



进程/线程模型
进程/线程模型

进程模型
(一)多道程序设计 (Multi programming)
允许多个程序同时进入内存并运行,其目的是为了提高系统效率。
并发环境与并发程序
并发环境:一段时间间隔内,单处理器上有两个或两个以上的程序同时处于开始运行但尚未结束的状态,并且次序不是事先确定的。
并发程序:在并发环境中执行的程序。

图1 图2 图3 图4
如图所示,图1图2,AB程序都有部分交错的地方,肯定是并发执行的。图3,图4虽然是一个结束了,另一个才执行。但是因为在系统中,不确定哪个在前哪个在后,所以也被认为是并发执行。
(二)进程的概念 “对CPU的抽象”
进程是具有独立功能的程序关于某个数据集合的一次运行活动,是系统进行资源分配和调度的独立单位,又称 任务(Task or job)
- 进程是程序的一次运行过程
- 是正在运行程序的抽象
- 将一个CPU变换成多个虚拟的CPU,彷佛每个进程都独立占用一个CPU在运行
- 系统资源以进程为单位分配,如内存、文件、.....每个都具有独立的地址空间
- 操作系统将CPU调度给需要的进程
(三)进程控制块 PCB
PCB:Process Control Block 又称进程描述符、进程属性。其是操作系统用于管理进程的一个专门数据结构(不是硬件!!!)。记录进程的各种属性,描述进程的动态变化过程。
PCB是系统感知进程存在的唯一标志,所以每个进程都有相对应的独立PCB,他们是一 一对应的。
进程表:所有进程的PCB集合。进程表往往是固定的,所有有时候我们也用其来衡量系统的并发度。
PCB模块包含的信息:
- 进程描述信息
