


C语言刷leetcode——并查集
目录
概述
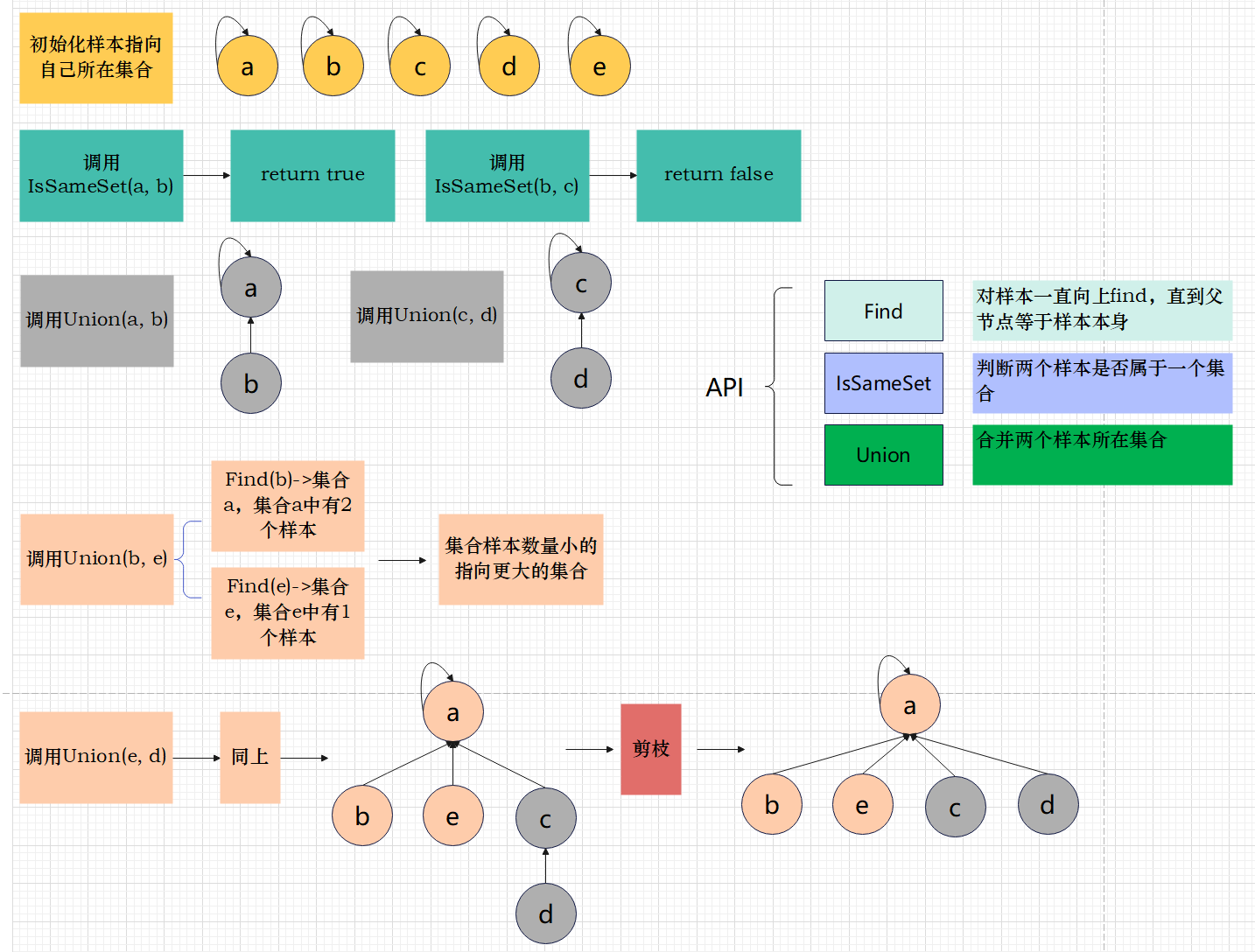
并查集的2个功能
- 查: 查询两个样本是否在一个集合
- 并: 合并两个样本所在的集合
需要把1和2两个功能都尽可能快,因此需要选择合适的数据结构:向上指的图结构
- 举个例子
有一堆元素,a, b, c, d, e,把它们划分成若干个集合:{a} {b} {c} {d} {e}
对应的需要有两个API:
bool IsSameSet(a, b);
void Union(a, b);
并查集的数据结构
3张表
0. 基本元素(样本)
-
样本对应样本自己所在的集合
-
样本对应父样本所在集合
-
样本所在集合的大小
并查集实现步骤
-
初始化
-
实现Find
-
迭代
-
递归
...
