软件工程第1次作业—词频统计
作业要求的博客链接:https://edu.cnblogs.com/campus/nenu/2016CS/homework/2110
git仓库地址:https://git.coding.net/isak_even/wf.git
项目概要:
本次项目实现的是词频统计,目前第一版本已实现的功能如下:
1)处理同目录的txt文件(2018/9/20修改: 可以按照输入顺序输出词频)。
2)处理指定路径下按字典序排列的第一个txt文件。
3)处理指定路径指定文件名的txt文件。
处理文件时如果输入指定数字N,可输出按词频序排列的前N个词,否则输出所有合法词及词频。
项目详情:
一、本次作业采用c/c++进行编程。首先分析项目要求概括功能:
1)对指定的文件进行词频统计,注意此文件应和wf.exe在同一目录下。(输入 wf -c xxx.txt)
2)输入指定路径,对其目录下文件名称按照字典序最靠前的文本文件进行词频统计。(输入 wf -f X:\xxx\xxx )
3)对指定文件名或者指定路径下的字典序最靠前的文件进行词频统计,输出频率最高的N个词。(输入 wf -f X:\xxx\xxx -n X 或者 wf -c xxx.txt -n X ,“-n X”的位置可前可后)
4)对指定路径下的指定文件进行词频统计,也具有输出频率最高的N个词的功能。(输入 wf -f X:\xxx\xxx -c xxx.txt [-n X])
二、根据分析规划函数模块:
1)处理输入(分别处理路径名、文件名、数字N)。
2)搜索指定路径下的所有txt文件,并且选定字典序最靠前的文件。
3)处理指定文本文件的内容,保存为字符串。
4)切割字符串并且统计词频。
5)主函数,负责调用各个模块,控制流程。
三、模块代码实现过程:
1)处理输入(分别处理路径名、文件名、数字N)。
输入时用检测是否出现特定字符来处理不同的内容。比如出现“-f”时后面就是路径名,出现“-c”时后面就是文件名。
这里的主要问题是如何在字符串里找指定的子串,我使用的是find(),此函数如果找到子串会返回第一个字符的索引,如果没有找到,则返回npos。
文件名和数字N的处理方法一样,只是在处理数字时要把字符转化为数字,可以用 sscanf( number.c_str(),"%d",&number1 );
具体代码如下:
/*---处理输入的路径---*/ bool getfilepath() { bool exist=false; string::size_type index2 = inputstr.find("-f"); if(index2!=string::npos) { exist=true; index2=index2+3; while(inputstr[index2]!=' '&&inputstr[index2]!='\n') { path_name=path_name+inputstr[index2]; index2++; } } return exist; }
2)搜索指定路径下的所有txt文件,并且选定字典序最靠前的文件。
这里的主要思路是获取该路径下所有符合要求的文件(用format 控制文件类型,在这里传入的是".txt"),将所有合适的文件名放在files中。
然后在主函数中用sort给files排序,files[0]就是我们需要的文件。
这段代码借鉴自https://www.cnblogs.com/tgyf/p/3839894.html