- 进程控制信息
- 所拥有的资源和使用情况
- CPU现场信息
1.进程描述信息包含:进程标识符(process ID),唯一,通常是一个整数;进程名,通常是基于可执行文件名,不唯一;用户标识符(user ID);进程组关系(进程可能会有子进程,父进程)。
2.进程控制信息包含:当前状态;优先级(priority)代码执行入口地址程序的磁盘地址;运行统计信息(执行时间、页面调度)进程间同步和通信;进程的队列指针;进程的消息队列指针。
3.所使用的资源和使用情况包含:虚拟地址空间的状况;打开文件列表。
4.CPU现场信息包含:CPU现场信息;寄存器值(通用寄存器、程序计数器PC、程序状态字PSW、栈指针)指向该进程页表的指针。
(四)进程状态及转换
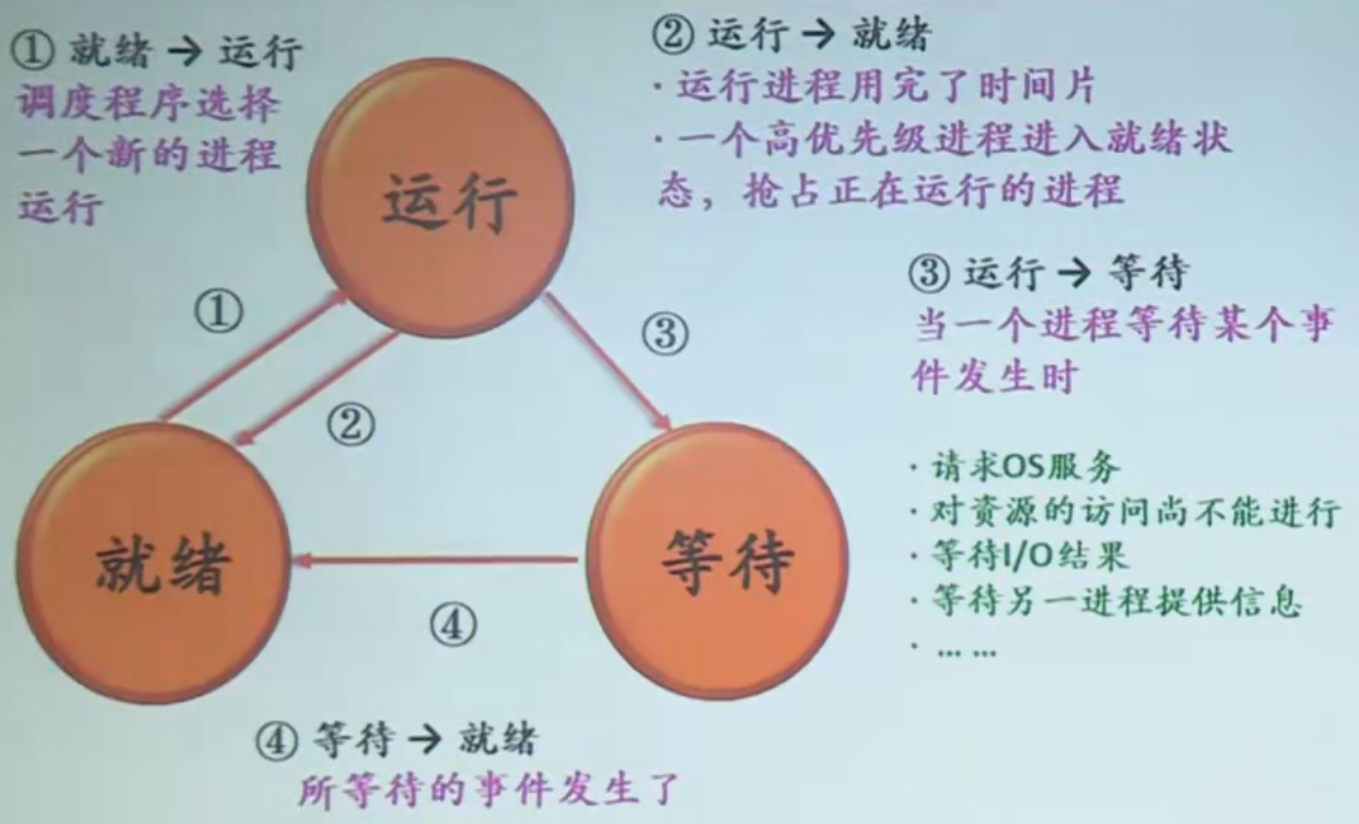
进程的三种基本状态:运行态(running): 占有CPU,并在CPU上运行。
就绪态(Ready):已经具备运行条件,但由于没有空闲CPU,而暂时不能运行。
等待态(Waiting/Blocked):也称为阻塞态、封锁态、睡眠态。因等待某一个事件导致不能运行。
三状态模型及状态转换:
进程的其他状态:
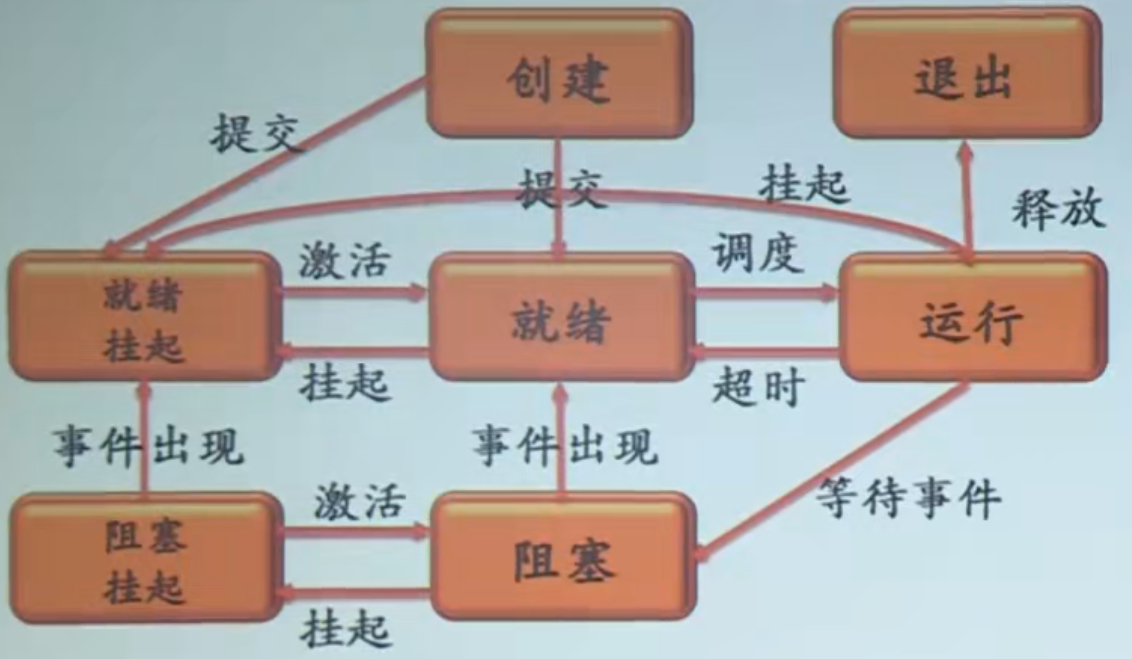
创建(new):已完成创建一进程所必要的工作,但尚未同意执行该进程(因为资源有限)。
终止(Terminated):终止执行后,进程进入该状态。可完成一些数据统计工作,资源回收。
挂起(suspend): 用于调节负载。进程不再占用内存空间,其进程映像交换到磁盘上。
五状态进程模型:

