day8.列表、字典、集合相关操作
一、列表的相关操作
# (1)列表的拼接 (同元组) # (2)列表的重复 (同元组) # (3)列表的切片 (同元组) # 语法 => 列表[::] 完整格式:[开始索引:结束索引:间隔值] # (1)[开始索引:] 从开始索引截取到列表的最后 # (2)[:结束索引] 从开头截取到结束索引之前(结束索引-1) # (3)[开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1) # (4)[开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定的间隔截取列表元素值 # (5)[:]或[::] 截取所有列表 # (4)列表的获取 (同元组) # (5)列表的修改 ( 可切片 ) # (6)列表的删除 ( 可切片 )
1、列表的拼接 (同元组)
lst1 = [1,2,3] lst2 = [4,5,6,6] res = lst1 + lst2 print(res)
2、列表的重复 (同元组)
res = lst1 * 3
print(res)
3、列表的切片 (同元组)
# 语法 => 列表[::] 完整格式:[开始索引:结束索引:间隔值] # (1)[开始索引:] 从开始索引截取到列表的最后 # (2)[:结束索引] 从开头截取到结束索引之前(结束索引-1) # (3)[开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1) # (4)[开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定的间隔截取列表元素值 # (5)[:]或[::] 截取所有列表


lst = ["aaa","bbb","ccc","ddd","eee","fff","ggg","hhh"] # (1)[开始索引:] 从开始索引截取到列表的最后 res = lst[2:] print(res) # (2)[:结束索引] 从开头截取到结束索引之前(结束索引-1) res = lst[:4] print(res) # (3)[开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1) res = lst[4:6] print(res) # (4)[开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定的间隔截取列表元素值 # 正向截取 res = lst[::2] # 0 2 4 6 8 ... print(res) # 逆向截取 res = lst[::-2] # -1 -3 -5 -7 -9 print(res) # (5)[:]或[::] 截取所有列表 res = lst[:] res = lst[::] print(res) 列表切片
4、列表的获取 (同元组)
# 0 1 2 3 4 5 6 7 lst = ["aaa","bbb","ccc","ddd","eee","fff","ggg","hhh"] # -8 -7 -6 -5 -4 -3 -2 -1 res = lst[7] res = lst[-1] print(res)
5、列表的修改 (可切片)
lst = ["aaa","bbb","ccc","ddd","eee","fff","ggg","hhh"] # 利用切片可以一次修改多个元素,没有个数上的限制 # lst[1:3] = "abcd" lst[3:5] = ["update_ddd","update_eee","update_fff"] print(lst) # 切片配合步长,切出多少个元素,修改多少个元素 lst = ["aaa","bbb","ccc","ddd","eee","fff","ggg","hhh"] # res = lst[::2]#aaa ccc eee ggg # lst[::2] = "abcd" lst[::2] = range(1,5) # 0 2 4 6 8 10 ..... print(lst,"<==>")
6、列表的删除 (可切片)
lst = ["aaa","bbb","ccc","ddd","eee","fff","ggg","hhh"] # del lst[-1] # print(lst) # 删除的是变量res本身,不是列表中的元素 """ res = lst[-1] del res print(lst) """ # del lst[:2] del lst[::3] # 0 3 6 9 12 ... print(lst)
