

(三)目标检测算法之SPPNet
今天准备再更新一篇博客,加油呀~~~
系列博客链接:
(一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html
(二)目标检测算法之R-CNN https://www.cnblogs.com/kongweisi/p/10895055.html
本篇博客概述:
1、SPPNet的特点
1.1、映射(减少卷积计算、防止图片内容变形)
1.2、spp层:空间金字塔层(将大小不同的图片转换成固定大小的图片)
2、SPPNet总结
完整结构+优缺点总结
引言:
前面介绍的R-CNN的速度慢在哪里?
答:每个候选区都要进行卷积操作提取特征。因此,SPPnet孕育而生。
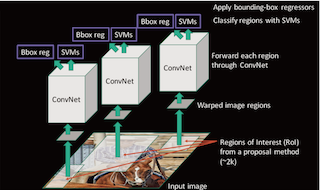
1、 SPPNet
SPPNet提出了SPP层,主要改进了以下两个方面:
- 减少卷积计算
- 防止图片内容变形
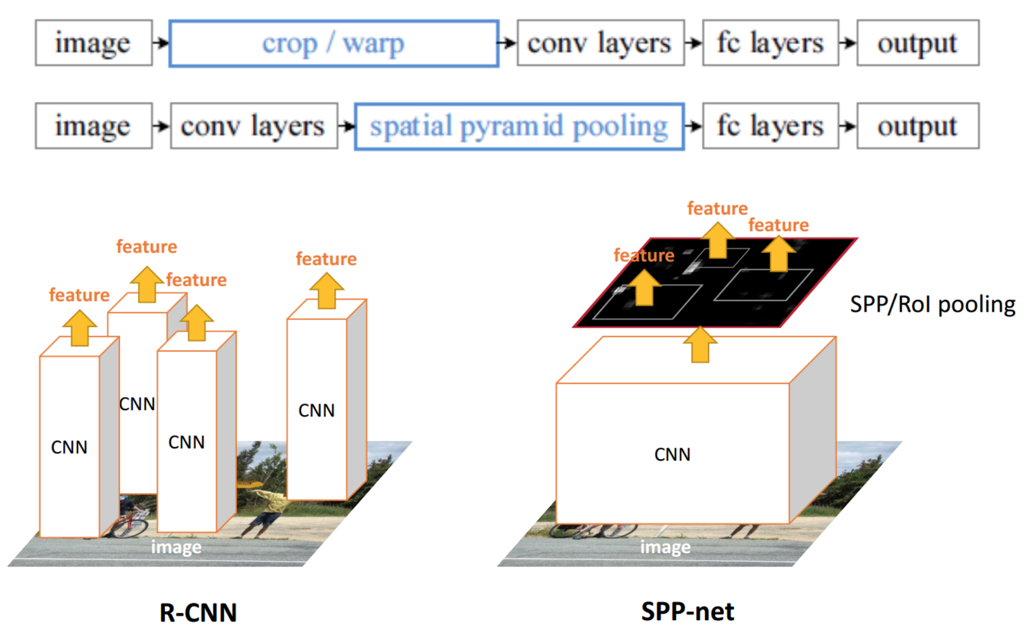
图1 R-CNN与SPPNet
图1中第一行代表R-CNN的检测过程,第二行是SPPNet的。输入进R-CNN卷积层的图像必须固定大小,因此要进过crop/warp,这会使原图片变形。
而SPPNet直接将原图片输入CNN中,获其特征,使得原图片内容得以保真。
| R-CNN模型 | SPPNet模型 |
|---|---|