/*-------获取特定格式的文件名-------*/ void GetAllFormatFiles( string path, vector<string>& files,string format) { long hFile = 0;//文件句柄 struct _finddata_t fileinfo; //文件信息 string p; if((hFile = _findfirst(p.assign(path).append("\\*" + format).c_str(),&fileinfo)) != -1) { do { if((fileinfo.attrib & _A_SUBDIR)) { if(strcmp(fileinfo.name,".") != 0 && strcmp(fileinfo.name,"..") != 0) { GetAllFormatFiles( p.assign(path).append("\\").append(fileinfo.name), files,format); } } else { files.push_back(p.assign(fileinfo.name)); } }while(_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } }
3)处理指定文本文件的内容,保存为字符串。
这里想特别说的是为了确保上一行的最后一个单词和本行第一个单词分割开来,所以采用一行一行读入,并在行末加空格再连接。
/* ----实现读取指定文件的功能-----*/ void readtxt(string filename) { ifstream file; file.open(filename.c_str());//注意一定要转化为 char * string s; while(getline(file, s))//按行读取 { str=s+' '+str;//加空格确保分割开行尾和行首的两个单词 } transform(str.begin(), str.end(), str.begin(), ::tolower);//将大写转化为小写 file.close(); //关闭文件 }
4)切割字符串并且统计词频。
我在看到统计词频时首先想到的就是用map,这样就可以用键和值来储存相应的词和词频。然后处理字符串的时候,顺便把第一字符是数字的筛选掉。
nu是处理N的函数,基本构造和处理路径名的一样,会返回一个bool值,然后如果有数字就把数值保存在全局变量number1中。
当输入有N时,需要对词频排序,但是map默认的是对键排序,所以这里我把map里的值和键放在vector中,再用sort排序。
这个思路来自 :https://blog.csdn.net/qq_26399665/article/details/52969352
第一次测试这个功能时发现输出格式不整齐,便对输出格式做了规范。借鉴自:https://blog.csdn.net/wolinxuebin/article/details/7490113
9/20 日晚做修改:发现功能一的要求是按输入顺序输出词频便做了一下修改。用vector来记录输入的合法字符串数组,用另一个map来记录是否访问过。