元组中的列表,里面的元素可以修改;
tup = (1,2,3,[4,5,6,(7,8,9)]) tup[-1][1] = 6666 print(tup)
二、列表的相关函数
1、向列表新增元素
lst = ["aa"] # 增 # append 向列表的末尾添加新的元素 lst.append("bb") print(lst) # insert 在指定索引之前插入元素 lst.insert(0,"cc") lst.insert(2,"dd") print(lst) # extend 迭代追加所有元素 """要求:数据的类型是可迭代性数据""" strvar = "1234" lst.extend(strvar) print(lst)
2、删除列表元素
# pop 通过指定索引删除元素,若没有索引移除最后那个 lst = ["aa","bb","cc","dd","ee"] # 指定索引进行删除 # res = lst.pop(1) # 默认没有任何参数,删除的是最后一个 res = lst.pop() print(res) print(lst) # remove 通过给予的值来删除,如果多个相同元素,默认删除第一个 lst = ["aa","bb","cc","dd","ee","ff","ff"] # 指定值进行删除,如果有多个相同的重复值,默认删掉第一个 lst.remove("ee") print(lst) # clear 清空列表 lst = ["aa","bb","cc","dd","ee","ff","ff"] lst.clear() print(lst)
3、其他函数
3.1、index
lst = ["aa","bb","cc","dd","ee","ff","gg"] # index 获取某个值在列表中的索引 '''列表.index(值[,start][,end]) # [] 表达参数可选项 找不到报错''' res = lst.index("kk") res = lst.index("kk",3) # res = lst.index("kk",3,5) error print(res)
3.2、count
# count 计算某个元素出现的次数 res = lst.count("ff") print(res) """ # 区别:字符串里面的count 可以划定范围,列表里面的count不行 strvar = "abcadaaaa" print(strvar.count("a",1)) """
3.3、sort
# sort() 列表排序(默认小到大排序) # 默认从小到大 lst = [44,99,1,10,3,-5,-90] lst.sort() # 从大到小排序 lst.sort(reverse=True) print(lst)
排序英为
"""一位一位进行比较,在第一位相同的情况下,比较第二位,以此类推""" lst = ["oneal","kobe","james","jordan","macdi"] lst.sort() print( lst )
排序中文
# 是否可以对中文进行排序.可以排序!(无规律可循) lst = ["aa","bb","cc","dd"] lst.sort() print(lst)
3.4、reverse
lst = ["aa","bb","cc","dd"] lst.reverse() print(lst)
三、浅拷贝和深拷贝
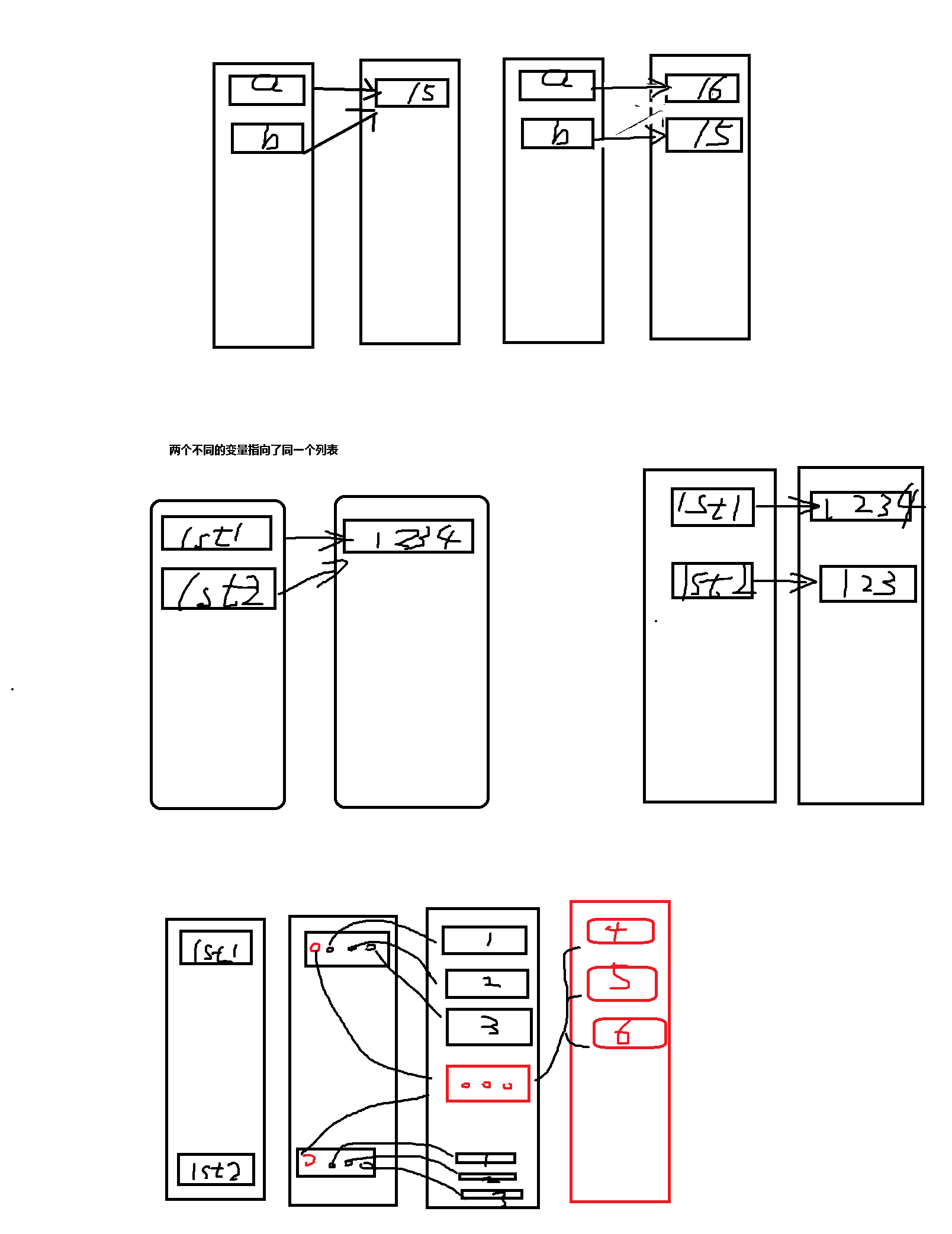
""" a = 15 b = a a = 16 print(b) 值为:15 """
1、浅拷贝
import copy lst1 = [1,2,3] # 方法一 copy.copy 模块.方法 lst2 = copy.copy(lst1) lst1.append(4) print(lst1) print(lst2) # 方法二 列表.copy() lst1 = [1,2,3,4] lst3 = lst1.copy() lst1.insert(0,0) print(lst1) print(lst3)
向lst1追加数据不会改变lst2中的值
2、深拷贝
""" lst1 = [1,2,3,[4,5,6]] lst2 = copy.copy(lst1) lst1[-1].append(7) lst1.append(100) print(lst1) print(lst2) """