| 1、R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 2、固定大小的图像塞给CNN 传给后面的层做训练回归分类操作 | 1、SPPNet把全图塞给CNN得到全图的feature map 2、让候选区域与feature map直接映射,得到候选区域的映射特征向量 3、映射过来的特征向量大小不固定,这些特征向量塞给SPP层(空间金字塔变换层),SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层 |
1.1 映射
原始图片经过CNN变成了feature map,原始图片通过选择性搜索(SS)得到了候选区域,现在需要将基于原始图片的候选区域映射到feature map中的特征向量。
映射过程图参考如下:
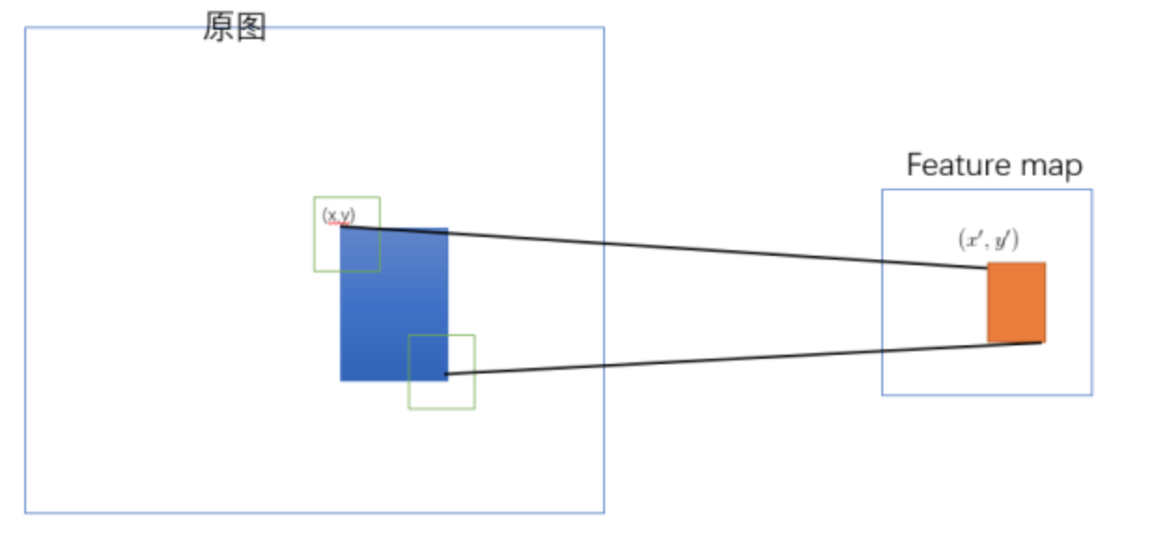
整个映射过程有具体的公式,如下
假设(x′,y′)(x′,y′)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关系与网络结构有关:(x,y)=(S∗x′,S∗y′),即
-
左上角的点:
- x′=[x/S]+1
-
右下角的点:
- x′=[x/S]−1
其中 SS 就是CNN中所有的strides的乘积,包含了池化、卷积的stride。论文中使用S的计算出来为=16
原论文链接,其中有公式的推导过程 http://kaiminghe.com/iccv15tutorial/iccv2015_tutorial_convolutional_feature_maps_kaiminghe.pdf
