160413.神经网络处理器
陈云霁
http://novel.ict.ac.cn/ychen/
陈云霁,男,1983年生,江西南昌人,中国科学院计算技术研究所研究员,博士生导师。同时,他担任了中国科学院脑科学卓越中心特聘研究员,以及中国科学院大学岗位教授。目前他带领其实验室,研制寒武纪系列深度学习处理器。在此之前,他从事国产处理器的研发工作十余年,先后负责或参与了多款龙芯处理器的设计。他在包括ISCA、HPCA、MICRO、ASPLOS、ICSE、ISSCC、Hot Chips、IJCAI、FPGA、SPAA、IEEE Micro以及8种IEEE/ACM Trans.在内的学术会议及期刊上发表论文60余篇。陈云霁获得了首届国家自然科学基金“优秀青年基金”、首届国家万人计划“青年拔尖人才”、中国计算机学会青年科学家奖以及中科院青年人才奖。他还作为负责人带领科研团队获得了全国“青年文明号”和中央国家机关“青年文明号”的称号。
智能应用
- 智能处理是核心的问题
- 20w人脑功耗
- 多层大规模神经网络 ≈ 卷积神经网络 + LRM(不同的feature map提取不同的特征,来完成归一化) + Pooling(降采样) + Classifier(全联通,2-3层)
- DeepMind:深度学校+增强学习 => 49个小游戏
神经网络处理器的需求
- Google Cat:1.6万CPU × 7天 = 猫脸识别任务
- 1000亿突触(Google Brain) => 100万亿突触
专门的神经网络处理器
- 每个计算机需要一个专用神经网络处理器
寒武纪2008-2016
- 体系结构的方法来完成神经网络的计算
- 2012:成果
可以用CPU(Xeon E5-4620)和GPU(K20M)十分之一的面积,分别达到CPU-117倍,GPU-1.1倍的性能。 - 2013:首个深度学习处理器 - DianNao
传统的神经网络芯片的做法是把硬件运算单元和算法神经元一一对应起来,这样一来只能对一个固定的神经网络进行计算。他们采用了对小尺度神经网络分时复用的方法来支持任意规模的神经网络,这个做法很厉害,极大地提高了芯片对于不同算法的能力。 - 2014:多核深度学习处理器 - DaDianNao
- 2015:通用机器学习处理器 - PuDianNao - (人工神经网络,k-NN,SVM,Bayes等)
- 2016:摄像头上的智能识别IP - ShiDianNao
- 2016:神经网络通用指令集 - DianNaoYu
方法革新
- 固化小尺度硬件 => 任意大可变神经网络
- 优化存储层次尽量减少访问内存的次数
- 提高访存带宽
硬件运算单元的分时复用
- DianNao:小范围神经元的依次解算

- DaDianNao:
- EDRAM技术
- 神经网络计算规整,因此可以通过调度来提高效率
- 相比于K20,速度提升21倍
- 在28nm工艺下,DaDianNao的主频为606MHz,面积67.7mm^2,功耗约16W。单芯片性能超过了主流GPU的21倍,而能耗仅为主流GPU的1/330。64芯片组成的高效能计算系统较主流GPU的性能提升甚至可达450倍,但总能耗仅为1/150。
- 缺点:1. EDRAM在28nm留片成功,但7nm工艺出现困难。(晶体管漏电) 2. 全连接网络,意味着芯片之间也需要数据之间的全沟通。因此设计方面有些缺陷。
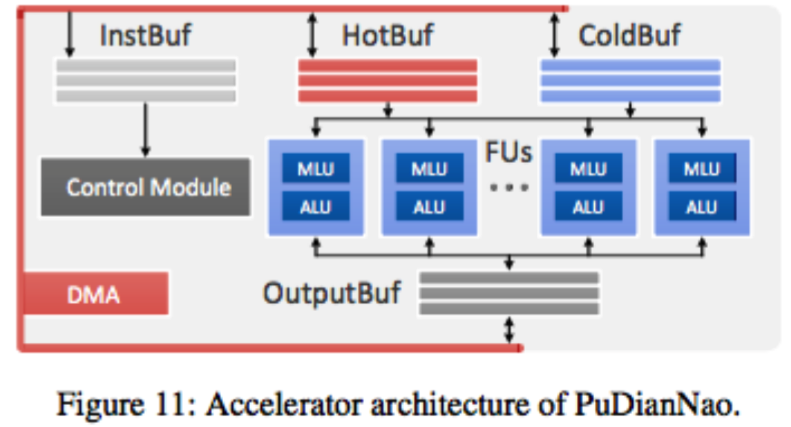
PuDianNao
- 小样本学习方法 -Bayes方法(大样本的学习方法不是万能药)
- 经济学方面也无法使用大样本
- 算法自身的演进,意味着硬件芯片具有很强的通用性
- 向量内积(SVM)、向量距离、计数、非线性函数、排序 => 95%机器学习算法涉及到的运算 => 设计了MLU(机器学习功能部件)
ShiDianNao
- 输入输出和系统模型都在芯片上而不需要范围内存
- 本质上还是冯 诺依曼结构

- 手机里的超级计算机


类脑计算机与风诺依曼结构
- 硬件的通用性架构,类脑计算机并不是本质上的突破
e-mail: kongww.nudt [AT] gmail.com
WeChat/QQ: 40804097

 浙公网安备 33010602011771号
浙公网安备 33010602011771号