lst1 = [1,2,3,[4,5,6]] lst2 = copy.deepcopy(lst1) # lst1[-1].extend("ab") print(lst2) print(lst1) print(id(lst2[-1])) print(id(lst1[-1])) print(id(lst1[0])) print(id(lst2[0])) lst2[0] = 1111 print(id(lst1[0])) print(id(lst2[0]))
""" # 总结: (1)浅拷贝只拷贝一级容器中的所有数据 (2)深拷贝拷贝所有层级的所有元素 浅拷贝速度比深拷贝速度快 深拷贝在执行时: 如果是不可变数据,地址会暂时的指向原来数据, 如果是可变数据,直接开辟新空间 不可变数据: Number str tuple 可变数据 : list set dict """
四、字典相关函数
1、向字典添加数据
# 增 dic = {} dic["ww"] = "aaaaaaaaaaa" dic['ywz'] = "bbbbbb" dic["hxl"] = "ccccccc" print(dic) #fromkeys() 使用一组键和默认值创建字典 lst = ["ww","ywz","hxl"] dic = {}.fromkeys(lst,None) print(dic)
注意:
""" dic = {}.fromkeys(lst,[]) print(dic) dic["ww"].append(1) print(dic) dic["ww"] = [] dic['ywz'] =[] dic["hxl"] =[] # {'ww': [], 'sdf': [], 'hxl': []} # {'ww': [1], 'sdf': [1], 'hxl': [1]} """
# 注意点: 三个键所指向的列表是同一个(不推荐)
2、字典的删除
#pop() 通过键去删除键值对 (若没有该键可设置默认值,预防报错) dic = {"top":"花木兰" , "middle":"甄姬" , "bottom":"孙尚香" , "jungle" : "钟馗" , "support":"蔡文姬" } res = dic.pop("top") # 如果删除的是不存在的键,直接报错 # res = dic.pop("top123") # 可以设置默认值,防止报错 # res = dic.pop("top123","没有这个键") res = dic.pop("middle","没有这个键") print(res , dic,"<=======>") #popitem() 删除最后一个键值对 res = dic.popitem() print(res, dic) #clear() 清空字典 dic.clear() print(dic)
3、字典的修改
#update() 批量更新(有该键就更新,没该键就添加) dic = {'ww': 'aaaaaaaa', 'ywz': 'bbbbbbb', 'hxl': 'ccccccccc'} dic_new = {"ywz":"ddddd","hxl":"eeeeeee","ly":"fffffffff"} # 方法一(推荐) dic.update(dic_new) print(dic) # 方法二 dic.update(kxq="kkkkkkkk",ccg="ooooooooo") print(dic)
4、字典的查
dic = {'ww': 'aaaaaaaa', 'ywz': 'bbbbbbb', 'hxl': 'ccccccc'}
#keys() 将字典的键组成新的可迭代对象
res = dic.keys()
print(res)
#values() 将字典中的值组成新的可迭代对象
res = dic.values()
print(res)
#items() 将字典的键值对凑成一个个元组,组成新的可迭代对象
res = dic.items()
print(res)
五、集合的相关操作
set1 = {"jacklove","theshy","rookie","xboyww"}
set2 = {"aaa","张国荣","bbb","ccc","ddd","eee"}
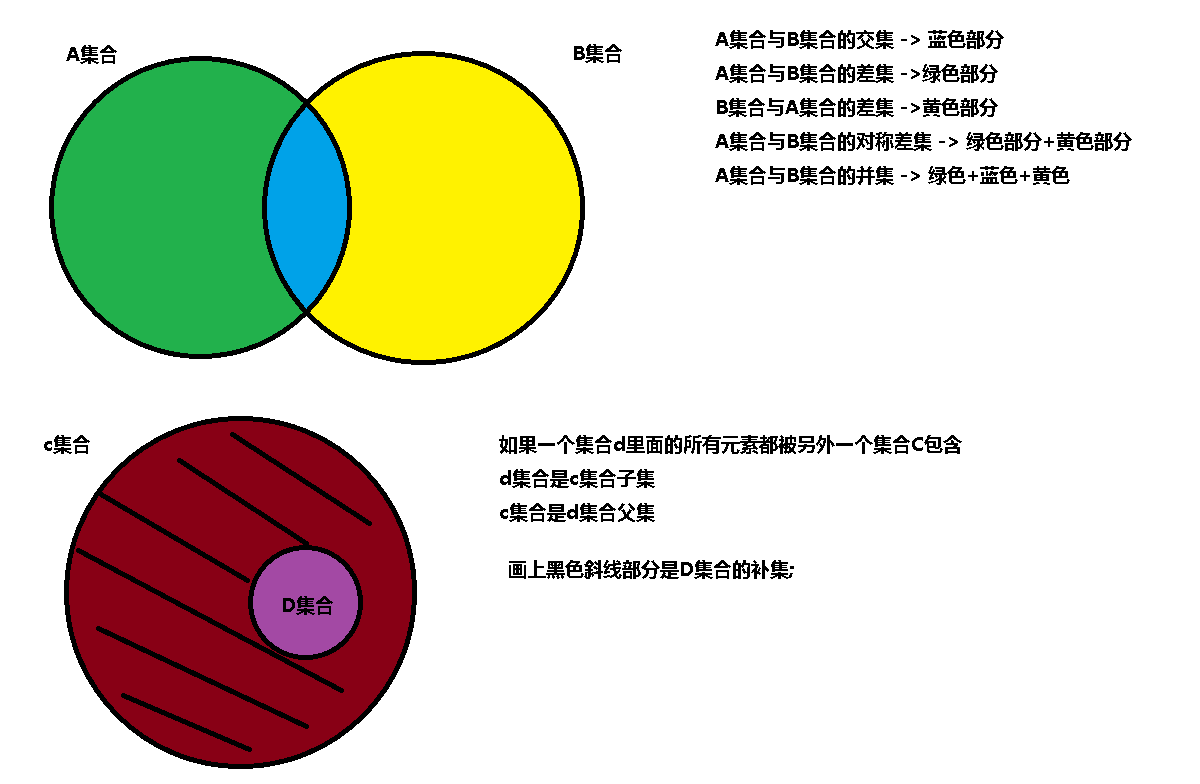
1、 交集 intersection()
#intersection() 交集 res = set1.intersection(set2) print(res) # 简写 & res = set1 & set2 print(res)
2、差集 difference()
#difference() 差集 res = set1.difference(set2) print(res) # 简写 - res = set1 - set2 print(res)
