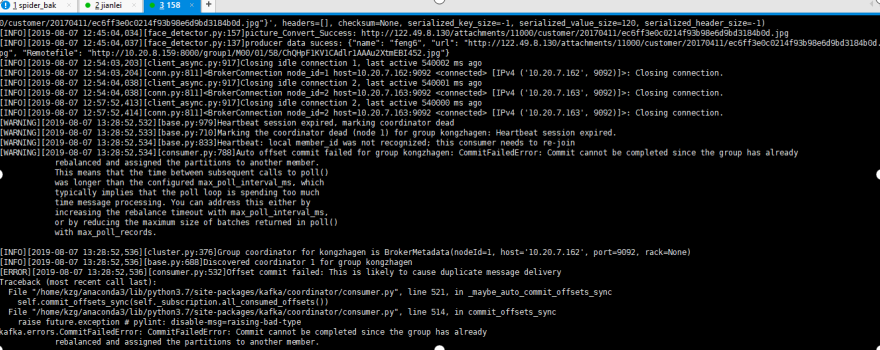
分解错误图:
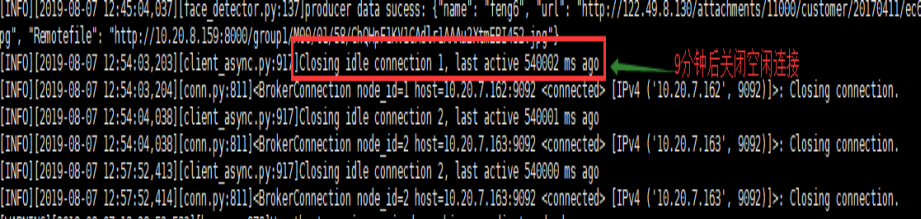
9分钟后空连接时间到'connections_max_idle_ms': 540000,
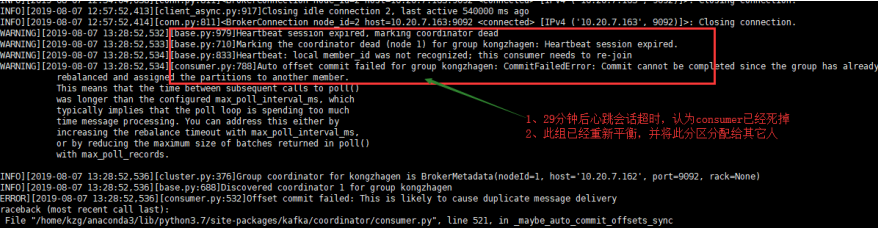
'max_poll_records': 500, 'heartbeat_interval_ms': 3000, 'session_timeout_ms': 30000,
后续:
14:32开始继续生产数据, 数据开始被消费

14:48分再次出现平衡超时

15:02分再次出现平衡超时

原因分析:
1、引起timeout的原因是consumer每3秒触发一次心跳, 由于某种原因在30秒内协调者没有收到此consumer的心跳信息, 认为此consumer已经死掉,topic内的分区在group的成员间重新分配(reblance)
2、默认consumer的每次最大poll数据量为500, 如果处理这500条记录的时候超过了最大时间间隔max_poll_interval_ms, consumer也会退出group, 导致reblance的产生
3、如果consumer没有产生消费行为的时间超过最大值connections_max_idle_ms:540000 (9 min)时, 也会导致consumer退出该组。
解决方法:
1、增加心跳会话超时间隔
session_timeout_ms = 300000(从30改为300秒)
2、减少每次获取任务的数量
max_poll_records = 5(从500改为5)
3、增加空闲连接时间
connections_max_idle_ms=5400000(从9min改为90min)