-
实现IsSameSet
-
实现Union
刷题
模板题: 200. 岛屿数量
int *g_parent;
int *g_size;
int g_count;
int g_dir[4][2] = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
/* 初始化:
* 1. 申请内存;
* 2. 对每个样本建立指向自己的集合
*/
void Init(int n)
{
g_count = n;
g_parent = calloc(n, sizeof(int));
g_size = calloc(n, sizeof(int));
for (int i = 0; i < n; i++) {
g_parent[i] = i; // 自己是自己的head
g_size[i] = 1; // 自己所在集合数量初始值都为1
}
}
/* 1. 找到并返回样本a所在集合的head样本值
* 2. 路径压缩
*/
// int FindHead(int a)
// {
// if (g_parent[a] != a) {
// g_parent[a] = FindHead(g_parent[a]);
// }
// return g_parent[a];
// }
#if 1
// 非递归写法
int FindHead(int a)
{
int i = 0;
while (g_parent[a] != a) {
// printf("i=%d\n", ++i);
g_parent[a] = g_parent[g_parent[a]];
a = g_parent[a];
}
return g_parent[a];
}
#endif
/* 合并
*/
void Union(int a, int b)
{
int headA = FindHead(a);
int headB = FindHead(b);
if (headA == headB) {
return;
}
// 小的挂在大的下面
if (g_size[headA] > g_size[headB]) {
g_parent[headB] = headA;
g_size[headA] += g_size[headB];
g_size[headB] = 0;
} else {
g_parent[headA] = headB;
g_size[headB] += g_size[headA];
g_size[headA] = 0;
}
g_count--;
}
int numIslands(char** grid, int gridSize, int* gridColSize)
{
int i, j;
int n = gridSize;
int m = gridColSize[0];
Init(m * n + 1);
int zero = m * n;
for (i = 0; i < n; i++) {
for (j = 0; j < m; j++) {
// 所有0合并为一个集合
if (grid[i][j] == '0') {
Union(i * m + j, zero); // 注意是乘以列数
continue;
}
// 相连的1合并为一个集合
for (int k = 0; k < 4; k++) {
int nextX = i + g_dir[k][0];
int nextY = j + g_dir[k][1];
if (nextX >= 0 && nextX < n && nextY >= 0 && nextY < m && grid[nextX][nextY] == '1') {
Union(nextX * m + nextY, i * m + j);
}
}
}
}
int res = g_count - 1;
free(g_parent);
free(g_size);
return res;
}
入门题: 547. 省份数量(朋友圈)
-
dfs
-
bfs
-
并查集
684. 冗余连接
1135. 最低成本联通所有城市(Plus)
- 题目

int *g_parent;
int *g_size;
int g_count;
int g_cost;
int Cmp(const void *a, const void *b)
{
int *a1 = *(int **)a;
int *b1 = *(int **)b;
return a1[2] > b1[2];
}
void MemInit(int n)
{
g_parent = calloc(n + 1, sizeof(int));
g_size = calloc(n + 1, sizeof(int));
g_count = n - 1;
g_cost = 0;
}
void Init(int n)
{
MemInit(n);
for (int i = 0; i < n; i++) {
g_parent[i] = i;
g_size[i] = 1;
}
}
int FindHead(int x)
{
if (g_parent[x] != x) {
g_parent[x] = FindHead(g_parent[x]);
}
return g_parent[x];
}
bool IsSameSet(int a, int b)
{
return FindHead(a) == FindHead(b);
}
void Union(int a, int b)
{
int headA = FindHead(a);
int headB = FindHead(b);
if (headA == headB) {
return;
}
if (g_size[headA] > g_size[headB]) {
g_parent[headB] = headA;
g_size[headA] += g_size[headB];
g_size[headB] = 0;
} else {
g_parent[headA] = headB;