3、并集 union()
res = set1.union(set2) print(res) # 简写 | res = set1 | set2 print(res)
4、对称差集 symmetric_difference()
res = set1.symmetric_difference(set2) print(res) # 简写 ^ res = set1 ^ set2 print(res)
5、判断是否是子集 issubset()
set1 = {"周杰伦","王力宏","罗**","潘玮柏"}
set2 = {"周杰伦","王力宏"}
# set2的子集 是不是set1 res = set1.issubset(set2) print(res) # 简写 < res = set1 < set2 print(res)
6、判断是否是父集 issuperset()
res = set1.issuperset(set2) print(res) # 简写 > res = set1 > set2 print(res)
7、检测两集合是否不相交 isdisjoint() 不相交 True 相交False
res = set1.isdisjoint(set2) print(res)
六、集合的相关函数
1、集合的新增
#add() 向集合中添加数据 (一次加一个) setvar.add("aaa") print(setvar) #update() 迭代着增加 (一次加一堆) strvar = ("bbb","ccc") setvar.update(strvar) print(setvar)
2、集合的删除
#clear() 清空集合 # setvar.clear() # print(setvar) #pop() 随机删除集合中的一个数据 res = setvar.pop() print(res , setvar) #remove() 删除集合中指定的值(不存在则报错)(了解) # setvar.remove("神秘男孩") # print(setvar) #discard() 删除集合中指定的值(不存在的不删除 推荐使用) setvar.discard("神秘男孩") setvar.discard("神秘男孩1234324") print(setvar)
七、冰冻集合
#frozenset 可强转容器类型数据变为冰冻集合 """冰冻集合一旦创建,不能在进行任何修改,只能做交叉并补操作"""
lst1 = ["qqq",18,"男性","爱好:跑步"] fz1 = frozenset(lst1) lst2 = ("kxq","地址:beijing","买一辆特斯拉") fz2 = frozenset(lst2) print(fz1 , type(fz1)) print(fz2 , type(fz2)) # 不能够在冰冻集合当中添加或者删除元素 # fz1.add(123) error # 只能交差并补 print( fz1 & fz2 ) print( fz1 - fz2 )
八、练习
''' 1.li = ["alex", "WuSir", "xboy", "oldboy"] 1)列表中追加元素"seven",并输出添加后的列表 2)请在列表的第1个位置插入元素"Tony",并输出添加后的列表 3)请修改列表第2个位置的元素为"Kelly",并输出修改后的列表 4)请将列表l2=[1,"a",3,4,"heart"]的每一个元素添加到列表li中,一行 代码实现,不允许循环添加。 5)请将字符串s = "qwert"的每一个元素添加到列表li中,一行代码实现,不允许循环添加。 6)请删除列表中的元素"alex",并输出添加后的列表 7)请删除列表请删除列表中的第2至4个元素,并输出删除元素后的列表 8)删除列表中的第2个元素,并输出删除的元素和删除元素后的列表 9)请将列表所有得元素反转,并输出反转后的列表 10)请计算出"alex"元素在列表li中出现的次数,并输出该次数。 2,写代码,有如下列表,利用切片实现每一个功能 li = [1, 3, 2, "a", 4, "b", 5,"c"] 1)通过对li列表的切片形成新的列表l1,l1 = [1,3,2] 2)通过对li列表的切片形成新的列表l2,l2 = ["a",4,"b"] 3)通过对li列表的切片形成新的列表l3,l3 = ["1,2,4,5] 4)通过对li列表的切片形成新的列表l4,l4 = [3,"a","b"] 5)通过对li列表的切片形成新的列表l5,l5 = ["c"] 6)通过对li列表的切片形成新的列表l6,l6 = ["b","a",3] 3,写代码,有如下列表,按照要求实现每一个功能。 