
python3制作捧腹网段子页爬虫
0x01
春节闲着没事(是有多闲),就写了个简单的程序,来爬点笑话看,顺带记录下写程序的过程。第一次接触爬虫是看了这么一个帖子,一个逗逼,爬取煎蛋网上妹子的照片,简直不要太方便。于是乎就自己照猫画虎,抓了点图片。
科技启迪未来,身为一个程序员,怎么能干这种事呢,还是爬点笑话比较有益于身心健康。

0x02
在我们撸起袖子开始搞之前,先来普及点理论知识。
简单地说,我们要把网页上特定位置的内容,扒拉下来,具体怎么扒拉,我们得先分析这个网页,看那块内容是我们需要的。比如,这次爬取的是捧腹网上的笑话,打开 捧腹网段子页我们可以看到一大堆笑话,我们的目的就是获取这些内容。看完回来冷静一下,你这样一直笑,我们没办法写代码。在 chrome 中,我们打开 审查元素 然后一级一级的展开 HTML 标签,或者点击那个小鼠标,定位我们所需要的元素。
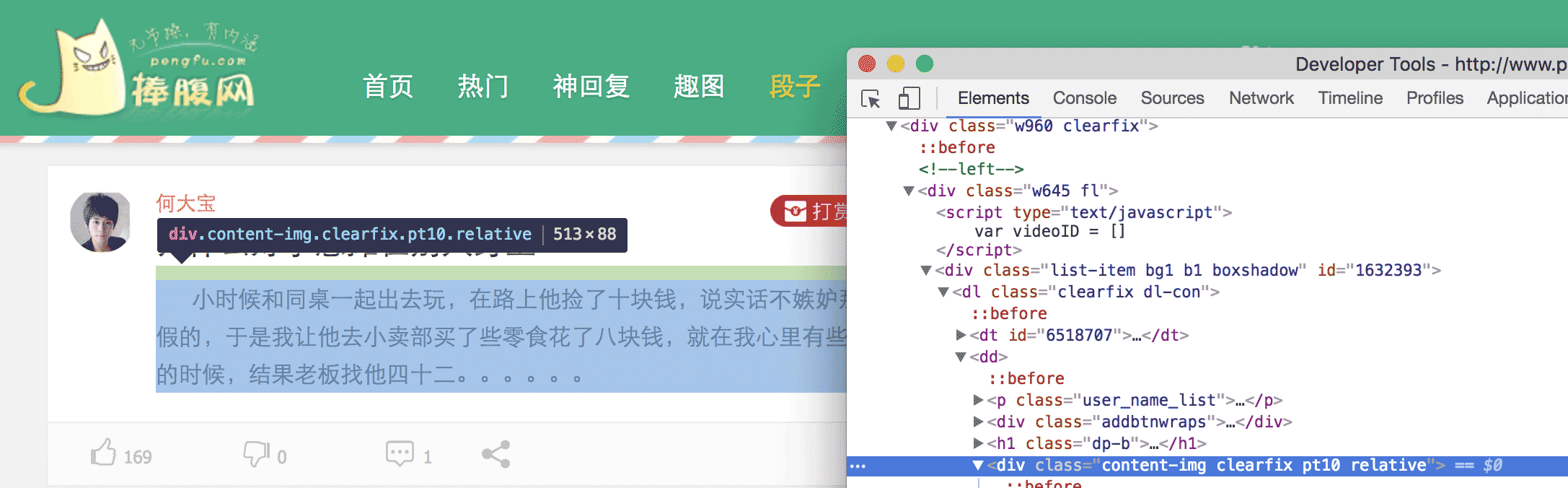
最后可以发现 <div> 中的内容就是我们所需要的笑话,在看第二条笑话,也是这样。于是乎,我们就可以把这个网页中所有的 <div> 找到,然后把里边的内容提取出来,就完成了。
0x03
好了,现在我们知道我们的目的了,就可以撸起袖子开始干了。这里我用的 python3,关于 python2 和 python3 的选用,大家可以自行决定,功能都可以实现,只是有些许不同。但还是建议用 python3。
我们要扒拉下我们需要的内容,首先我们得把这个网页扒拉下来,怎么扒拉呢,这里我们要用到一个库,叫 urllib,我们用这个库提供的方法,来获取整个网页。
首先,我们导入 urllib
然后,我们就可以使用 request 来获取网页了,
return request.urlopen(url).read()
人生苦短,我用 python,一行代码,下载网页,你说,还有什么理由不用 python。
下载完网页后,我们就得解析这个网页了来获取我们所需要的元素。为了解析元素,我们需要使用另外一个工具,叫做 Beautiful Soup,使用它,可以快速解析 HTML 和 XML并获取我们所需要的元素。
用 BeautifulSoup 来解析网页也就一句话,但当你运行代码的时候,会出现这么一个警告,提示要指定一个解析器,不然,可能会在其他平台或者系统上报错。
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))
解析器的种类 和 不同解析器之间的区别 官方文档有详细的说明,目前来说,还是用 lxml 解析比较靠谱。
修改之后
这样,就没有上述警告了。
利用 find_all 函数,来找到所有 class = content-img clearfix pt10 relative 的 div 标签 然后遍历这个数组
这样,我们就取到了目的 div 的内容。至此,我们已经达到了我们的目的,爬到了我们的笑话。
但当以同样的方式去爬取糗百的时候,会报这样一个错误
说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-import sysimport urllib.request as requestfrom bs4 import BeautifulSoupdef getHTML(url): headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} req = request.Request(url, headers=headers) return request.urlopen(req).read()def get_pengfu_results(url): soup = BeautifulSoup(getHTML(url), 'lxml') return soup.find_all('div', {'class':"content-img clearfix pt10 relative"})def get_pengfu_joke(): for x in range(1, 2): for x in get_pengfu_results(url): content = x.string try: string = content.lstrip() print(string + '\n\n') except: continue returndef get_qiubai_results(url): soup = BeautifulSoup(getHTML(url), 'lxml') contents = soup.find_all('div', {'class':'content'}) restlus = [] for x in contents: str = x.find('span').getText('\n','<br/>') restlus.append(str) return restlusdef get_qiubai_joke(): for x in range(1, 2): for x in get_qiubai_results(url): print(x + '\n\n') returnif __name__ == '__main__': get_pengfu_joke() get_qiubai_joke()
 浙公网安备 33010602011771号
浙公网安备 33010602011771号