/* ----实现分割字符串并进行字频统计的功能----*/ void cutwords() { bool nu = getnumber();//判断有没有数字限制 map<string, long> word_count; bool temp=false; //读取一个数据标志位 string word; string b; vector<string> vec; for (long i=0;i<str.length();i++) { while(str[i]>='0'&&str[i]<='9'||str[i]>='a'&&str[i]<='z') { temp=true; b+=str[i]; i++; } if(temp) { word=b; if(word[0]>'9'||word[0]<'0') //判断第一个字符是不是数字 { ++word_count[word]; vec.push_back(word); } b=""; word=""; temp=false; } } map<string,bool> vis;//是否访问过这个字符串 if(!nu&&!pa&&na)//只输入文件名时要按照输入顺序输出词频 { cout<<"total "<<word_count.size()<<endl; for(long i=0; i<vec.size();i++) { string now = vec[i]; if( !vis.count( now ) ) { cout<<left<<setw(10)<<vec[i]<<word_count[vec[i]]<<endl; vis[now] = true; } } } else if(!nu)//如果没有数字 { cout<<"total "<<word_count.size()<<" words"<<endl; for(map<string,long>::iterator it=word_count.begin() ;it!=word_count.end();it++) cout<<left<<setw(20)<<it->first<<it->second<<endl;//输出格式为左对齐,宽度为20 } else //如果有数字将map的键和值存放在一个pair类型的vector中,用sort排序 { cout<<"Total words is "<<word_count.size()<<endl; cout<<"--------------------------"<<endl; vector<PAIR> word_count_vec(word_count.begin(), word_count.end()); //对vector排序 sort(word_count_vec.begin(), word_count_vec.end(), CmpByValue()); for (long i=0;i<number1;i++) cout << left << setw(20) << word_count_vec[i].first << word_count_vec[i].second << endl; } }
5)主函数,负责调用各个模块,控制流程。
在主函数中对只有文件名,只有文件路径和两者都有的不同输入进行了处理。需要注意的一点是在输入时如果用cin会导致遇到空格便停止,所以我使用getline来进行输入。
除此之外,本程序存在一点小bug,就是之前在测试的时候如果最后不输入空格,会出现乱码现象,所以我在inputstr后面自行加了一个空格,这样不会影响程序使用,也不会影响用户的输入。