lis = [2, 3, "k", ["qwe", 20, ["k1", ["tt", 3, "1"]], 89], "ab", "adv"] 1)将列表lis中的"tt"变成大写。 2)将列表中的数字3变成字符串"100"。 3)将列表中的字符串"1"变成数字101 4,li = ["alex", "eric", "rain"] 利用下划线将列表的每一个元素拼接成字符串"alex_eric_rain" 5.利用for循环打印出下面列表的索引。 li = ["alex", "WuSir", "xboy", "oldboy"] 6.利用for循环和range 找出50以内能被3整除的数,并将这些数插入到一个新列表中。 7.利用for循环和range从100~10,倒序将所有的偶数添加到一个新列表中,然后对列表的元素进行筛选,将能被4整除的数留下来 8.查找列表li中的元素,移除每个元素的空格,并找出以"A"或者"a"开头,并以"c"结尾的所有元素,并添加到一个新列表中,最后循环打印这个新列表。 li = ["xboy ", "alexC", "AbC ", "egon", " riTiAn", "WuSir", " aqc"] 9.敏感词列表 li = ["苍老师", "东京热", "武藤兰", "波多野结衣"] 将用户输入的内容中的敏感词汇替换成等长度的*(苍老师就替换***),并添加到一个列表中;如果用户输入的内容没有敏感词汇,则直接添加到新列表中。 10.li = [1, 3, 4, "alex", [3, 7, “23aa”,8, "xboy"], 5,(‘a’,’b’)] 循环打印列表中的每个元素,并转化为小写,遇到列表则再循环打印出它里面的元素。 11.tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)}, 44]) a.讲述元组的特性 b.请问tu变量中的第一个元素 "alex" 是否可被修改? c.请问tu变量中的"k2"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven" d.请问tu变量中的"k3"对应的值是什么类型?是否可以被修改?如果可以,请在其中添加一个元素 "Seven" 12.把字符串 "k:1|k1:2|k2:3|k3:4" 处理成字典 {'k':1,'k1':2....} 13.有如下值li= [11,22,33,44,55,66,77,88,99,90], 将大于 66 的值保存至字典的k1键中, 将小于 66 的值保存至字典的k2键中。 即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表} '''
# 1.li = ["alex", "WuSir", "xboy", "oldboy"] # 1)列表中追加元素"seven",并输出添加后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] li.append('seven') print(li)
# 2)请在列表的第1个位置插入元素"Tony",并输出添加后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] li.insert(0,'Tony') print(li)
# 3)请修改列表第2个位置的元素为"Kelly",并输出修改后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] li[1] = "Kelly" print(li)
# 4)请将列表l2=[1,"a",3,4,"heart"]的每一个元素添加到列表li中,一行 li = ["alex", "WuSir", "xboy", "oldboy"] l2=[1,"a",3,4,"heart"] li.extend(l2) print(li)
# 代码实现,不允许循环添加。 # 5)请将字符串s = "qwert"的每一个元素添加到列表li中,一行代码实现,不允许循环添加。 