七状态进程模型:
进程队列
- 操作系统为每一类进程建立一个或多个队列
- 队列元素为PCB(进程控制块)
- 伴随进程状态的改变,其PCB从一个队列进入另一个队列

五状态进程模型的队列模型

进程受到许可后会进入就绪队列,受到调度就会被CPU执行。执行完成后被释放;如果时间片用完了(超时)就会再次进入就绪队列;也有可能进入等待事件队列,当等待的事件发生后,就会进入就绪队列。当然因为有不同的等待事件,所以会进入不同的等待队列。
(五)进程控制
进程控制操作完成进程各状态之间的转换,由具有特定功能的原语完成。例如有进程创建原语、进程撤消原语、阻塞原语、唤醒原语、挂起原语、激活原语、改变进程优先级。
原语(primitive):完成某种特定功能的一段程序,具有不可分割性或不可中断性。即原语的执行必须是连续的,在执行过程中不允许被中断。
1.进程的创建: Linux: fork/exex Windows: CreateProcess
- 给新进程分配一个唯一标识以及进程控制块(PCB)
- 为进程分配地址空间
- 初始化进程控制块
■ 设置默认值(如:状态为New,...)
- 设置相应的队列指针。如:把新进程加到就绪队列链表中
2.进程的撤销: Linux:exit Windows:TerminateProcess
结束进程:
- 收回进程所占有的资源:关闭打开的文件、断开网络连接、回收分配的内存.......
- 撤消该进程的PCB
3.进程阻塞: Linux:wait Windows:WaitForSingleObject
处于运行状态的进程,在其运行过程中期待某一事件发生,如等待键盘输入、等待磁盘数据传输完成、等待其它进程发送消息,当被等待的事件未发生时,由进程自己执行阻塞原语,使自己由运行态变为阻塞态。
UNIX的几个重要的进程控制操作

UNIX的FORK() 操作

以一次一页的方式复制父进程的地址空间???Really???效率呢???
答:既然父进程打算重新创建一个子进程了,那么父亲肯定希望子进程干和自己不同的工作,所以复制父进程的地址空间就很浪费了,是无用功了。
所以LINUX提出了一种新的优化方式:LINUX采用了写时复制技术COW(Copy-On-Write)加快了创建进程fork()的速度。具体操作是 -- 操作系统会复制父进程的整个地址空间,包括代码段,数据段,堆栈等,但是并不立即执行物理内存的复制,而是将地址空间和子进程共享。在共享的地址空间中,父进程和子进程共享相同的物理内存页面,这些页面被标记为“只读”(Read-only)。当操作系统在写操作时,执行实际的物理内存复制,这时操作系统会为子进程单独分配一块新的物理内存页面,使得父进程和子进程各自拥有各自修改后的副本。这样父进程和子进程就拥有各自的地址空间,它们之间不再共享物理内存的页面。
总结起来,fork()创建子进程时采用了写时复制技术,通过共享父进程的地址空间,避免了一开始就复制整个地址空间的开销,只有在需要修改页面时才进行实际的复制,从而提高了进程创建的效率。
使用FORK()的示例代码