1.2 spatial pyramid pooling (空间金字塔变换层)
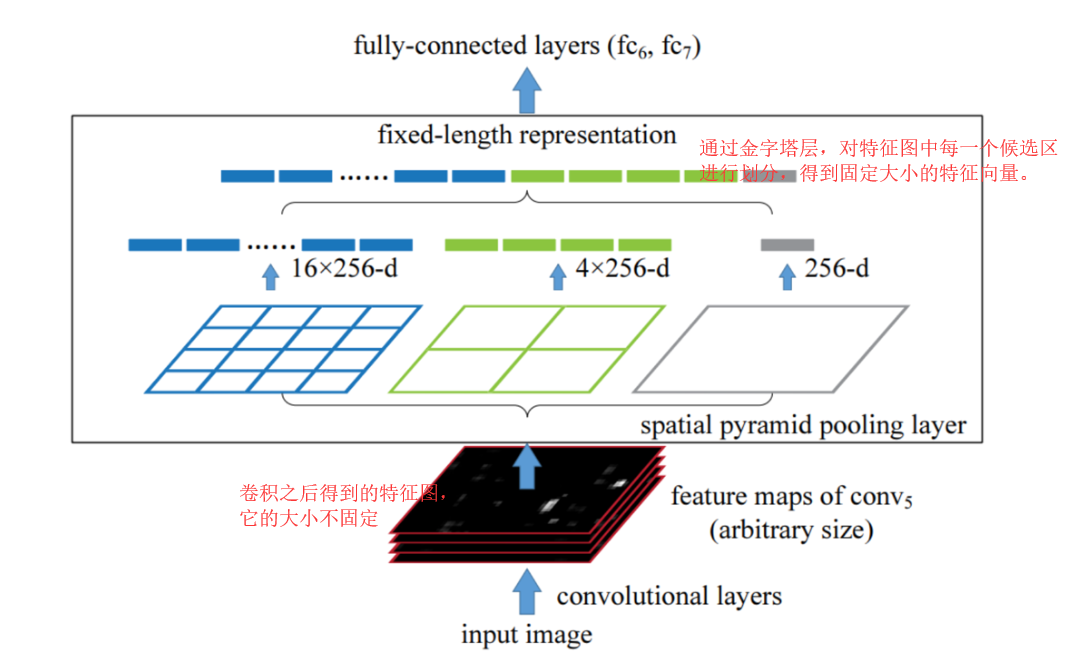
通过spatial pyramid pooling 将任意大小的特征图转换成固定大小的特征向量
示例:假设原图输入是224x224,对于conv出来后的输出是13x13x256的,可以理解成有256个这样的Filter,每个Filter对应一张13x13的feature map。
接着在这个特征图中找到每一个候选区域映射的区域,spp层会将每一个候选区域分成1x1,2x2,4x4三张子图,对每个子图的每个区域作max pooling,
得出的特征再连接到一起,就是(16+4+1)x256的特征向量,接着给全连接层做进一步处理,如下图:
2、 SPPNet总结
来看下SPPNet的完整结构
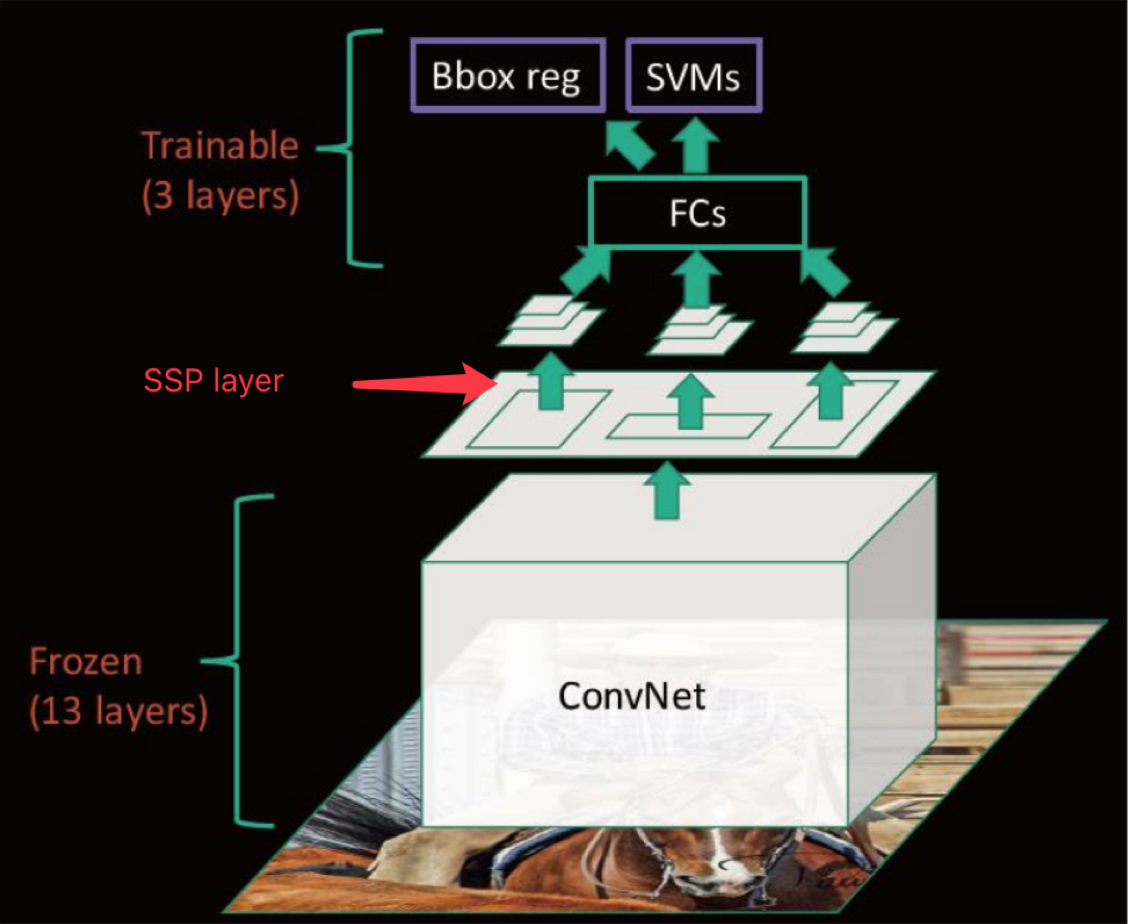
- 优点
- SPPNet在R-CNN的基础上提出了改进,通过候选区域和feature map的映射,配合SPP层的使用,从而达到了CNN层的共享计算,减少了运算时间, 后面的Fast R-CNN等也是受SPPNet的启发
- 缺点
- 训练依然过慢、效率低,特征需要写入磁盘(因为SVM的存在)
- 分阶段训练网络:选取候选区域、训练CNN、训练SVM、训练bbox回归器, SPP-Net在fine-tuning阶段无法使用反向传播微调SPP-Net前面的Conv层

 浙公网安备 33010602011771号
浙公网安备 33010602011771号