g_size[headB] += g_size[headA];
g_size[headA] = 0;
}
}
int minimumCost(int n, int** connections, int connectionsSize, int* connectionsColSize)
{
Init(n);
// 按照cost由小到大排序
qsort(connections, connectionsSize, sizeof(int *), Cmp);
for (int i = 0; i < connectionsSize; i++) {
int x = connections[i][0];
int y = connections[i][1];
int cost = connections[i][2];
// printf("x=%d, y=%d, const=%d\n", x, y, cost);
if (!IsSameSet(x, y)) {
Union(x, y);
g_count--;
g_cost += cost;
}
}
if (g_count == 0) {
return g_cost;
}
return -1;
}
句子相似性II (737_会员)
#define MAX_MEM_SIZE 2000
#define MAX_STR_LEN 21
int *g_parent;
int *g_size;
int g_id;
/* hash : 建立字符串和id的映射关系,操作id相当于操作字符串 */
typedef struct {
char key[MAX_STR_LEN];
// char value[MAX_STR_LEN]; 不要直接写字符串,将字符串的映射转换为int更简单
int id;
UT_hash_handle hh;
} HashTable;
HashTable *g_hash;
void MemInit()
{
g_parent = malloc(sizeof(int) * MAX_MEM_SIZE);
memset(g_parent, -1, sizeof(int) * MAX_MEM_SIZE);
g_size = malloc(sizeof(int) * MAX_MEM_SIZE);
memset(g_size, -1, sizeof(int) * MAX_MEM_SIZE);
g_id = 0;
g_hash = NULL;
}
void FreeMem()
{
HashTable *cur, *next;
HASH_ITER(hh, g_hash, cur, next) {
HASH_DEL(g_hash, cur);
free(cur);
}
free(g_parent);
free(g_size);
g_id = 0;
}
HashTable *FindHash(const char * str)
{
HashTable *tmp = NULL;
HASH_FIND_STR(g_hash, str, tmp);
return tmp;
}
/* 建立字符串与id的映射,并返回id */
int AddHash(const char *str)
{
HashTable *tmp = FindHash(str);
if (tmp == NULL) {
tmp = malloc(sizeof(HashTable));
strcpy(tmp->key, str);
tmp->id = g_id++;
HASH_ADD_STR(g_hash, key, tmp);
}
return tmp->id;
}
int FindHead(int id)
{
while (g_parent[id] != -1) {
id = g_parent[id];
}
return id;
}
bool IsSameSet(int id1, int id2)
{
if (id1 == id2) {
return true;
}
return FindHead(id1) == FindHead(id2);
}
void Union(int id1, int id2)
{
int head1 = FindHead(id1);
int head2 = FindHead(id2);
if (head1 == head2) return;
if (g_size[head1] > g_size[head2]) {
g_parent[head2] = head1;
g_size[head1] += g_size[head2];
g_size[head2] = 0;
} else {
g_parent[head1] = head2;
g_size[head2] += g_size[head1];
g_size[head1] = 0;
}
}
void ConnectPair(const char *** similarPairs, int similarPairsSize)
{
for (int i = 0; i < similarPairsSize; i++) {
int id1 = AddHash(similarPairs[i][0]);
int id2 = AddHash(similarPairs[i][1]);
Union(id1, id2);
}
}
bool areSentencesSimilarTwo(char ** sentence1, int sentence1Size, char ** sentence2, int sentence2Size, char *** similarPairs, int similarPairsSize, int* similarPairsColSize)
{
if (sentence1Size != sentence2Size) return false;
MemInit();
ConnectPair(similarPairs, similarPairsSize);