li = ["alex", "WuSir", "xboy", "oldboy"] s = "qwert" li.extend(s) print(li)
# 6)请删除列表中的元素"alex",并输出添加后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] res = li.pop(0) print(li)
# 7)请删除列表请删除列表中的第2至4个元素,并输出删除元素后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] del li[1:] print(li)
# 8)删除列表中的第2个元素,并输出删除的元素和删除元素后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] res = li.pop(1) print(res,li)
# 9)请将列表所有得元素反转,并输出反转后的列表 li = ["alex", "WuSir", "xboy", "oldboy"] li.reverse() print(li)
# 10)请计算出"alex"元素在列表li中出现的次数,并输出该次数。 li = ["alex", "WuSir", "xboy", "oldboy"] print(li.count('alex'))
# 2,写代码,有如下列表,利用切片实现每一个功能 # li = [1, 3, 2, "a", 4, "b", 5,"c"] # 1)通过对li列表的切片形成新的列表l1,l1 = [1,3,2] li = [1, 3, 2, "a", 4, "b", 5,"c"] l1 = li[:3] print(l1)
# 2)通过对li列表的切片形成新的列表l2,l2 = ["a",4,"b"] li = [1, 3, 2, "a", 4, "b", 5,"c"] l2 = li[3:6] print(l2)
# 3)通过对li列表的切片形成新的列表l3,l3 = ["1,2,4,5] li = [1, 3, 2, "a", 4, "b", 5,"c"] l3 = li[::2] print(l3)
# 4)通过对li列表的切片形成新的列表l4,l4 = [3,"a","b"] li = [1, 3, 2, "a", 4, "b", 5,"c"] l4 = li[1:-1:2] print(l4)
# 5)通过对li列表的切片形成新的列表l5,l5 = ["c"] li = [1, 3, 2, "a", 4, "b", 5,"c"] l5 = li[-1:] print(l5)
# 6)通过对li列表的切片形成新的列表l6,l6 = ["b","a",3] li = [1, 3, 2, "a", 4, "b", 5,"c"] l6 = li[-3:0:-2] print(l6)
# 3,写代码,有如下列表,按照要求实现每一个功能。 # lis = [2, 3, "k", ["qwe", 20, ["k1", ["tt", 3, "1"]], 89], "ab", "adv"] # 1)将列表lis中的"tt"变成大写。 lis = [2, 3, "k", ["qwe", 20, ["k1", ["tt", 3, "1"]], 89], "ab", "adv"] print(lis[3][2][1][0].upper())
# 2)将列表中的数字3变成字符串"100"。 lis[1] = '100' lis[3][2][1][1] = '100' print(lis)
# 3)将列表中的字符串"1"变成数字101 lis[3][2][1][2]=101 print(lis)
# 4,li = ["alex", "eric", "rain"] # 利用下划线将列表的每一个元素拼接成字符串"alex_eric_rain" li = ["alex", "eric", "rain"] res = "_".join(li) print(res)
# 5.利用for循环打印出下面列表的索引。 # li = ["alex", "WuSir", "xboy", "oldboy"] li = ["alex", "WuSir", "xboy", "oldboy"] for i in range(len(li)): print(i)
# 6.利用for循环和range 找出50以内能被3整除的数,并将这些数插入到一个新列表中。 # listvar1 = [] for i in range(51): if i % 3 == 0: listvar1.append(i) print(listvar1)
# 7.利用for循环和range从100~10,倒序将所有的偶数添加到一个新列表中,然后对列表的元素进行筛选,将能被4整除的数留下来 print('7. ********************') lisvavr1 = [] for i in range(100,9,-1): if i % 2 == 0: listvar1.append(i) print(listvar1) for i in listvar1: if i % 4 != 0: listvar1.remove(i) print(listvar1)
# 8.