/*-----主函数-------*/ int main() { string allname;//(路径)+文件名的字符串 getline(cin,inputstr);//读取输入(确保空格也读入) inputstr=inputstr+" ";//不在最后加空格会乱码(这是本程序的小bug) pa = getfilepath();/* 获取文件路径*/ na = getfilename();/* 获取文件名*/ if(!pa&&na)//如果只有文件名没有路径 { allname=file_name;//就默认是相同目录下的文件 } else if(!na&&pa)//如果只有路径没有文件字 { vector<string> files; string format = ".txt";//选择文件类型 GetAllFormatFiles(path_name, files,format);//获取路径下的所有该类型的文件 sort(files.begin(),files.end(),cmp);//将文件名按字典序排序 allname=path_name+"\\"+files[0]; //将排序第一的文件名赋给字符串 } else if(na&&pa) { allname=path_name+"\\"+file_name; } readtxt(allname);//读文件 cutwords(); //切割字符串并统计词频 getchar(); //防止启动exe文件完成计算后闪退 return 0; }
四、测试阶段:
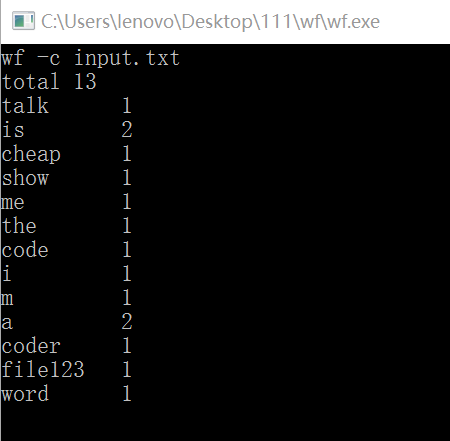
1)样例测试:(测试文件中共有17个词)
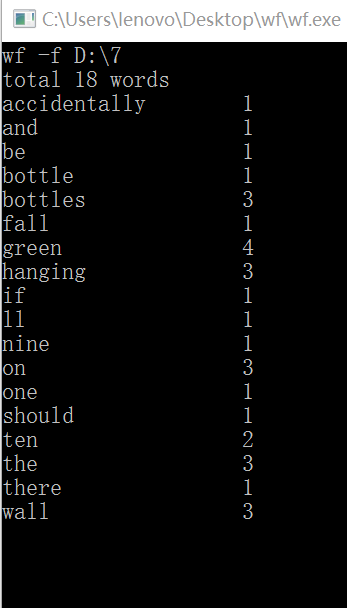
2)诗歌测试:(测试文件中共有32个词)
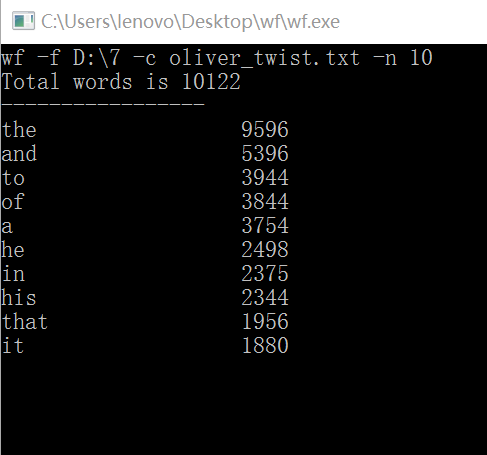
3)长篇英文小说测试:
3.1 《雾都孤儿》全篇157898个单词
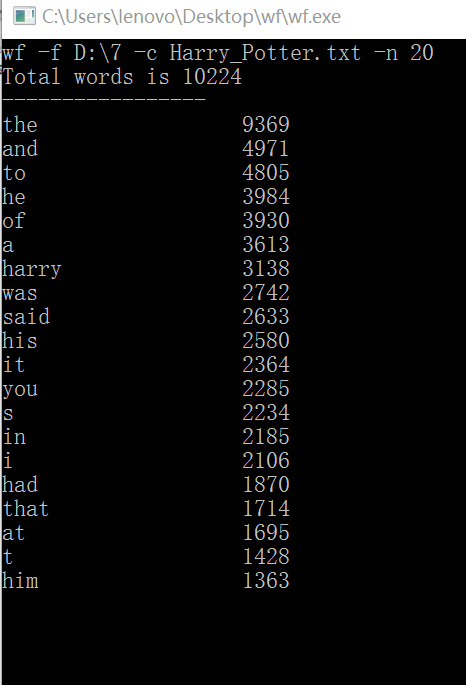
3.2《哈利波特和火焰杯》全篇198919个单词
五、PSP阶段表格:
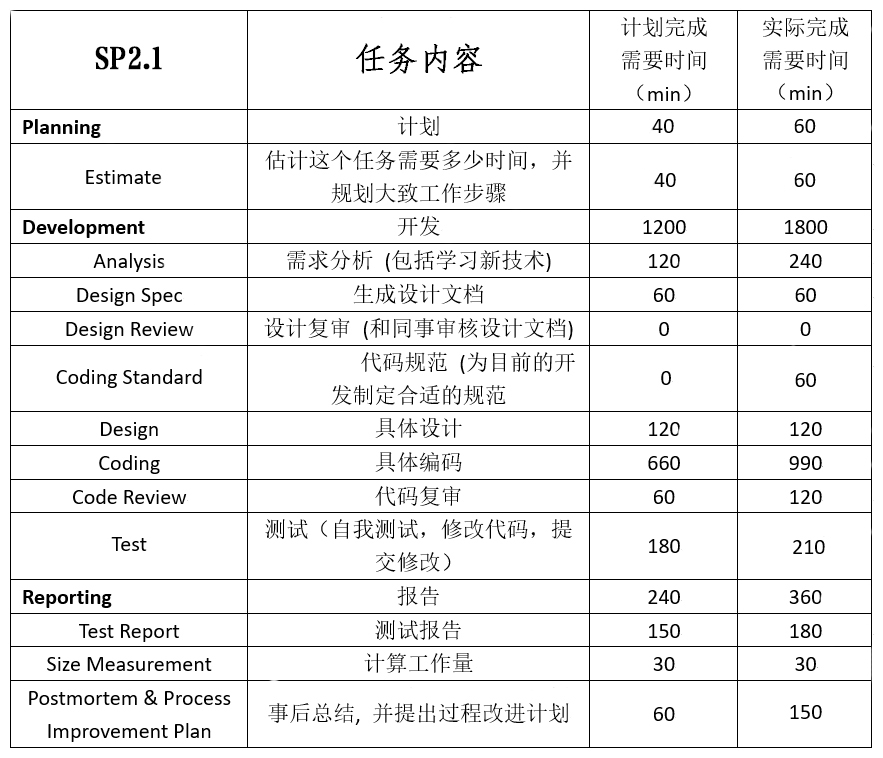

六、总结反思
这次的项目用时还是很长的,主要原因在于对语言运用的不够熟练,在本次作业中需要用到很多c++的stl,比如处理输出格式输入格式的,比如读取文件的等等。分析完功能后在设计函数时为了传递数据更简便,所以定义了一些全局变量,但是在最后复查代码的时候发现这样增加了函数之间的耦合性,不利于模快化,最后做了一些修改,但有些地方由于个人水平有限没能完全改完,日后会再思考如何优化的。
做完作业要求的功能后,我自己也有一些想法,既然已经做完词频分析,其实还可以增添一些数据可视化,比如按词频高低做成词云图,或者做个折线图。之前听到过有人用词频分析的方法辨别《红楼梦》的前八十回和后四十回不是同一个人写的,觉得这次的作业多加完善其实也可以实现类似的功能。
只是做词频分析感觉用c或者java都可以,学过python之后觉得它的第三方库也有很大作用,比如做语义分析的jieba库对中文有着很强大的分词能力,所以之后完善项目做中文词频分析时会用python来做。
结合《构建之法》的第三章中初级软件工程师如何成长来谈谈我的看法吧。书上说第一点是“积累软件开发相关的知识”,这个是我现在最应该做的,毕竟下面几点积累经验,提升职业技能之类的成长在现在所处环境内有点难以实现。提升技术技能的话应该从语言入手,在项目中练手。不论是c/c++ 、java还是python 都各有优缺,学习完基本语法,就应该找一个相应的项目或者需求去实现一下,在这个实现的过程中才会体现出自己不理解的地方,不懂的地方,诚如老话所言“实践是检验真理的唯一标准”。
再加一句反思吧,认真审题。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号