for (int i = 0; i < sentence1Size; i++) {
int id1 = AddHash(sentence1[i]);
int id2 = AddHash(sentence2[i]);
if (!IsSameSet(id1, id2)) {
FreeMem();
return false;
}
}
FreeMem();
return true;
}
得分最高的路径(1102_会员)

#define MAX_NUM 10001
const int dir[4][2] = {{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
typedef struct {
int x;
int y;
int val;
} Pair;
int parent[MAX_NUM];
int size[MAX_NUM];
void InitUnion(int n)
{
for (int i = 0; i < n; i++) {
parent[i] = i;
size[i] = 1;
}
}
int FindHead(int x)
{
if (parent[x] != x) {
parent[x] = FindHead(parent[x]);
}
return parent[x];
}
bool IsSameSet(int a, int b)
{
// printf("FindHead(a)=%d, FindHead(b)=%d\n", FindHead(a), FindHead(b));
return FindHead(a) == FindHead(b);
}
void Union(int a, int b)
{
int pA = FindHead(a);
int pB = FindHead(b);
if (pA == pB) {
return;
}
// 小的挂在大的下面
if (size[pA] > size[pB]) {
parent[pB] = pA;
size[pA] += size[pB];
size[pB] = 0;
} else {
parent[pA] = pB;
size[pB] += size[pA];
size[pA] = 0;
}
}
int Cmp(const void *a, const void *b)
{
Pair *pa = (Pair *)a;
Pair *pb = (Pair *)b;
if (pa->val == pb->val) {
return (pb->x + pb->y) - (pa->x + pa->y);
}
return pb->val - pa->val;
}
void InitNums(int *nums, int len, int val)
{
for (int i = 0; i < len; i++) {
nums[i] = val;
}
}
int maximumMinimumPath(int** grid, int gridSize, int* gridColSize)
{
int i, j;
int row = gridSize;
int col = gridColSize[0];
int len = row * col;
InitUnion(MAX_NUM);
int idx = 0;
Pair arr[len]; // 用来存grid中坐标与数值的映射关系,后面排序后使用
for (i = 0; i < row; i++) {
for (j = 0; j < col; j++) {
Pair p;
p.x = i;
p.y = j;
p.val = grid[i][j];
arr[idx++] = p;
}
}
qsort(arr, len, sizeof(Pair), Cmp); // 从大到小进行排序
int min = fmin(grid[0][0], grid[row - 1][col - 1]);
int visited[len];
InitNums(visited, len, 0);
// 要先把起点和终点标记为访问过
visited[0] = 1;
visited[row * col - 1] = 1;
idx = 0;
// 如果在遍历arr的过程中,把起点和终点合并为了一个集合,说明找到了合适的路径,返回结果
while (!IsSameSet(0, row * col - 1)) {
Pair p = arr[idx++];
visited[p.x * col + p.y] = 1; // 标记访问过了
// printf("p.val=%d, min=%d\n", p.val, min);
min = fmin(p.val, min);
for (int d = 0; d < 4; d++) {
int nextX = p.x + dir[d][0];
int nextY = p.y + dir[d][1];
if (nextX >= 0 && nextX < row && nextY >= 0 && nextY < col) {
if (visited[nextX * col + nextY] == 1) {
Union(p.x * col + p.y, nextX * col + nextY);
}
}
}
}
return min;
}
最低成本联通所有城市(1135_会员)
以图辨树(261_会员)
按字典序排列最小的等效字符串(1061_会员)
无向图中连通分量的数目(323_会员)
尽量减少恶意软件的传播(924_困难)
参考链接:
https://zhuanlan.zhihu.com/p/417587917
https://blog.csdn.net/weixin_54186646/article/details/124477838
标签:
纯c刷leetcode记录


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)