在该代码中,首先创建一个子进程,并把返回值交给一个整数pid,判断pid值,如果是<0,说明创建失败;如果是=0说明接下来执行的是子进程的代码(因为上面谈到了,当fork()以后,系统会对子进程返回标识符0,会对父进程返回非零值pid);如果是既不<0也不=0,那么就会执行父进程的代码。
接下来我们看一下具体的运行过程。
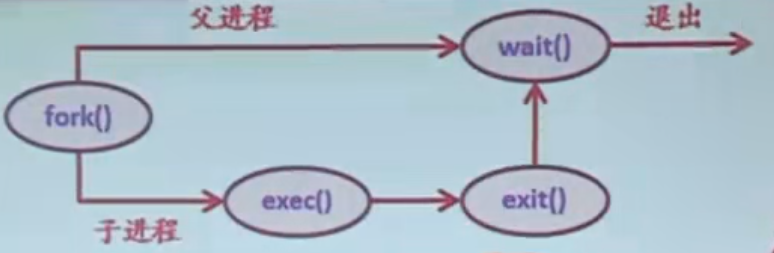
说明:fork()创建完以后,其实就有父进程,子进程两条分支了,子进程使用exec()来覆盖父进程的地址空间,执行完以后呢就会exit()。父进程会进入wait()等待状态,等待子进程结束以后,再退出。
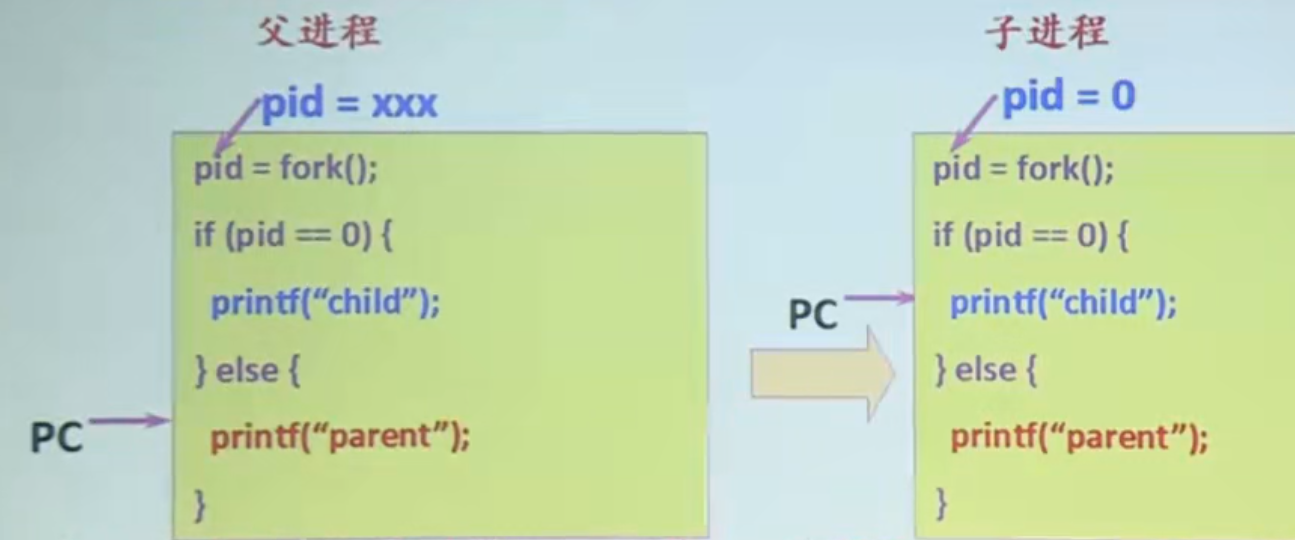
可以看到,fork()完以后,父进程和子进程其实已经是两个不同的地址空间了,然后分别去进行pid值的判断,再去执行相应的代码。