查找列表li中的元素,移除每个元素的空格,并找出以"A"或者"a"开头,并以"c"结尾的所有元素,并添加到一个新列表中,最后循环打印这个新列表。 # li = ["xboy ", "alexC", "AbC ", "egon", " riTiAn", "WuSir", " aqc"] # li = ["xboy ", "alexC", "AbC ", "egon", " riTiAn", "WuSir", " aqc"] l2 = [] for i in li: res = i.strip() if (res.startswith('A') or res.startswith('a')) and res.endswith('c'): # print(res[0]) # if res[0] == 'A' or res[0] == 'a' and res[0] == 'c': l2.append(res) print(l2)
# 9.敏感词列表 li = ["苍老师", "东京热", "武藤兰", "波多野结衣"] # 将用户输入的内容中的敏感词汇替换成等长度的*(苍老师就替换***),并添加到一个列表中;如果用户输入的内容没有敏感词汇,则直接添加到新列表中。 # while True: count = 0 res = input('输入内容') for i in range(len(li)): count += 1 print(count) if li[i] in res: ret1 = res.replace(li[i], '*'*len(li[i])) mingan.append(ret1) break elif count == len(li): new.append(res) break print(mingan) print(new)
# 10.li = [1, 3, 4, "alex", [3, 7, “23aa”,8, "xboy"], 5,(‘a’,’b’)] # 循环打印列表中的每个元素,并转化为小写,遇到列表则再循环打印出它里面的元素。 # li = [1,3,4,'alex',[3,7,'23aa',8,"xboy"],5,('a','b')] list1 = [] for i in li: if isinstance(i,int): list1.append(i) elif isinstance(i,str): list1.append(i.lower()) elif isinstance(i,list) or isinstance(i,tuple): for j in i: if isinstance(j, int): list1.append(j) elif isinstance(j,str): list1.append(j.lower()) print(list1)
tu = ("alex", [11, 22, {"k1": 'v1', "k2": ["age", "name"], "k3": (11,22,33)}, 44]) tu[-1][2]["k2"].append("seven") print(tu) # a.可获取,不可修改,有序 # b.不可以 # c.列表 可以 tu[-1][2]["k2"].append("seven") # d.元组 不可以
strvar = "k:1|k1:2|k2:3|k3:4" dic = {} lst = strvar.split("|") print(lst) # ['k:1', 'k1:2', 'k2:3', 'k3:4'] for i in lst: k,v = i.split(":") dic[k] = v print(dic) # {'k': '1', 'k1': '2', 'k2': '3', 'k3': '4'}
# 13.有如下值li= [11,22,33,44,55,66,77,88,99,90], # 将大于 66 的值保存至字典的k1键中, # 将小于 66 的值保存至字典的k2键中。 # 即: {'k1': 大于66的所有值列表, 'k2': 小于66的所有值列表} li= [11,22,33,44,55,66,77,88,99,90] dic = {"k1":[],"k2":[]} for i in li: if i > 66: dic["k1"].append(i) elif i < 66: dic["k2"].append(i) print(dic)
